
Еще одна статья-ревью по нейронному рендерингу и нерфам-шмерфам
Я уже писал об одной такой статье тут. Прочитав обе, вы точно станете экспертами в области (ну, или почти 😃).
Ребята также запилили поиск по 255 статьям о нейронном рендеринге у себя на сайте. Можно поискать перед тем, как заниматься бесполезным ресерчем в каком-то направлении.
Статья
Я уже писал об одной такой статье тут. Прочитав обе, вы точно станете экспертами в области (ну, или почти 😃).
Ребята также запилили поиск по 255 статьям о нейронном рендеринге у себя на сайте. Можно поискать перед тем, как заниматься бесполезным ресерчем в каком-то направлении.
Статья
Forwarded from DL in NLP (nlpcontroller_bot)
Hidden Technical Debt in Machine Learning Systems
Sculley et al., [Google], 2015
Несмотря на возраст, статья точно описывает кучу проблем в современных системах. В отличие от обычного софта, когда технический долг весь сидит в коде или документации, в ML есть много альтернативных способов накосячить. Вот некоторые примеры, которые авторы разбирают в статье на основе своего опыта в Google:
1. Старые гиперпараметры, которые непонятно откуда взялись, и не меняются уже N лет, несмотря на то, что и данные и модель уже сильно другие
1. Частный случай предыдущего пункта — трешхолды, которые были потюнены лишь один раз во время первичного деплоя. Это может быть особенно опасно, если ваша система принимает важные для бизнеса или безопасности окружающих решения.
1. Feedback loops — данные для тренировки модели, которые вы коллектите с задеплоеной системы, зависят от модели. Про это нужно помнить и адресовать заранее.
1. Высокоуровневые абстракции над моделями, которые заставляют писать кучу glue code (бывает так что > 90% всего вашего кода это glue code)
1. Рipeline jungles, когда никто не понимает data flow и коммуникация между кусками системы превращается в макароны
1. Предыдущие два пункта зачастую появляются из-за того, что код модели написан рисечерами и его абстракции не подходят для реального мира. Чаще всего лучший способ этого избежать — переписать код модели с нуля.
1. Ещё одно следствие — куча экспериментального кода внутри задеплоеного кода
1. Под конец касаются интересной вещи, которую называют cultural debt. Хорошие ML команды состоят из смеси исследователей и инжереров, которые активно взаимодействуют друг с другом, готовы выкидывать старые куски кода для упрощения системы, обращать столько же внимания на стабильность и мониторинг системы, сколько и на accuracy. Если в команде нету такой культуры, она может быть склонна быстро аккумулировать и преувеличивать существующий техдолг.
Советую почитать оригинальную статью. В ней очень много полезной информации, которую не сжать в пост в телеге.
Sculley et al., [Google], 2015
Несмотря на возраст, статья точно описывает кучу проблем в современных системах. В отличие от обычного софта, когда технический долг весь сидит в коде или документации, в ML есть много альтернативных способов накосячить. Вот некоторые примеры, которые авторы разбирают в статье на основе своего опыта в Google:
1. Старые гиперпараметры, которые непонятно откуда взялись, и не меняются уже N лет, несмотря на то, что и данные и модель уже сильно другие
1. Частный случай предыдущего пункта — трешхолды, которые были потюнены лишь один раз во время первичного деплоя. Это может быть особенно опасно, если ваша система принимает важные для бизнеса или безопасности окружающих решения.
1. Feedback loops — данные для тренировки модели, которые вы коллектите с задеплоеной системы, зависят от модели. Про это нужно помнить и адресовать заранее.
1. Высокоуровневые абстракции над моделями, которые заставляют писать кучу glue code (бывает так что > 90% всего вашего кода это glue code)
1. Рipeline jungles, когда никто не понимает data flow и коммуникация между кусками системы превращается в макароны
1. Предыдущие два пункта зачастую появляются из-за того, что код модели написан рисечерами и его абстракции не подходят для реального мира. Чаще всего лучший способ этого избежать — переписать код модели с нуля.
1. Ещё одно следствие — куча экспериментального кода внутри задеплоеного кода
1. Под конец касаются интересной вещи, которую называют cultural debt. Хорошие ML команды состоят из смеси исследователей и инжереров, которые активно взаимодействуют друг с другом, готовы выкидывать старые куски кода для упрощения системы, обращать столько же внимания на стабильность и мониторинг системы, сколько и на accuracy. Если в команде нету такой культуры, она может быть склонна быстро аккумулировать и преувеличивать существующий техдолг.
Советую почитать оригинальную статью. В ней очень много полезной информации, которую не сжать в пост в телеге.
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
Машинное обучение: Δwₘₙ = −α ∂E/∂wₘₙ
Ребёнок:
4 часа игры ребёнка за 2 минуты. Поразительная аналогия с нейронными сетями. Я насчитал 4 полные эпохи. А вы говорите, что роботы медленно учатся...
Ребёнок:
4 часа игры ребёнка за 2 минуты. Поразительная аналогия с нейронными сетями. Я насчитал 4 полные эпохи. А вы говорите, что роботы медленно учатся...
Forwarded from Метаверсище и ИИще (Sergey Tsyptsyn)
This media is not supported in your browser
VIEW IN TELEGRAM
Рено отжигает.
"AIR4 – это символ независимости и свободы. В основе идеи его создания лежит осознание двух простых истин: дорожный трафик мешает комфортной жизни, а над нашей головой нет никаких препятствий. Поэтому AIR4 заявляет: небо – это альтернатива дорогам будущего.
AIR4 питается от литий-полимерных аккумуляторов емкостью 22 000 мА·ч, вырабатывающих общую мощность 90 000 мА·ч. Максимальная горизонтальная скорость автомобиля составляет 26 м/с, наклон во время полета равен 45°, максимальный наклон – 70°. AIR4 способен подниматься на высоту до 700 м, скорость взлета может достигать 14 м/с, но ограничивается значением в 4 м/с по соображениям безопасности, а скорость посадки составляет 3 м/с. Наконец, изменяемая тяга AIR4 равна 380 кг, то есть 95 кг на каждый винт."
Это не концепт: "до конца года AIR4 можно увидеть в живую в Ателье Renault на Елисейских полях"
https://ru.media.renaultgroup.com/news/renault-i-thearsenale-predstavliaiut-air4-tam-kuda-my-idem-ne-nuzhny-dorogi-ce62-9f894.html
"AIR4 – это символ независимости и свободы. В основе идеи его создания лежит осознание двух простых истин: дорожный трафик мешает комфортной жизни, а над нашей головой нет никаких препятствий. Поэтому AIR4 заявляет: небо – это альтернатива дорогам будущего.
AIR4 питается от литий-полимерных аккумуляторов емкостью 22 000 мА·ч, вырабатывающих общую мощность 90 000 мА·ч. Максимальная горизонтальная скорость автомобиля составляет 26 м/с, наклон во время полета равен 45°, максимальный наклон – 70°. AIR4 способен подниматься на высоту до 700 м, скорость взлета может достигать 14 м/с, но ограничивается значением в 4 м/с по соображениям безопасности, а скорость посадки составляет 3 м/с. Наконец, изменяемая тяга AIR4 равна 380 кг, то есть 95 кг на каждый винт."
Это не концепт: "до конца года AIR4 можно увидеть в живую в Ателье Renault на Елисейских полях"
https://ru.media.renaultgroup.com/news/renault-i-thearsenale-predstavliaiut-air4-tam-kuda-my-idem-ne-nuzhny-dorogi-ce62-9f894.html
Датасеты для Vision-and-Language моделей
Поговорим немного о text-image датасетах, которые содержат картинки и текстовые описания к ним. Зачем они нам нужны? Например, для обучения таких моделей как DALL-E (генерит картинку по текстовому описанию), либо CLIP (умеет вычислять похожесть текста и фотографий за счет проецирования текстовых строк и картинок в одно и то же многомерное пространство). Тот же Google Image Search вполне может использовать что-то вроде CLIP для ранжирования картинок исходя из текстового запроса пользователя.
Чтобы натренировать text-to-image модель вроде CLIP, разумеется, нужен дохерильон размеченных данных. Например, OpenAI тренировали CLIP на 400M пар текст-фото, но датасет свой так никому и не показали. Хорошо, что хоть веса моделей выложили на гитхабе. В похожем стиле была натренирована модель DALL-E, выбрали подмножество из 250M пар текст-фото и также никому не показали датасет. Есть подозрение, что боятся копирайта.
Недавно нашумевшая ru-DALL-E (о ней я писал тут) от Сбера был тренировалась на более 120M пар, что приближается к 250M от OpenAI. Сбер использовал всевозможные публичные датасеты. Сначала взяли Сonceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем добавили датасеты OpenImages, LAION-400m, WIT, Web2M, HowTo и щепотку кроулинга интернета, как я понимаю. Все это отфильтровали, чтобы уменьшить шум в данных, а все английские описания были решительно переведены на русский язык. Но, к сожалению, датасет тоже не выложили. Зато опубликовали свою натренированную модельку, в отличие от OpenAI
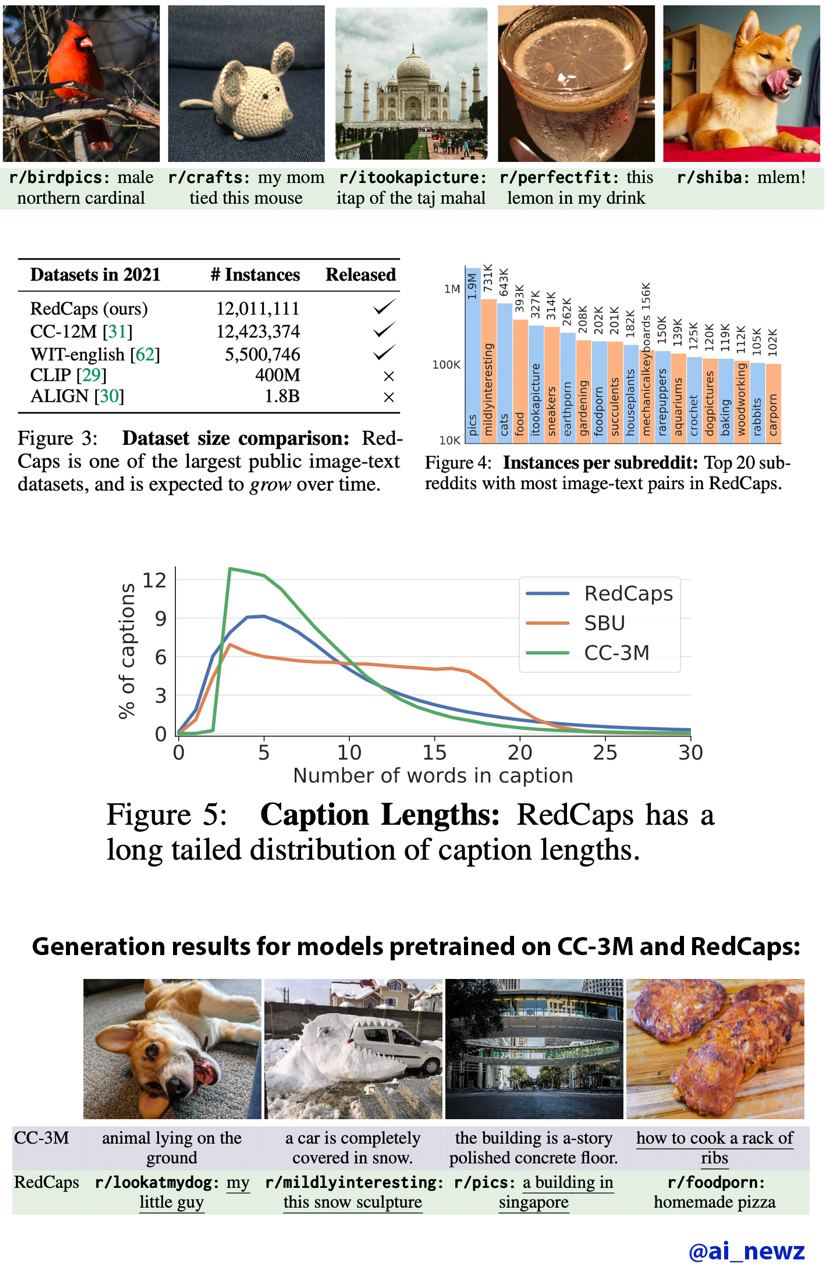
Ещё расскажу о новом датасете RedCaps от Justin Johnson (это имя нужно знать, он крутой молодой профессор) и его студетов из университета Мичигана. Парни попытались найти в интернете новый источник бесплатных аннотаций вида "текст-картинка", который содержал бы меньше мусора по сравнению со скачиванием всего интернета в лоб. Решено было выкачать посты с картинками с Reddit-a, и в качестве аннотаций использовать подпись к картинке и название сабреддита. Названия сабреддитов обычно говорящие и уже сами по себе несут много информации, например, "r/cats", "r/higing", "r/foodporn". После выбора подмножетсва из 350 сабреддитов и небольшой фильтрации вышло 12M пар фото-текст, которые покрывают 13 лет истории Reddit.
На примере этого датасета можно проследить, какакие меры принимаются для уменьшения риска получить повестку в суд после публикации такого огромного количества данных пользователей форума. Все фото с людьми были задетекчены с помощью RetinaNet и нарочито выброшены, а сам датасет опубликовали в виде списка ссылок с анонимизированными текстовыми описаниями (картинки на сайте не хранят). Кроме того, на сайте с датасетом есть форма, где несогласные могут запросить удалить любую ссылку.
В итоге, получился довольно качественный датасет, который превосходит существующие публичные датасеты (кроме LAION-400m, с которым забыли сравниться) для обучения модели генерировать описания по картинке. В качестве ксперимента, обучили Image Captioning модель на разныз датасетах и протестировали на задаче переноса выученной репрезентации на новые датасеты в Zero-Shot сценарии, а также с помощью обучений логистической регрессии поверх фичей (linear probing). Но, конечно обученная учеными из Мичигана модель существенно уступает CLIP по ряду причин: CLIP имеет слегка другую архитектуру (он не генерит текст, а учит эмбеддинги), он толще и жирнее, и тренировали его в 40 раз больше итераций на гигантском датасете, который превосходит в размере RedCaps в 35 раз.
Посмотреть на примеры из RedCaps можно на сайте https://redcaps.xyz/.
Поговорим немного о text-image датасетах, которые содержат картинки и текстовые описания к ним. Зачем они нам нужны? Например, для обучения таких моделей как DALL-E (генерит картинку по текстовому описанию), либо CLIP (умеет вычислять похожесть текста и фотографий за счет проецирования текстовых строк и картинок в одно и то же многомерное пространство). Тот же Google Image Search вполне может использовать что-то вроде CLIP для ранжирования картинок исходя из текстового запроса пользователя.
Чтобы натренировать text-to-image модель вроде CLIP, разумеется, нужен дохерильон размеченных данных. Например, OpenAI тренировали CLIP на 400M пар текст-фото, но датасет свой так никому и не показали. Хорошо, что хоть веса моделей выложили на гитхабе. В похожем стиле была натренирована модель DALL-E, выбрали подмножество из 250M пар текст-фото и также никому не показали датасет. Есть подозрение, что боятся копирайта.
Недавно нашумевшая ru-DALL-E (о ней я писал тут) от Сбера был тренировалась на более 120M пар, что приближается к 250M от OpenAI. Сбер использовал всевозможные публичные датасеты. Сначала взяли Сonceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем добавили датасеты OpenImages, LAION-400m, WIT, Web2M, HowTo и щепотку кроулинга интернета, как я понимаю. Все это отфильтровали, чтобы уменьшить шум в данных, а все английские описания были решительно переведены на русский язык. Но, к сожалению, датасет тоже не выложили. Зато опубликовали свою натренированную модельку, в отличие от OpenAI
Ещё расскажу о новом датасете RedCaps от Justin Johnson (это имя нужно знать, он крутой молодой профессор) и его студетов из университета Мичигана. Парни попытались найти в интернете новый источник бесплатных аннотаций вида "текст-картинка", который содержал бы меньше мусора по сравнению со скачиванием всего интернета в лоб. Решено было выкачать посты с картинками с Reddit-a, и в качестве аннотаций использовать подпись к картинке и название сабреддита. Названия сабреддитов обычно говорящие и уже сами по себе несут много информации, например, "r/cats", "r/higing", "r/foodporn". После выбора подмножетсва из 350 сабреддитов и небольшой фильтрации вышло 12M пар фото-текст, которые покрывают 13 лет истории Reddit.
На примере этого датасета можно проследить, какакие меры принимаются для уменьшения риска получить повестку в суд после публикации такого огромного количества данных пользователей форума. Все фото с людьми были задетекчены с помощью RetinaNet и нарочито выброшены, а сам датасет опубликовали в виде списка ссылок с анонимизированными текстовыми описаниями (картинки на сайте не хранят). Кроме того, на сайте с датасетом есть форма, где несогласные могут запросить удалить любую ссылку.
В итоге, получился довольно качественный датасет, который превосходит существующие публичные датасеты (кроме LAION-400m, с которым забыли сравниться) для обучения модели генерировать описания по картинке. В качестве ксперимента, обучили Image Captioning модель на разныз датасетах и протестировали на задаче переноса выученной репрезентации на новые датасеты в Zero-Shot сценарии, а также с помощью обучений логистической регрессии поверх фичей (linear probing). Но, конечно обученная учеными из Мичигана модель существенно уступает CLIP по ряду причин: CLIP имеет слегка другую архитектуру (он не генерит текст, а учит эмбеддинги), он толще и жирнее, и тренировали его в 40 раз больше итераций на гигантском датасете, который превосходит в размере RedCaps в 35 раз.
Посмотреть на примеры из RedCaps можно на сайте https://redcaps.xyz/.
{kind=link}
Красивая визуализация выхода с лидара нового iPhone 13 Pro. Довольно годная штука этот лидар в айфонах. Он разблочил очень много CV приложений, для которых нужна глубина.
Telegram
CGIT_Vines
Шибуя стрит, снятая на Iphone13 pro max.
Дальность лидаров, к сожалению, ограничена 5 метрами и это не риалтайм.
Но в качестве утешения я принёс вам гит на проект в Unity, который на основе метадаты позволяет играться с синхронизированными данными Iphone…
Дальность лидаров, к сожалению, ограничена 5 метрами и это не риалтайм.
Но в качестве утешения я принёс вам гит на проект в Unity, который на основе метадаты позволяет играться с синхронизированными данными Iphone…
This media is not supported in your browser
VIEW IN TELEGRAM
Отвал башки! Тут пацаны из гугла обучили NERF на RAW фотках. Получается просто башенного качества рендеринг HDR изображений. Можно менять экспозицию, фокус. Вы только посмотрите на получаемый эффект боке в ночных сценах!
Дополнительное преимущество этого метода перед обычным нерфом - это то, что он хорошо работает на шумных снимках с малым освещением. За счет того, что информация агрегируется с нескольких фотографий, метод хорошо справляется с шумом и недостатком освещения, превосходя специализированные single-photo denoising модели.
Статью ознаменовали как NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images. Ну, разве что кода еще нет.
Сайт проекта | Arxiv
Дополнительное преимущество этого метода перед обычным нерфом - это то, что он хорошо работает на шумных снимках с малым освещением. За счет того, что информация агрегируется с нескольких фотографий, метод хорошо справляется с шумом и недостатком освещения, превосходя специализированные single-photo denoising модели.
Статью ознаменовали как NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images. Ну, разве что кода еще нет.
Сайт проекта | Arxiv
Генеративные сети уже вышли на уровень, когда их действительно можно юзать в проде. Вот например очень толковая тулзня для удаления объектов с фото https://cleanup.pictures. Под капотом просто гоняется сетка для инпейнтинга от самсунга.
Видео взял тут.
Видео взял тут.
Adobe Research во всю занимается манипуляциями с изображениями, как в посте выше про удаление объектов.
Надеюсь, все это скоро перекочует в фотошоп. Кстати, надо прикупить их акций.
Надеюсь, все это скоро перекочует в фотошоп. Кстати, надо прикупить их акций.
Adobe Research
Adobe Research at ICCV 2021
Adobe actively participates in the IEEE Computer Society International Conference on Computer Vision (ICCV) each year. At this year's conference, taking place from October 11-17, Adobe is presenting new work in the area of computer vision. Check out the full…
O проблеме GAN Inversion
Как манипулируют изображениями с помощью StyleGAN? Ну, для начала нужно получить latent code, который соответствует входному фото. Затем уже можно менять этот код, и получать изменённые картинки. Процесс получения latent code по фото называют GAN Inversion.
Базовый метод для нахождения кода по фото - это итеративный градиентый спуск, где веса сетки заморожены, и меняется только сам код, пока сгенеренная из кода картинка не станет похожей на исходную. Но вот зараза, медленно работает! Тогда народ стал применять дополнительную сеть-энкодер, которую учат мапить картинку в latent code за один прогон. Это быстро, но восстановленное из кода изображение все же теряет некоторые детали. Тут пхд студенты почесали репу и предложили немного файнтюнить веса StyleGAN под определенный latent code, чтобы получить картинку более близкую к исходной, и затем уже проводить с ней манипуляции в скрытом пространстве. Но это же тоже медленно!
Но и тут нашелся выход. В статье HyperStyle (есть код) авторы предложили использовать ещё одну "гиперсеть", которая получает на вход оригинальное фото и восстановленное из кода, который, скажем, был получен базовым методом с итеративной оптимизацией либо энкодером. Эта "гиперсеть" напрямую предсказывает, как обновить веса StyleGAN, чтобы изображение сгенерированное из данного кода было максимально похоже на исходное. Этакий "нейронный градиент" вместо честного градиента посчитанного по функции потерь.
Итого, файнтюнинг весов StyleGAN под конкретную входную картинку даёт очень хорошие результаты и позволяет менять, например, лица людей без потери идентичности. А с помощью HyperStyle это можно делать раз в 40 быстрее, заменяя честный файнтюнинг на трюк с гиперсетью.
Как манипулируют изображениями с помощью StyleGAN? Ну, для начала нужно получить latent code, который соответствует входному фото. Затем уже можно менять этот код, и получать изменённые картинки. Процесс получения latent code по фото называют GAN Inversion.
Базовый метод для нахождения кода по фото - это итеративный градиентый спуск, где веса сетки заморожены, и меняется только сам код, пока сгенеренная из кода картинка не станет похожей на исходную. Но вот зараза, медленно работает! Тогда народ стал применять дополнительную сеть-энкодер, которую учат мапить картинку в latent code за один прогон. Это быстро, но восстановленное из кода изображение все же теряет некоторые детали. Тут пхд студенты почесали репу и предложили немного файнтюнить веса StyleGAN под определенный latent code, чтобы получить картинку более близкую к исходной, и затем уже проводить с ней манипуляции в скрытом пространстве. Но это же тоже медленно!
Но и тут нашелся выход. В статье HyperStyle (есть код) авторы предложили использовать ещё одну "гиперсеть", которая получает на вход оригинальное фото и восстановленное из кода, который, скажем, был получен базовым методом с итеративной оптимизацией либо энкодером. Эта "гиперсеть" напрямую предсказывает, как обновить веса StyleGAN, чтобы изображение сгенерированное из данного кода было максимально похоже на исходное. Этакий "нейронный градиент" вместо честного градиента посчитанного по функции потерь.
Итого, файнтюнинг весов StyleGAN под конкретную входную картинку даёт очень хорошие результаты и позволяет менять, например, лица людей без потери идентичности. А с помощью HyperStyle это можно делать раз в 40 быстрее, заменяя честный файнтюнинг на трюк с гиперсетью.
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
А вот и видео, полученное с помощью HyperStyle (см. пост выше).
NSFW контент
В сети появились кадры бэкстейджа съемки VR-порно.
Обратите внимание на тучу синхронизированных камер и нательных маркеров. Интересно, в PornHub занимаются нейронными сетями? Может быть они там сейчас пытаются прикрутить нерфы?😄
В сети появились кадры бэкстейджа съемки VR-порно.
Обратите внимание на тучу синхронизированных камер и нательных маркеров. Интересно, в PornHub занимаются нейронными сетями? Может быть они там сейчас пытаются прикрутить нерфы?😄
Telegram
Future Sailors — VR, AR and stuff
Forwarded from Мишин Лернинг 🇺🇦🇮🇱
🧠 Подборка полезных видео про NeRF: Neural Radiance Fields Forever
Нейронный 3D рендер это уже настоящее. И NeRF и его производные захватывают наши сердца.
Собрал крутую подборку самых полезных youtube видео про технологию:
💟 NeRF paper review от Яныка
🔍 NeRF лекция от Матью из Berkeley
⏳FastNeRF 200fps от Microsoft
🔻NeX + NeRF от Gradient Dude (от автора эйай ньюз)
🧸 Почему нейронные рендеринг это круто? от MIT
p.s.: каждый пиксель картинки к посту сделал при помощи далли Malevich
#всохраненки
Нейронный 3D рендер это уже настоящее. И NeRF и его производные захватывают наши сердца.
Собрал крутую подборку самых полезных youtube видео про технологию:
💟 NeRF paper review от Яныка
🔍 NeRF лекция от Матью из Berkeley
⏳FastNeRF 200fps от Microsoft
🔻NeX + NeRF от Gradient Dude (от автора эйай ньюз)
🧸 Почему нейронные рендеринг это круто? от MIT
p.s.: каждый пиксель картинки к посту сделал при помощи далли Malevich
#всохраненки
Forwarded from Neural Shit
Ух! Это, наверное, лучшее из того, что я видел в плане реконструкции изображений с шакальным качеством. Исходники открыты и лежат тут
This media is not supported in your browser
VIEW IN TELEGRAM
Поженим NeRF и трансформеры, получим NerFormer!
Базовый метод реконструкции 3D сцены с помощью нейронных сетей, NeRF, имеет ряд ограничений. Например, он медленный (хотя каждый месяц выходят статьи, ускоряющие его), и его нужно с нуля обучать на каждой новой сцене/объекте. Мои коллеги из Meta (Facebook) AI Research прокачали NeRF, решив некоторые из его пробелм (детали в посте ниже).
Также в статье представлен самый большой (19к видео) публичный датасет с 360-градусным облетом вещей в "дикой природе".
Итого, имеем сильный метод для нейронной генерации новых view для 3D объектов - NerFormer. Он способен научиться рендерить сразу много категорий объектов, а так же может быть быстро зафайнтюнен на новых объектах всего по нескольким фото.
Кода для тренировки нет но есть код для теста. Сама статья на arxiv.
Если вы ничего не поняли, то советую почитать вот этот пост про нейронный рендеринг и этот.
Базовый метод реконструкции 3D сцены с помощью нейронных сетей, NeRF, имеет ряд ограничений. Например, он медленный (хотя каждый месяц выходят статьи, ускоряющие его), и его нужно с нуля обучать на каждой новой сцене/объекте. Мои коллеги из Meta (Facebook) AI Research прокачали NeRF, решив некоторые из его пробелм (детали в посте ниже).
Также в статье представлен самый большой (19к видео) публичный датасет с 360-градусным облетом вещей в "дикой природе".
Итого, имеем сильный метод для нейронной генерации новых view для 3D объектов - NerFormer. Он способен научиться рендерить сразу много категорий объектов, а так же может быть быстро зафайнтюнен на новых объектах всего по нескольким фото.
Кода для тренировки нет но есть код для теста. Сама статья на arxiv.
Если вы ничего не поняли, то советую почитать вот этот пост про нейронный рендеринг и этот.
Что же нового в NerFormer?
(продолжение предыдущего поста)
Во первых, кроме (x,y,z) координат точки и направления луча, на вход подаются соответствующие этой 3D точке фичи из всех картинок, на которых видна эта точка. Так агрегируется информация с разных входных фото. А фичи из претренированного на ImageNet резнета дают сильный априорную информацию о том, какая сцена сейчас генерируется.
Во вторых, вместо MLP (multilayer perceptron), который может обрабатывать только одну 3D точку за раз, авторы впервые предложили NeRF на основе трансформера. На вход подаются сразу все точки лежащие на луче, а не по одной как в случае MLP. Таким образом сеть имеет больше контекста и лучше справляется с шумом в данных.
Прикрепляю картинки с визуализацией всей архитектуры NerFormer.
(продолжение предыдущего поста)
Во первых, кроме (x,y,z) координат точки и направления луча, на вход подаются соответствующие этой 3D точке фичи из всех картинок, на которых видна эта точка. Так агрегируется информация с разных входных фото. А фичи из претренированного на ImageNet резнета дают сильный априорную информацию о том, какая сцена сейчас генерируется.
Во вторых, вместо MLP (multilayer perceptron), который может обрабатывать только одну 3D точку за раз, авторы впервые предложили NeRF на основе трансформера. На вход подаются сразу все точки лежащие на луче, а не по одной как в случае MLP. Таким образом сеть имеет больше контекста и лучше справляется с шумом в данных.
Прикрепляю картинки с визуализацией всей архитектуры NerFormer.
This media is not supported in your browser
VIEW IN TELEGRAM
В Метаверсе для полного погружения очень пригодится точная и быстрая симуляция физики.
Челик в Твиттере говорит, что на этом видео риал-тайм симуляция одежды. Что-то есть сомнения... Слишком уж круто это выглядит! И брейк-данс зачетный!
Челик в Твиттере говорит, что на этом видео риал-тайм симуляция одежды. Что-то есть сомнения... Слишком уж круто это выглядит! И брейк-данс зачетный!