
This media is not supported in your browser
VIEW IN TELEGRAM
Круть! Робо-рука для барабанщика.
Барабанщик попал в аварию и лишился руки. Чтобы парень мог продолжать заниматься любовью всей своей жизни, ученые из Geogia Tech создали для него робо-протез, который снимает мышечные импульсы с предплечья и дает фантастический контроль над барабанной палочкой с минимальной задержкой. Без диплернинга, конечно, не обошлось.
Полное видео.
Барабанщик попал в аварию и лишился руки. Чтобы парень мог продолжать заниматься любовью всей своей жизни, ученые из Geogia Tech создали для него робо-протез, который снимает мышечные импульсы с предплечья и дает фантастический контроль над барабанной палочкой с минимальной задержкой. Без диплернинга, конечно, не обошлось.
Полное видео.
Forwarded from DL in NLP (nlpcontroller_bot)
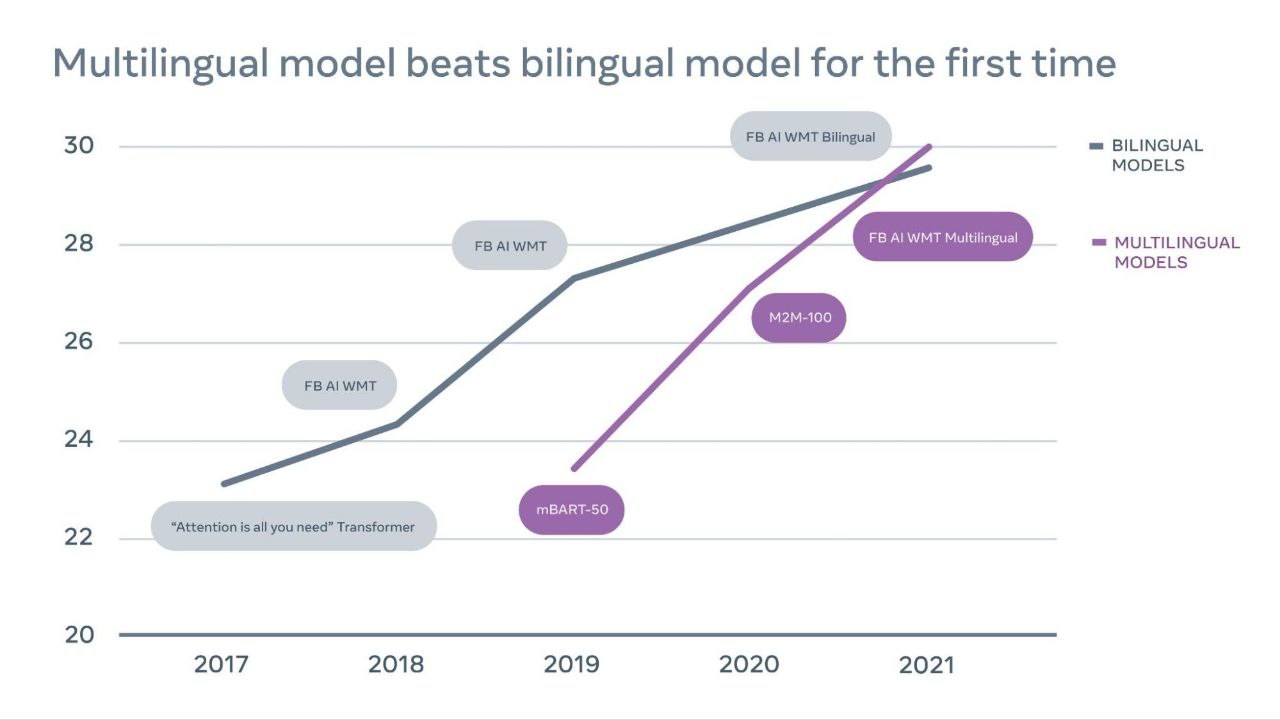
Мультиязычная модель машинного перевода от FAIR превзошла двуязычные модели на соревновании WMT-21.
Статья: arxiv.org/abs/2108.03265
Блог: ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
Мультиязычный перевод сложно делать. Несмотря на то, что за последние годы научились обучать большие модели, которые улучшают качество перевода на низкоресурсных языках, с высокоресурсными языками это долгое время не работало и двуязычные модели продолжали работать лучше мультиязычных.
FAIR (Meta AI?) в новой статье наконец-то преодолели этот порог. Их модель превосходит двуязычные, чего добились с помощью более умного (и объемного) майнинга обучающих данных - как параллельных так и непараллельных и использования mixture of experts (MoE) для скейлинга модели до 52B параметров.
Статья: arxiv.org/abs/2108.03265
Блог: ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
Мультиязычный перевод сложно делать. Несмотря на то, что за последние годы научились обучать большие модели, которые улучшают качество перевода на низкоресурсных языках, с высокоресурсными языками это долгое время не работало и двуязычные модели продолжали работать лучше мультиязычных.
FAIR (Meta AI?) в новой статье наконец-то преодолели этот порог. Их модель превосходит двуязычные, чего добились с помощью более умного (и объемного) майнинга обучающих данных - как параллельных так и непараллельных и использования mixture of experts (MoE) для скейлинга модели до 52B параметров.
{kind=link}
Если вы интересуетесь большими генеративными нейросетями (привет, GPT-3 и YaLM), то уже могли читать статью на arxiv про новый подход к их настройке: P-Tuning. Это решение хорошо экономит время для инженера и вычислительные ресурсы.
Более доступно и на примере реальных продуктов про новое решение можно почитать в статье Яндекса на Хабре: habr.com/ru/company/yandex/blog/588214/
Более доступно и на примере реальных продуктов про новое решение можно почитать в статье Яндекса на Хабре: habr.com/ru/company/yandex/blog/588214/
О Нейронном Рендеринге
Что такое Нейронный Рендеринг? Если немного сумбурно, то нейронный рендеринг — это когда мы берем классические алгоритмы синтеза изображений из компьютерной графики и заменяем часть пайплайна нейронными сетями (тупо, но эффективно). Нейронный рендеринг учится рендерить и представлять сцену из одной или нескольких реальных фотографий, имитируя физический процесс камеры, которая фотографирует сцену. Ключевая особенность нейронного рендеринга — разделение процесса фотографирования (т.е. проекции и формирования изображения) и представления трехмерной сцены во время обучения. То есть мы учим отдельное представление трехмерной сцены в явном (воксели, облака точек, параметрически заданные поверхности) либо в неявном виде (signed distance function), из которого рендерятся наблюдаемые изображения. Чтобы всё это обучать, важно чтобы весь процесс рендеринга был дифференцируемым.
Может вы не заметили, но тема нейронного рендеринга, включая всякие нерфы-шмерфы, сейчас хайпует в компьютерном зрении. Вы скажете, что нейронный рендеринг — это очень медленно, и вы будете правы. Обычная тренировка на небольшой сцене с ~50 фотографиями занимает у самого быстрого метода около 5.5 часов на одной GPU, но прогресс не стоит на месте и методы очень активно развиваются. Чтобы охватить все недавние наработки в этом направлении, очень советую прочитать этот SOTA репорт "Advances in Neural Rendering".
Что такое Нейронный Рендеринг? Если немного сумбурно, то нейронный рендеринг — это когда мы берем классические алгоритмы синтеза изображений из компьютерной графики и заменяем часть пайплайна нейронными сетями (тупо, но эффективно). Нейронный рендеринг учится рендерить и представлять сцену из одной или нескольких реальных фотографий, имитируя физический процесс камеры, которая фотографирует сцену. Ключевая особенность нейронного рендеринга — разделение процесса фотографирования (т.е. проекции и формирования изображения) и представления трехмерной сцены во время обучения. То есть мы учим отдельное представление трехмерной сцены в явном (воксели, облака точек, параметрически заданные поверхности) либо в неявном виде (signed distance function), из которого рендерятся наблюдаемые изображения. Чтобы всё это обучать, важно чтобы весь процесс рендеринга был дифференцируемым.
Может вы не заметили, но тема нейронного рендеринга, включая всякие нерфы-шмерфы, сейчас хайпует в компьютерном зрении. Вы скажете, что нейронный рендеринг — это очень медленно, и вы будете правы. Обычная тренировка на небольшой сцене с ~50 фотографиями занимает у самого быстрого метода около 5.5 часов на одной GPU, но прогресс не стоит на месте и методы очень активно развиваются. Чтобы охватить все недавние наработки в этом направлении, очень советую прочитать этот SOTA репорт "Advances in Neural Rendering".
This media is not supported in your browser
VIEW IN TELEGRAM
Что будет если преобразовать картину Анри Руссо из 2D в 3D? 🐅
Просто топовый ролик для выходного дня от @wearemeta
Телега, как всегда, шакалит качество 😐
Просто топовый ролик для выходного дня от @wearemeta
Телега, как всегда, шакалит качество 😐
Media is too big
VIEW IN TELEGRAM
Статья о восстановлении 3D поверхности по динамическому облаку точек [ICCV21]
Метод решает очень сложную задачу - он позволяет восстановить консистентную во времени поверхность, только наблюдая за меняющимся во времени облаком точек. Тут и реконструкция и нахождение соответсвия между формами в разные моменты времени - это вам не просто конь!
Метод не требует никакого супервижена: только наборы 3D точек (например, они могут быть получены с помощью лидара), дифференциальная геометрия и нейронные сети. Очень крутые результаты.
Сайт проекта | Код
Метод решает очень сложную задачу - он позволяет восстановить консистентную во времени поверхность, только наблюдая за меняющимся во времени облаком точек. Тут и реконструкция и нахождение соответсвия между формами в разные моменты времени - это вам не просто конь!
Метод не требует никакого супервижена: только наборы 3D точек (например, они могут быть получены с помощью лидара), дифференциальная геометрия и нейронные сети. Очень крутые результаты.
Сайт проекта | Код
Диффузионные генеративные модели все больше и больше отжимают территорию у Ганов.
Про диффузионные модели я уже писал раньше. А в свежей статье Palette: Image-to-Image Diffusion Models от Гугла их теперь использовали для общей постановки задачи перевода из одной картинки в другу. То есть они могут делать и инпейнтинг, и условную генерацию, и экстраполяцию, и колоризацию, и все что хотите.
На картинках снизу только центральная часть подавалась на вход сети. Все, что по бокам – сгенерировано. Очень впечатляет.
Про диффузионные модели я уже писал раньше. А в свежей статье Palette: Image-to-Image Diffusion Models от Гугла их теперь использовали для общей постановки задачи перевода из одной картинки в другу. То есть они могут делать и инпейнтинг, и условную генерацию, и экстраполяцию, и колоризацию, и все что хотите.
На картинках снизу только центральная часть подавалась на вход сети. Все, что по бокам – сгенерировано. Очень впечатляет.
Telegram
Denis Sexy IT 🤖
Google Research показал алгоритм Palette который решает задачу «догенерирования» скрытых частей картинок на таком уровне, на котором я еще не встречал – в посте примеры, центральная часть этих картинок реальны, остальные части панорам сгенерированы. Сразу…
Media is too big
VIEW IN TELEGRAM
Тактильная перчатка для метаверса от Meta's Reality Labs
Reality Labs работает над тем чтобы сделать вирутальный мир более реалистичным, в том числе хотелось бы иметь тактильный отклик, когда ты что-то трогаешь в виртуальной реальности. Для этого и предназначена перчатка, которая была представлена сегодня.
Чтобы обеспечить реалистичное осязание, тактильной перчатке требуются сотни приводов (крошечных двигателей) по всей руке, движущихся согласованно. Но существующие механические приводы выделяют слишком много тепла, чтобы такую перчатку можно было удобно носить весь день. К тому же они слишком большие, жесткие, дорогие и энергоемкие, чтобы передавать реалистичные тактильные ощущения.
В перчаке от Meta встроены пневматические приводы, которые используют давление воздуха для создания силы. Управляет этими приводами крошечный микрожидкостный чип на перчатке. Он контроллирует воздушный поток, сообщая клапанам, когда и как сильно открываться и закрываться для создания давления в нужных местах.
Подробнее.
Reality Labs работает над тем чтобы сделать вирутальный мир более реалистичным, в том числе хотелось бы иметь тактильный отклик, когда ты что-то трогаешь в виртуальной реальности. Для этого и предназначена перчатка, которая была представлена сегодня.
Чтобы обеспечить реалистичное осязание, тактильной перчатке требуются сотни приводов (крошечных двигателей) по всей руке, движущихся согласованно. Но существующие механические приводы выделяют слишком много тепла, чтобы такую перчатку можно было удобно носить весь день. К тому же они слишком большие, жесткие, дорогие и энергоемкие, чтобы передавать реалистичные тактильные ощущения.
В перчаке от Meta встроены пневматические приводы, которые используют давление воздуха для создания силы. Управляет этими приводами крошечный микрожидкостный чип на перчатке. Он контроллирует воздушный поток, сообщая клапанам, когда и как сильно открываться и закрываться для создания давления в нужных местах.
Подробнее.
Я ищу Research Scientist интернов в нашу команду в Reality Labls (Meta).
Всем доброго вечера! Следующим летом у вас есть возможность постажироваться в одном из топовых по ресерчу в Computer Vision мест - Reality Labs | Meta.
Нас интересуют следующие темы для исследований:
- Нейронный рендеринг, включая нерфы и не только;
- 3D реконструкция людей и объектов, и их эффективнвя репрезентация с помощью нейронных сетей;
- Синтез изображений (ганы, дифузионные модели, и т.д.) в 2D и 3D.
Главной задачей интерна будет засабмитить статью на CVPR 2023 (!)
Желаемый кандидат:
- PhD студент, либо уже заканчивает PhD.
- Солидный опыт в ресерче, подтвержденный публикациями на конфах уровня NeurIPS, ICLR, CVPR, ICCV, ECCV, ICML.
- Недюжие способности имплементировать свои идеи, подтвержденные другими стажировками, победами на Kaggle, пет-проектами.
Базируемся мы в Цюрихе, интерншип тоже тут (не виртуально).
Слать резюме мне в личку либо на почту.
https://www.facebookcareers.com/jobs/1740770532980419/
Всем доброго вечера! Следующим летом у вас есть возможность постажироваться в одном из топовых по ресерчу в Computer Vision мест - Reality Labs | Meta.
Нас интересуют следующие темы для исследований:
- Нейронный рендеринг, включая нерфы и не только;
- 3D реконструкция людей и объектов, и их эффективнвя репрезентация с помощью нейронных сетей;
- Синтез изображений (ганы, дифузионные модели, и т.д.) в 2D и 3D.
Главной задачей интерна будет засабмитить статью на CVPR 2023 (!)
Желаемый кандидат:
- PhD студент, либо уже заканчивает PhD.
- Солидный опыт в ресерче, подтвержденный публикациями на конфах уровня NeurIPS, ICLR, CVPR, ICCV, ECCV, ICML.
- Недюжие способности имплементировать свои идеи, подтвержденные другими стажировками, победами на Kaggle, пет-проектами.
Базируемся мы в Цюрихе, интерншип тоже тут (не виртуально).
Слать резюме мне в личку либо на почту.
https://www.facebookcareers.com/jobs/1740770532980419/
Facebook
Log in or sign up to view
See posts, photos and more on Facebook.
Forwarded from DL in NLP (nlpcontroller_bot)
⚡️OpenAI’s API Now Available with No Waitlist
Наконец-то OpenAI открыли публичный доступ к GPT-3. За время закрытого теста к нему добавили небольшие улучшения, такие как Instruct series models, которые лучше реагируют на промты. Кроме этого добавили в документацию safety best practices, которые рассказывают как сделать такую систему, которую нельзя будет атаковать очевидными способами.
Цена пока что кажется неплохой, по крайней мере ниже чем я ожидал. Самая большая модель стоит 6 центов за тысячу токенов. После регистрации вам дают $18, чего хватит для генерации 300 тысяч токенов.
Заходите на openai.com/api, регистрируйтесь и играйтесь с GPT-3 или Codex. Пишите что получается в чат, будет интересно узнать какие у людей в среднем впечатления.
Наконец-то OpenAI открыли публичный доступ к GPT-3. За время закрытого теста к нему добавили небольшие улучшения, такие как Instruct series models, которые лучше реагируют на промты. Кроме этого добавили в документацию safety best practices, которые рассказывают как сделать такую систему, которую нельзя будет атаковать очевидными способами.
Цена пока что кажется неплохой, по крайней мере ниже чем я ожидал. Самая большая модель стоит 6 центов за тысячу токенов. После регистрации вам дают $18, чего хватит для генерации 300 тысяч токенов.
Заходите на openai.com/api, регистрируйтесь и играйтесь с GPT-3 или Codex. Пишите что получается в чат, будет интересно узнать какие у людей в среднем впечатления.
Openai
API platform
Our API platform offers our latest models and guides for safety best practices.
Всем приветы! Немного выпал на выходные. Теперь вернулся к вам с новыми статейками ☺️
SOTA по обнаружению модифицированных дубликатов среди изображений от Baidu Research [часть 1]
Статья представляет собой набор практических трюков. Иногда интересно почитать такое, чтобы иметь представление о том, как выжать максимум из сетки на определенной задаче. Тут авторы рассказывают как обучить дескрипторы, по которым можно определять являются ли пары изображений модификациями одного и того же. Это полезно, например, для обнаружения нарушений авторских прав.
Архитектура коротко:
1. Вместо предобучения на лейблах используется энкодер, обученный self-supervised методом Barlow Twins на ImageNet - это когда минимизируется матрица кросс-корреляции между фичами двух разных аугментаций оригинального фото (о Barlow Twins я писал тут).
2. К фичам энкодера применяется Generalized-mean pooling (GeM) - обучаемый пулинг, который вместо ∞-нормы (maxpool), или 1-нормы (avgpool) вычисляет p-норму по каждому каналу.
3. ...
Статья | Код
Статья представляет собой набор практических трюков. Иногда интересно почитать такое, чтобы иметь представление о том, как выжать максимум из сетки на определенной задаче. Тут авторы рассказывают как обучить дескрипторы, по которым можно определять являются ли пары изображений модификациями одного и того же. Это полезно, например, для обнаружения нарушений авторских прав.
Архитектура коротко:
1. Вместо предобучения на лейблах используется энкодер, обученный self-supervised методом Barlow Twins на ImageNet - это когда минимизируется матрица кросс-корреляции между фичами двух разных аугментаций оригинального фото (о Barlow Twins я писал тут).
2. К фичам энкодера применяется Generalized-mean pooling (GeM) - обучаемый пулинг, который вместо ∞-нормы (maxpool), или 1-нормы (avgpool) вычисляет p-норму по каждому каналу.
3. ...
Статья | Код