
Как лгать при помощи статистики
Хафф Дарелл - автор книги "Как лгать при помощи статистики". Книга скорее не о статистике, а о манипуляциях СМИ. Автор на примерах показывает как можно за уши притянуть статистику и доказать все что угодно.
Оказывается Хафф Дарелл на деньги табачной индустрии писал книгу (но не закончил) "Как лгать при помощи статистики курения". В книге критиковалась статистика вреда табака. Автор занимался пропагандой пользы курения.
Как говорится: легко врать с помощью статистики, но без статистики - еще легче.
Хафф Дарелл - автор книги "Как лгать при помощи статистики". Книга скорее не о статистике, а о манипуляциях СМИ. Автор на примерах показывает как можно за уши притянуть статистику и доказать все что угодно.
Оказывается Хафф Дарелл на деньги табачной индустрии писал книгу (но не закончил) "Как лгать при помощи статистики курения". В книге критиковалась статистика вреда табака. Автор занимался пропагандой пользы курения.
Как говорится: легко врать с помощью статистики, но без статистики - еще легче.
Кратко про нашу историю с АВ-тестами в 5 постах
1. Как мы запускали первые АВ-тесты
https://t.me/abtestingmobilegames/2
2. Что изменилось после внедрения AB-тестов
https://t.me/abtestingmobilegames/11
3. Как жулики помогают нам больше зарабатывать
https://t.me/abtestingmobilegames/18
4. Какие книги изучали
https://t.me/abtestingmobilegames/35
5. Как вырастили LTV на 50%
https://t.me/abtestingmobilegames/38
1. Как мы запускали первые АВ-тесты
https://t.me/abtestingmobilegames/2
2. Что изменилось после внедрения AB-тестов
https://t.me/abtestingmobilegames/11
3. Как жулики помогают нам больше зарабатывать
https://t.me/abtestingmobilegames/18
4. Какие книги изучали
https://t.me/abtestingmobilegames/35
5. Как вырастили LTV на 50%
https://t.me/abtestingmobilegames/38
Telegram
A/B-тестирование в мобильных играх
Как мы внедрили АБ тестирование в наших играх
Кто мы
Мы в Stereo7 Games делаем стратегии в жанре tower defense. Наш текущий главный проект - это игра Steampunk Defense: https://play.google.com/store/apps/details…. При разработке, мы уже более 2-ух лет активно…
Кто мы
Мы в Stereo7 Games делаем стратегии в жанре tower defense. Наш текущий главный проект - это игра Steampunk Defense: https://play.google.com/store/apps/details…. При разработке, мы уже более 2-ух лет активно…
Студия “4fan studio games” разрешила рассказать нам об эксперименте, который они запустили вместе с нами.
Ребята делают RPG-рогалик в фэнтази сеттинге. Google Play: Dungeon: Age Of Heroes. В новом апдейте к игре:
1. Поменяли систему уровней. Добавили “этажи” для них.
2. Добавили на каждый последний этаж мини-босса.
3. Улучшили генератор уровней.
Посмотрим, что стало с метриками:
1. Всего игроков в эксперименте: 5000
2. Покупки внутриигровой валюты: без изменений
3. Среднее число показов рекламы на игрока: Статистически значимое улучшение. Было: 17.5, Стало: 20.31
4. 1-day retention: -1.66%
5. Lifetime: от -6 до -1 часа игры
Новый апдейт игроки восприняли как paywall. Они стали чуть меньше времени проводить в игре, но примерно на 17% больше смотреть рекламу.
“4fan studio games”, поздравляем вас с отличным результатом!
Нам очень приятно быть частью вашей истории!
Ребята делают RPG-рогалик в фэнтази сеттинге. Google Play: Dungeon: Age Of Heroes. В новом апдейте к игре:
1. Поменяли систему уровней. Добавили “этажи” для них.
2. Добавили на каждый последний этаж мини-босса.
3. Улучшили генератор уровней.
Посмотрим, что стало с метриками:
1. Всего игроков в эксперименте: 5000
2. Покупки внутриигровой валюты: без изменений
3. Среднее число показов рекламы на игрока: Статистически значимое улучшение. Было: 17.5, Стало: 20.31
4. 1-day retention: -1.66%
5. Lifetime: от -6 до -1 часа игры
Новый апдейт игроки восприняли как paywall. Они стали чуть меньше времени проводить в игре, но примерно на 17% больше смотреть рекламу.
“4fan studio games”, поздравляем вас с отличным результатом!
Нам очень приятно быть частью вашей истории!
{kind=link}
A/B-тестирование в мобильных играх pinned «Кратко про нашу историю с АВ-тестами в 5 постах 1. Как мы запускали первые АВ-тесты https://t.me/abtestingmobilegames/2 2. Что изменилось после внедрения AB-тестов https://t.me/abtestingmobilegames/11 3. Как жулики помогают нам больше зарабатывать ht…»
Anti-fraud
На любую надежную и стройную систему всегда найдется ломатель. Там, где есть товар, всегда есть вор.
Работая с разными системами аналитики, мы заметили отличие суммы на графиках и суммы выплат платформы (App Store или Google Play). Причина простая - fraud. Игрок обманывает игру и получает контент бесплатно.
Техническая сторона чаще всего такая:
1. Жулик скачивает приложение, которое стоит между вызовами игры и Google Play.
2. Жулик делает в игре запрос на покупку.
3. Подключается промежуточное приложение, которое принимает этот запрос и высылает игре подтверждение оплаты.
4. Игра, ничего не подозревая, выдает жулику внутриигровой контент.
5. Жулик счастлив.
Решение простое - перед шагом 4 ваше приложение отправляет запрос на сервер, про который не знает приложение жулика, для проверки транзакции. В нашей платформе, например, такой сценарий реализован и для Android, и для Apple. Все транзакции проверяются на валидность - метрики в экспериментах честные.
На любую надежную и стройную систему всегда найдется ломатель. Там, где есть товар, всегда есть вор.
Работая с разными системами аналитики, мы заметили отличие суммы на графиках и суммы выплат платформы (App Store или Google Play). Причина простая - fraud. Игрок обманывает игру и получает контент бесплатно.
Техническая сторона чаще всего такая:
1. Жулик скачивает приложение, которое стоит между вызовами игры и Google Play.
2. Жулик делает в игре запрос на покупку.
3. Подключается промежуточное приложение, которое принимает этот запрос и высылает игре подтверждение оплаты.
4. Игра, ничего не подозревая, выдает жулику внутриигровой контент.
5. Жулик счастлив.
Решение простое - перед шагом 4 ваше приложение отправляет запрос на сервер, про который не знает приложение жулика, для проверки транзакции. В нашей платформе, например, такой сценарий реализован и для Android, и для Apple. Все транзакции проверяются на валидность - метрики в экспериментах честные.
Как не потерять деньги и спать спокойно.
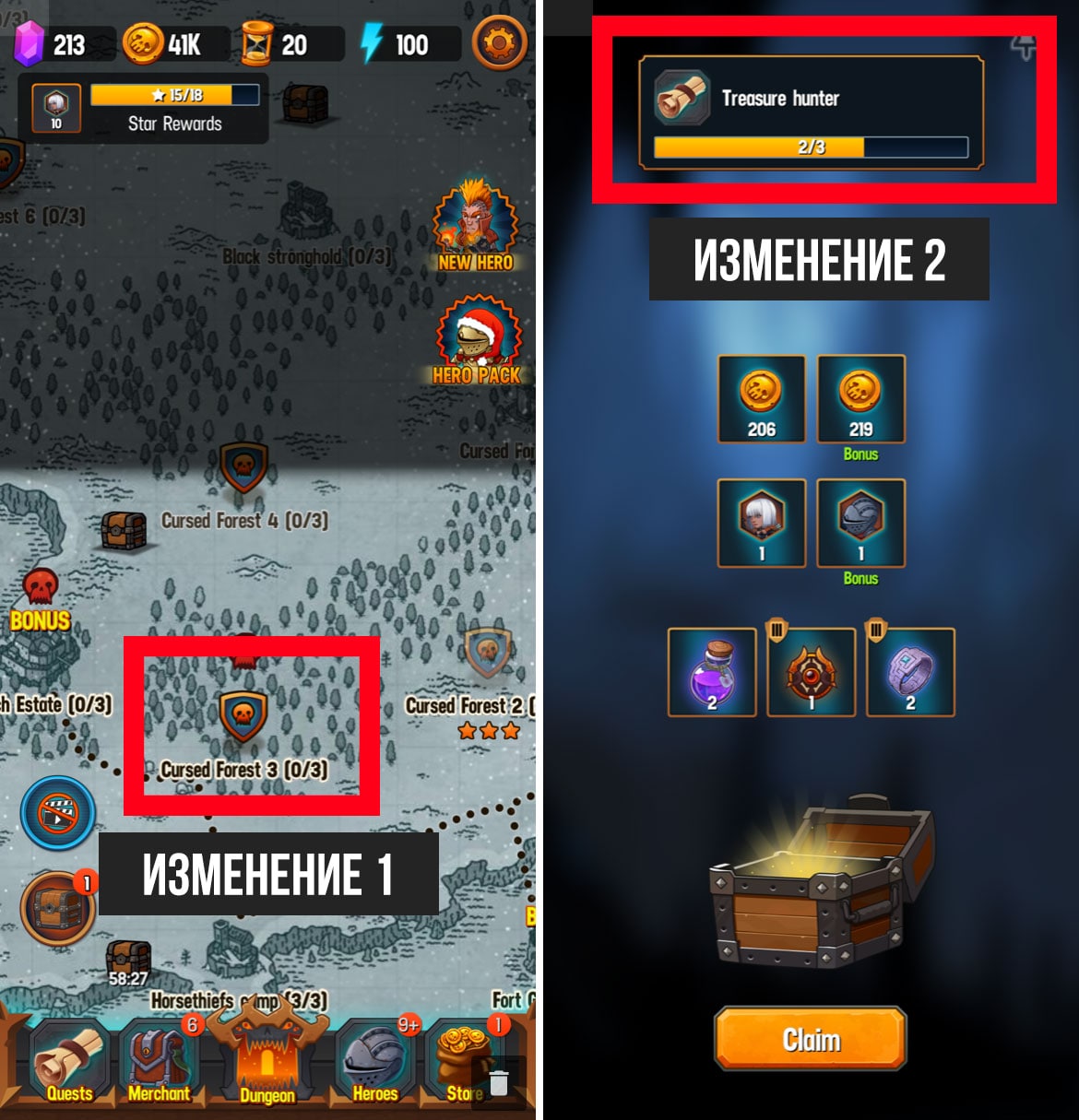
Мобильная игра нашего клиента уже приносит деньги. Он обновляет игру и боится потерять деньги, если обновление не понравится игрокам. Запускать классический АБ эксперимент на 50% аудитории клиент не хочет, т.к. потери на такой части игроков уже болезненны.
Воспользуемся инструментом audience в нашей платформе:
1. Запустим эксперимент на 10% игроков.
Свойство exposure устанавливает долю игроков, которые участвуют в эксперименте. Остальная часть игроков не увидит изменений, а значит деньги клиент не теряет.
2. Запустим эксперимент на когорте игроков.
У клиента 80% дохода - это игроки из фейсбука. Запустим эксперимент на игроках, которые пришли не с фейсбука. Для этого установим параметр install source = unity. Только игроки, которые пришли в игру из рекламной сетки unity, попадут в эксперимент.
На картинке 2 заполненных поля exposure и install source. Они подарили клиенту спокойный сон.
Мобильная игра нашего клиента уже приносит деньги. Он обновляет игру и боится потерять деньги, если обновление не понравится игрокам. Запускать классический АБ эксперимент на 50% аудитории клиент не хочет, т.к. потери на такой части игроков уже болезненны.
Воспользуемся инструментом audience в нашей платформе:
1. Запустим эксперимент на 10% игроков.
Свойство exposure устанавливает долю игроков, которые участвуют в эксперименте. Остальная часть игроков не увидит изменений, а значит деньги клиент не теряет.
2. Запустим эксперимент на когорте игроков.
У клиента 80% дохода - это игроки из фейсбука. Запустим эксперимент на игроках, которые пришли не с фейсбука. Для этого установим параметр install source = unity. Только игроки, которые пришли в игру из рекламной сетки unity, попадут в эксперимент.
На картинке 2 заполненных поля exposure и install source. Они подарили клиенту спокойный сон.
Пираты тестам не помеха
Пираты не только воруют игры, но еще и портят тесты.
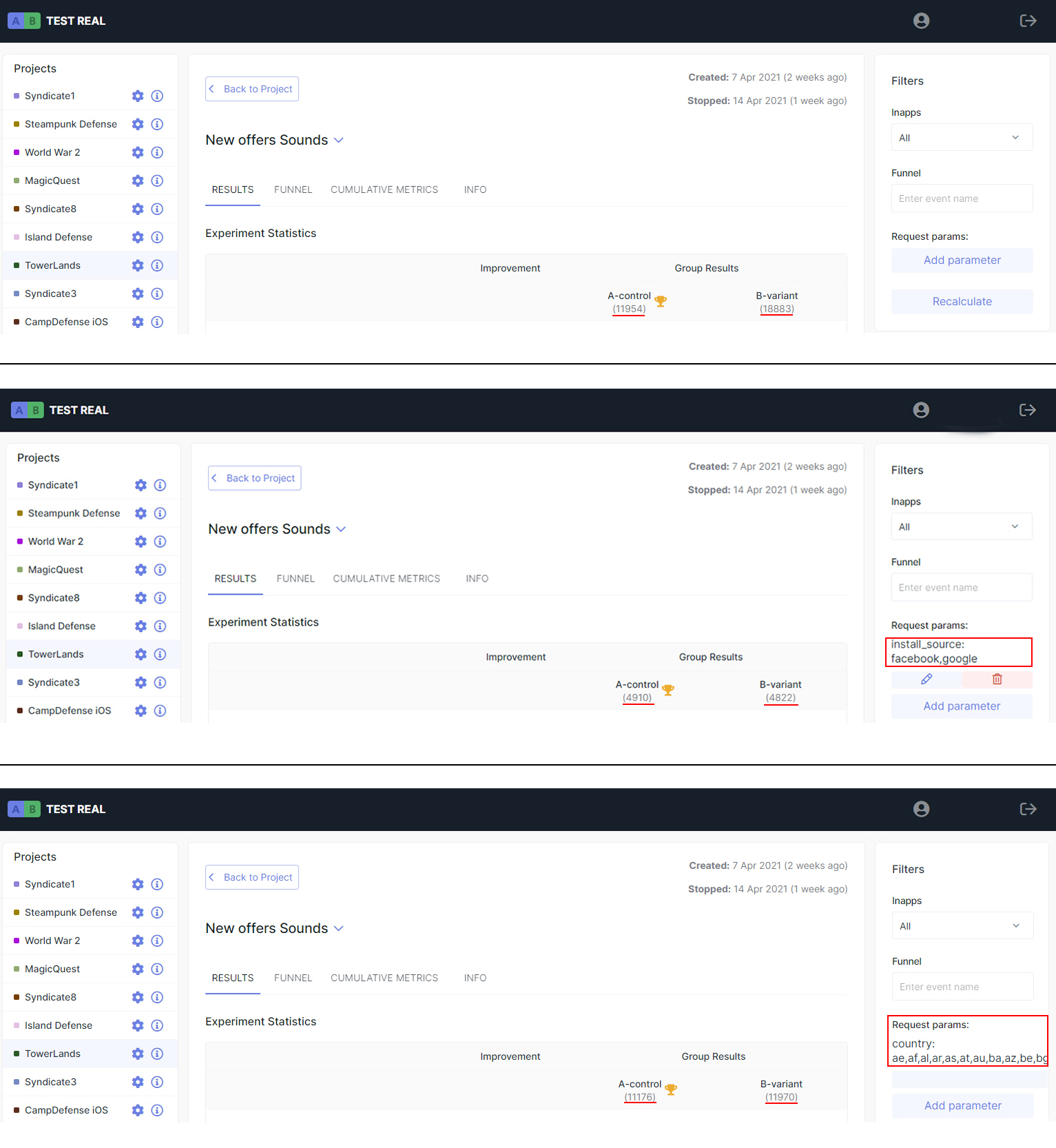
В эксперименте с обновлением мобильной игры мы увидели неравное распределение пользователей по тестируемым группам - 12 тысяч и 19 тысяч. В этом эксперименте Google Play делит трафик на равные группы: половина игроков видит старую версию игры, половина - новую. Но наши группы сильно различались по размеру.
Причина в том, что новую версию игры украли пираты, и часть игроков скачала игру с пиратского сайта, а не с Google Play. Эти игроки тоже участвуют в эксперименте и считаются частью группы с новой версией игры, составляя 37% от общего числа игроков в этой группе. При этом в группе со старой версией таких игроков нет.
Поведение игроков, скачавших игру с пиратского сайта, может отличаться от поведения остальных игроков. В результате нельзя сделать однозначный вывод о том, что стало причиной изменения целевых показателей - эксперимент или различие групп по составу.
Как исправить ситуацию? Отфильтровать выборку - убрать из нее игроков, скачавших игру с пиратского сайта.
В нашей платформе для этого используется инструмент filters. Вариантов решения с его помощью два:
1. Отфильтровать выборку по источнику установки. Оставим только тех пользователей, у которых мы точно знаем источник установки, в нашем случае это facebook, google. Выставляем в фильтре параметр install source = facebook; google; тем самым убирая установки из неизвестных источников. Получаем равные группы для обеих версий теста.
2. Отфильтровать выборку по географии установок. Мы заметили, большая часть загрузок новой версии идет из Китая. Выбираем в качестве параметра для фильтра country, в значении задаем все страны, кроме Китая, и получаем равное количество участников для разных версий, выводы по эксперименту будут корректны.
Таким образом, гибкость в работе с выборкой позволяет нам проводить эксперименты, даже когда пираты эту выборку портят.
Пираты не только воруют игры, но еще и портят тесты.
В эксперименте с обновлением мобильной игры мы увидели неравное распределение пользователей по тестируемым группам - 12 тысяч и 19 тысяч. В этом эксперименте Google Play делит трафик на равные группы: половина игроков видит старую версию игры, половина - новую. Но наши группы сильно различались по размеру.
Причина в том, что новую версию игры украли пираты, и часть игроков скачала игру с пиратского сайта, а не с Google Play. Эти игроки тоже участвуют в эксперименте и считаются частью группы с новой версией игры, составляя 37% от общего числа игроков в этой группе. При этом в группе со старой версией таких игроков нет.
Поведение игроков, скачавших игру с пиратского сайта, может отличаться от поведения остальных игроков. В результате нельзя сделать однозначный вывод о том, что стало причиной изменения целевых показателей - эксперимент или различие групп по составу.
Как исправить ситуацию? Отфильтровать выборку - убрать из нее игроков, скачавших игру с пиратского сайта.
В нашей платформе для этого используется инструмент filters. Вариантов решения с его помощью два:
1. Отфильтровать выборку по источнику установки. Оставим только тех пользователей, у которых мы точно знаем источник установки, в нашем случае это facebook, google. Выставляем в фильтре параметр install source = facebook; google; тем самым убирая установки из неизвестных источников. Получаем равные группы для обеих версий теста.
2. Отфильтровать выборку по географии установок. Мы заметили, большая часть загрузок новой версии идет из Китая. Выбираем в качестве параметра для фильтра country, в значении задаем все страны, кроме Китая, и получаем равное количество участников для разных версий, выводы по эксперименту будут корректны.
Таким образом, гибкость в работе с выборкой позволяет нам проводить эксперименты, даже когда пираты эту выборку портят.
{kind=link}
Самый популярный миф в статистике
Ron Kohavi в книге Trustworthy Online Controlled Experiments пишет: “...многие люди неверно истолковывают предположение о нормальности как предположение о выборочном показателе Y…”
Это неправильное предположение. Для применения Т-критерия выборка не должна быть нормально распределена. Нормальное распределение должно быть у среднего выборки.
Но среднее значение нормально распределено по центральной предельной теореме, а следовательно Т-критерий применим.
Интересно, что русская статья в wikipedia содержит ошибочное требование, а английская - верное.
Ron Kohavi в книге Trustworthy Online Controlled Experiments пишет: “...многие люди неверно истолковывают предположение о нормальности как предположение о выборочном показателе Y…”
Это неправильное предположение. Для применения Т-критерия выборка не должна быть нормально распределена. Нормальное распределение должно быть у среднего выборки.
Но среднее значение нормально распределено по центральной предельной теореме, а следовательно Т-критерий применим.
Интересно, что русская статья в wikipedia содержит ошибочное требование, а английская - верное.
Ребята из GameFirst Mobile разрешили рассказать об эксперименте, которые мы провели вместе с ними на игре God Simulator.
Ребята запустили эксперимент с увеличением цен на внутриигровые покупки. Завели новые in-apps в Google Play и выставили для них новые цены. Новые in-apps привязали к существующим продуктам из игры и из нашей платформы передавали в игру параметр, который определял какие in-app’ы предлагаются игроку - с новой ценой или старые.
Результаты
Количество игроков в эксперименте: 130 тысяч
ARPPU: +22%
Conversion: -20%
Вырос платеж на платящего игрока, но упала конверсия и эксперимент не показал статистической значимости в среднем доходе на игрока.
Apple недавно зафичерил игру God Simulator. Поздравляем ребят с этим событием!
Ребята запустили эксперимент с увеличением цен на внутриигровые покупки. Завели новые in-apps в Google Play и выставили для них новые цены. Новые in-apps привязали к существующим продуктам из игры и из нашей платформы передавали в игру параметр, который определял какие in-app’ы предлагаются игроку - с новой ценой или старые.
Результаты
Количество игроков в эксперименте: 130 тысяч
ARPPU: +22%
Conversion: -20%
Вырос платеж на платящего игрока, но упала конверсия и эксперимент не показал статистической значимости в среднем доходе на игрока.
Apple недавно зафичерил игру God Simulator. Поздравляем ребят с этим событием!
{kind=link}
Ron Kohavi в книге Trustworthy Online Controlled Experiments приводит приблизительную формулу для минимального размера выборки. Смотри картинку.
Сигма в числителе - среднеквадратичное отклонение. В Google Sheet - это функция stdev.
Дельта в знаменателе - разница средних, которую мы хотим увидеть.
Пример
Наши пользователи делают платежи.
Сколько пользователей должно участвовать в эксперименте, чтобы обнаружить разницу средних в платежах в 1 цент?
Стандартное отклонение в группе = 1.12
Подставляем в формулу и получаем ответ: 200 тысяч человек.
Сигма в числителе - среднеквадратичное отклонение. В Google Sheet - это функция stdev.
Дельта в знаменателе - разница средних, которую мы хотим увидеть.
Пример
Наши пользователи делают платежи.
Сколько пользователей должно участвовать в эксперименте, чтобы обнаружить разницу средних в платежах в 1 цент?
Стандартное отклонение в группе = 1.12
Подставляем в формулу и получаем ответ: 200 тысяч человек.
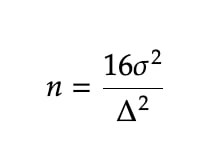{kind=link}
CUPED - это технология, которая увеличивает чувствительность А/Б экспериментов. Booking и Microsoft продвигают ее в своих статьях.
Суть метода в снижении дисперсии за счет использования данных, которые доступны ДО эксперимента. Например:
1. Вы предполагаете, что LTV у вас растет одновременно с retention.
2. Ваша основная метрика при проведении А/Б эксперимента - это LTV.
3. У вас есть прошлые данные, и по ним вы можете увидеть, что LTV и retention растут одновременно.
4. Используя CUPED, вы рассчитываете не LTV, а некую функцию f(LTV, retention), которая имеет меньшую дисперсию и за счет этого увеличивает скорость “покраски” эксперимента.
Вы проводите А/Б эксперименты быстрее, используя знание о том, что retention растет вместе с LTV.
Проблемы у вас начнутся на тех экспериментах, где retention и LTV вместе не растут. В этом случае CUPED для вас будет не методом увеличения чувствительности, а методом ее УМЕНЬШЕНИЯ.
Когда вы начинаете эксперимент, вы заранее не знаете, будет ли у вас расти retention вместе с LTV. Легко представить себе сценарии, когда эти метрики не растут одновременно.
Используя CUPED, вы быстрее завершаете эксперименты не за счет увеличения чувствительности, а за счет уменьшения точности и большего полагания на свою интуицию. Совершенно нормальная практика, но пользуйтесь с осторожностью.
Суть метода в снижении дисперсии за счет использования данных, которые доступны ДО эксперимента. Например:
1. Вы предполагаете, что LTV у вас растет одновременно с retention.
2. Ваша основная метрика при проведении А/Б эксперимента - это LTV.
3. У вас есть прошлые данные, и по ним вы можете увидеть, что LTV и retention растут одновременно.
4. Используя CUPED, вы рассчитываете не LTV, а некую функцию f(LTV, retention), которая имеет меньшую дисперсию и за счет этого увеличивает скорость “покраски” эксперимента.
Вы проводите А/Б эксперименты быстрее, используя знание о том, что retention растет вместе с LTV.
Проблемы у вас начнутся на тех экспериментах, где retention и LTV вместе не растут. В этом случае CUPED для вас будет не методом увеличения чувствительности, а методом ее УМЕНЬШЕНИЯ.
Когда вы начинаете эксперимент, вы заранее не знаете, будет ли у вас расти retention вместе с LTV. Легко представить себе сценарии, когда эти метрики не растут одновременно.
Используя CUPED, вы быстрее завершаете эксперименты не за счет увеличения чувствительности, а за счет уменьшения точности и большего полагания на свою интуицию. Совершенно нормальная практика, но пользуйтесь с осторожностью.
Ron Kohavi в книге Trustworthy Online Controlled Experiments перечисляет типы архитектуры при вызове API методов платформы для A/B экспериментов.
1 решение. Очевидное.
variant = getVariant(userID)
if(variant==Treatment) then
buttonColor = red
else
buttonColor = blue
2 решение. Параметрическое.
variant = getVariant(userID)
if(variant==Treatment) then
buttonColor = variant.getParam(“buttonColor”)
else
buttonColor = blue
В этом решении вы уже больше “доверяете” платформе. Ваш “клиент” не знает всех значений параметра, и на своей клиентской части оставляете только дефолтное значение параметра.
3 решение. Полный переход на платформу A/B-тестирования.
buttonColor = config.getParam(“buttonColor”)
В этом решении метод getParam уже содержит в себе:
1. Выдачу всех возможных значений.
2. Регистрацию пользователя в эксперименте.
3. Дефолтные значения параметров.
Какую архитектуру выбрать? Зависит от объема кода, завязанного на эксперименты, и от того, насколько вы (как программист) привыкли работать в условиях непрерывного AB-тестирования.
1 решение. Очевидное.
variant = getVariant(userID)
if(variant==Treatment) then
buttonColor = red
else
buttonColor = blue
2 решение. Параметрическое.
variant = getVariant(userID)
if(variant==Treatment) then
buttonColor = variant.getParam(“buttonColor”)
else
buttonColor = blue
В этом решении вы уже больше “доверяете” платформе. Ваш “клиент” не знает всех значений параметра, и на своей клиентской части оставляете только дефолтное значение параметра.
3 решение. Полный переход на платформу A/B-тестирования.
buttonColor = config.getParam(“buttonColor”)
В этом решении метод getParam уже содержит в себе:
1. Выдачу всех возможных значений.
2. Регистрацию пользователя в эксперименте.
3. Дефолтные значения параметров.
Какую архитектуру выбрать? Зависит от объема кода, завязанного на эксперименты, и от того, насколько вы (как программист) привыкли работать в условиях непрерывного AB-тестирования.
DevGamm опубликовал нашу лекцию "Как проводить эксперименты в мобильных играх".
1. Техническое устройство платформы
2. Работа с фродом
3. Немного о математике и симуляциях в АБ тестах
4. Результаты использования платформы
5. Наши кейсы
https://www.youtube.com/watch?v=xDHGXLj2lSU
1. Техническое устройство платформы
2. Работа с фродом
3. Немного о математике и симуляциях в АБ тестах
4. Результаты использования платформы
5. Наши кейсы
https://www.youtube.com/watch?v=xDHGXLj2lSU
YouTube
Как проводить А/Б эксперименты в мобильных играх / Дмитрий Гушин (A/B Test Real)
Дмитрий Гушин, CEO в A/B Test Real, рассказывает об устройстве платформы для А/Б тестирования, математике и статистике внутри платформы, а также приводит реальные примеры экспериментов.
#DevGAMM #геймдев #аналитика
Содержание:
0:00 – Интро
0:37 – Значимые…
#DevGAMM #геймдев #аналитика
Содержание:
0:00 – Интро
0:37 – Значимые…
Как же мы устали
от тестовых платежей. Многие наши эксперименты не красились из-за тестовых платежей, которые зашумляли данные. Приходилось вручную от них избавляться.
Сейчас наша платформа научилась отличать тестовые платежи от настоящих, и мы стали проводить эксперименты еще быстрее.
от тестовых платежей. Многие наши эксперименты не красились из-за тестовых платежей, которые зашумляли данные. Приходилось вручную от них избавляться.
Сейчас наша платформа научилась отличать тестовые платежи от настоящих, и мы стали проводить эксперименты еще быстрее.
От нас долго не было ничего слышно, но мы каждую неделю продолжаем запускать AB-тесты 🙂 Сосредоточились на запуске своих игр и подписочных приложениях. В этом канале делимся опытом user acquisition в подписочных приложениях. В нем мало теории и филосовских рассуждений, но много технических деталей интеграции. Встречайте: @web2app_subscription