
Расскажу про эксперимент из серии: “Не повторяйте дома”.
Эксперимент года.
П№%ц как страшно.
Короче, мы долго подбирались к этому эксперименту и вот 2 недели назад наконец решились. Мы откатили нашу основную игру Steampunk Defense на год назад(!) и запустили АБ эксперимент через нашу платформу на 50% аудитории. Очень страшно было запускать такой эксперимент по нескольким соображениям:
1. Откат игры - это негативный опыт для многих игроков
Не буду даже приводить эти страшные примеры. Скажу только что тут мы подготовились и на любой запрос игроков без вопросов давали доступ к читам типа “нарисуйте себе что хотите, ребята”.
2. Это потерянное бабло
Без комментариев.
3. Технически непонятная задача
Несмотря на то что игра у нас single player, она взаимодействует много с какими внешними сервисами. Ну как-то причесали старый билд.
4. Ну и самое главное
А что будет если результаты покажут что игра просела? Для нас это будет означать что обновлять игру мы вообще не умеем и надо сосредоточиться на чем-то другом (маркетинге или выпуске новых игр).
В прошлом посте я писал о результатах за год - это примерно +32% к LTV. Этот факт никуда не делся. Они корректно посчитаны, но возникает вопрос “а какая часть из этих 30% получилась благодаря платформе?”. Мы достаточно активно экспериментировали с рекламными сетками и медиацией, поэтому совершенно точно большАя часть заслуги из этих 32% - это медиация. Ну а вдруг в остальном мы вообще вредили игре.
Ладно, не буду мучать вас больше. Вот результаты:
Всего игроков в эксперименте: 20 тысяч.
Среднее LTV изменение: $0,02
In-apps 90% дов. интервал: -$0.01-$0.05
P-Value: 86.6%
Среднее Impressions изменение: -1.63
Impressions 90% дов. интервал: -2.80 - -0.89
P-Value: 100%
Если переводить на русский язык - “пока непонятно, но мы скорее не сломали ничего чем что-то сломали”
Подробные комментарии:
1. Показы просели стопроц.
Это ожидаемо. Мы осознано уменьшили кол-во рекламы в игре.
С начала года мы наращивали показы и нарастили до того что рейтинг игры стал 3.9. Для нас это вообще не проблема, но как только рейтинг просел до 3.9 - стало сложно закупать трафик.
Поэтому мы запускали серию экспериментов - искали оптимальную конфигурацию при которой и impressions не сильно просядет, и рейтинг увеличится. Там в итоге отдельная большая история вышла. Кому-то мы показываем рекламу, кому-то мы показываем диалог “поставь рейтинг”. Тема отдельного поста короче...
Короче мы потеряли 1,5 impression’а и это сделано осознано. Без тестов потеряли бы больше.
2. Кажется что in-app’ы увеличились примерно на 50%
Да, мы в принципе видим увеличение среднего по инаппам сравнивая показатели по органике в июне, но к сожалению, мы не можем дождаться завершения эксперимента и сказать математически строго, т. к. этот эксперимент сильно болезненный опыт для игрок. Рейтинг падает, игроки пишут злобные комменты. Короче, останавливаем эксперимент.
Вообщем все ОК, работаем дальше.
PS Вряд-ли бы я поделился результатами если бы они сильно просели. Хорошо что такого не произошло :)
Эксперимент года.
П№%ц как страшно.
Короче, мы долго подбирались к этому эксперименту и вот 2 недели назад наконец решились. Мы откатили нашу основную игру Steampunk Defense на год назад(!) и запустили АБ эксперимент через нашу платформу на 50% аудитории. Очень страшно было запускать такой эксперимент по нескольким соображениям:
1. Откат игры - это негативный опыт для многих игроков
Не буду даже приводить эти страшные примеры. Скажу только что тут мы подготовились и на любой запрос игроков без вопросов давали доступ к читам типа “нарисуйте себе что хотите, ребята”.
2. Это потерянное бабло
Без комментариев.
3. Технически непонятная задача
Несмотря на то что игра у нас single player, она взаимодействует много с какими внешними сервисами. Ну как-то причесали старый билд.
4. Ну и самое главное
А что будет если результаты покажут что игра просела? Для нас это будет означать что обновлять игру мы вообще не умеем и надо сосредоточиться на чем-то другом (маркетинге или выпуске новых игр).
В прошлом посте я писал о результатах за год - это примерно +32% к LTV. Этот факт никуда не делся. Они корректно посчитаны, но возникает вопрос “а какая часть из этих 30% получилась благодаря платформе?”. Мы достаточно активно экспериментировали с рекламными сетками и медиацией, поэтому совершенно точно большАя часть заслуги из этих 32% - это медиация. Ну а вдруг в остальном мы вообще вредили игре.
Ладно, не буду мучать вас больше. Вот результаты:
Всего игроков в эксперименте: 20 тысяч.
Среднее LTV изменение: $0,02
In-apps 90% дов. интервал: -$0.01-$0.05
P-Value: 86.6%
Среднее Impressions изменение: -1.63
Impressions 90% дов. интервал: -2.80 - -0.89
P-Value: 100%
Если переводить на русский язык - “пока непонятно, но мы скорее не сломали ничего чем что-то сломали”
Подробные комментарии:
1. Показы просели стопроц.
Это ожидаемо. Мы осознано уменьшили кол-во рекламы в игре.
С начала года мы наращивали показы и нарастили до того что рейтинг игры стал 3.9. Для нас это вообще не проблема, но как только рейтинг просел до 3.9 - стало сложно закупать трафик.
Поэтому мы запускали серию экспериментов - искали оптимальную конфигурацию при которой и impressions не сильно просядет, и рейтинг увеличится. Там в итоге отдельная большая история вышла. Кому-то мы показываем рекламу, кому-то мы показываем диалог “поставь рейтинг”. Тема отдельного поста короче...
Короче мы потеряли 1,5 impression’а и это сделано осознано. Без тестов потеряли бы больше.
2. Кажется что in-app’ы увеличились примерно на 50%
Да, мы в принципе видим увеличение среднего по инаппам сравнивая показатели по органике в июне, но к сожалению, мы не можем дождаться завершения эксперимента и сказать математически строго, т. к. этот эксперимент сильно болезненный опыт для игрок. Рейтинг падает, игроки пишут злобные комменты. Короче, останавливаем эксперимент.
Вообщем все ОК, работаем дальше.
PS Вряд-ли бы я поделился результатами если бы они сильно просели. Хорошо что такого не произошло :)
Считать деньги больно. Избавиться от этой боли невозможно.
Мы уменьшим боль нашими новыми фичами:
1. Антифрод для Google Play
Аккуратно собранные данные - это must для любого эксперимента. Всегда хочется видеть настоящих плательщиков, а не жуликов, которые обманом получили монетки. Теперь наша платформа умеет сама обращаться к google play с запросом “а правда ли этот игрок заплатил?”. Деньги в эксперименте считаются только в том случае если Google Play отвечает утвердительно на этот вопрос.
Просто дайте нашей платформе доступ до Google Play API вашего аккаунта, и она сама все перепроверит.
2. Конвертор валюты
Вторая проблема - это местные валюты. Один игрок потратил 1000 рублей, другой - 10 долларов. Задача сложить доллары с рублями ложится на хрупкие плечи аналитика (уже 2 месяца не держащего гантели в фитнес-зале). Наша платформа приводит все валюты к долларам. Для этого она сверяется с актуальным курсом доллара онлайн и конвертит местную валюту (рубли например).
Подключайтесь к нам и считайте деньги правильно.
А мы возвращаемся на кухню где приготовим вам что-то еще более вкусненькое!
Мы уменьшим боль нашими новыми фичами:
1. Антифрод для Google Play
Аккуратно собранные данные - это must для любого эксперимента. Всегда хочется видеть настоящих плательщиков, а не жуликов, которые обманом получили монетки. Теперь наша платформа умеет сама обращаться к google play с запросом “а правда ли этот игрок заплатил?”. Деньги в эксперименте считаются только в том случае если Google Play отвечает утвердительно на этот вопрос.
Просто дайте нашей платформе доступ до Google Play API вашего аккаунта, и она сама все перепроверит.
2. Конвертор валюты
Вторая проблема - это местные валюты. Один игрок потратил 1000 рублей, другой - 10 долларов. Задача сложить доллары с рублями ложится на хрупкие плечи аналитика (уже 2 месяца не держащего гантели в фитнес-зале). Наша платформа приводит все валюты к долларам. Для этого она сверяется с актуальным курсом доллара онлайн и конвертит местную валюту (рубли например).
Подключайтесь к нам и считайте деньги правильно.
А мы возвращаемся на кухню где приготовим вам что-то еще более вкусненькое!
Написали статью про то как определить нужное число пользователей для эксперимента
https://gushchin-dmitry.medium.com/%D1%81%D0%BA%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE-%D0%BD%D0%B0%D0%BC-%D0%BD%D0%B0%D0%B4%D0%BE-%D0%B8%D0%B3%D1%80%D0%BE%D0%BA%D0%BE%D0%B2-d569eb2582cc
https://gushchin-dmitry.medium.com/%D1%81%D0%BA%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE-%D0%BD%D0%B0%D0%BC-%D0%BD%D0%B0%D0%B4%D0%BE-%D0%B8%D0%B3%D1%80%D0%BE%D0%BA%D0%BE%D0%B2-d569eb2582cc
{kind=link}
Когда мы проводим эксперименты, мы хотим знать больше о наших игроках. И хотя нашей целью всегда была максимизация дохода LTV, мы хотим лучше понимать как изменения в игре отражаются на игроках и как меняется их поведение.
Новые данные помогут нам формулировать более качественные гипотезы в будущем.
Теперь наша платформа умеет отслеживать такие параметры в А/Б экспериментах:
ARPPU
Средний чек платящего игрока
Lifetime
Общее время в игре
Paying conversion
Конверсию в платящего игрока
Новые данные помогут нам формулировать более качественные гипотезы в будущем.
Теперь наша платформа умеет отслеживать такие параметры в А/Б экспериментах:
ARPPU
Средний чек платящего игрока
Lifetime
Общее время в игре
Paying conversion
Конверсию в платящего игрока
{kind=link}
Решил написать обзор книжек по А/Б тестированию.
Я по профессии программист, а не математик, поэтому мои оценки полезности могут быть интересны разработчикам, а не математикам.
Я предпочитаю честность политкорректности, поэтому если знания из книжки невозможно применить на практике (реализовать новую фичу) - я ставлю полезность 0.
Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing. Kohavi, Ron
Оценка: 4/5
Кохави - самый известный автор работ по АБ тестированию. Основное место работы - оптимизация Bing в Microsoft.
+ доступный язык (если вы читаете по английски)
+ реальные (а не надуманные) проблемы и задачи.
- нет ничего такого до чего невозможно догадаться самому
Наглядная математическая статистика. Лагутин Михаил
Оценка: 0/5
+ Русский язык
- Нужен сильный математический бэкграунд. Я разбирал примеры с мехматовцами. Сходу даже им непонятно о чем она.
- Примеры не из жизни. В работе применить точно не получится.
Практическая статистика для специалистов Data Science. Брюс Эндрю, Брюс Питер
Оценка: 5/5
Смелый автор. Хорошо понимает как работает bootstrap, хорошо объясняет и не стесняется творчески применять его.
+ Русский язык
+ Написана для инженеров. После книжки сразу можно писать код.
- Мало. Статистике в книжке посвящено около 5 страниц.
Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan Hardcover, John Kruschke
Оценка: 4/5
Книжка по Байесовскому анализу. Крутой филосовский трактат по разным аспектам статистики. Это почему-то общее качество для всех Байесовцов. В них всегда половина книжка - это текст без формул.
+ Очень подробно и понятно
+ Широкий список тем
- Длинная очень. Если не пролистывая читать - пару месяцев можно выделить.
Голая статистика, Чарльз Уилан
Оценка: 2/5
Хорошая книжка как введение, чтобы в общем о терминах иметь представление.
+ Русский язык
+ Все понятно
- Нет практической ценности
Статистика. Базовый курс в комиксах, Грейди Клейн
Оценка: 3/5
Хорошая книжка как введение, чтобы в общем о терминах иметь представление. Написано в точности все то же самое что и в предыдущей, но прочитать можно быстрее гораздо.
+ Русский язык
+ Все понятно
+ Очень быстро читается
- Нет практической ценности
Я по профессии программист, а не математик, поэтому мои оценки полезности могут быть интересны разработчикам, а не математикам.
Я предпочитаю честность политкорректности, поэтому если знания из книжки невозможно применить на практике (реализовать новую фичу) - я ставлю полезность 0.
Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing. Kohavi, Ron
Оценка: 4/5
Кохави - самый известный автор работ по АБ тестированию. Основное место работы - оптимизация Bing в Microsoft.
+ доступный язык (если вы читаете по английски)
+ реальные (а не надуманные) проблемы и задачи.
- нет ничего такого до чего невозможно догадаться самому
Наглядная математическая статистика. Лагутин Михаил
Оценка: 0/5
+ Русский язык
- Нужен сильный математический бэкграунд. Я разбирал примеры с мехматовцами. Сходу даже им непонятно о чем она.
- Примеры не из жизни. В работе применить точно не получится.
Практическая статистика для специалистов Data Science. Брюс Эндрю, Брюс Питер
Оценка: 5/5
Смелый автор. Хорошо понимает как работает bootstrap, хорошо объясняет и не стесняется творчески применять его.
+ Русский язык
+ Написана для инженеров. После книжки сразу можно писать код.
- Мало. Статистике в книжке посвящено около 5 страниц.
Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan Hardcover, John Kruschke
Оценка: 4/5
Книжка по Байесовскому анализу. Крутой филосовский трактат по разным аспектам статистики. Это почему-то общее качество для всех Байесовцов. В них всегда половина книжка - это текст без формул.
+ Очень подробно и понятно
+ Широкий список тем
- Длинная очень. Если не пролистывая читать - пару месяцев можно выделить.
Голая статистика, Чарльз Уилан
Оценка: 2/5
Хорошая книжка как введение, чтобы в общем о терминах иметь представление.
+ Русский язык
+ Все понятно
- Нет практической ценности
Статистика. Базовый курс в комиксах, Грейди Клейн
Оценка: 3/5
Хорошая книжка как введение, чтобы в общем о терминах иметь представление. Написано в точности все то же самое что и в предыдущей, но прочитать можно быстрее гораздо.
+ Русский язык
+ Все понятно
+ Очень быстро читается
- Нет практической ценности
Нас часто спрашивают:
Как провести А/Б эксперимент с наименьшим ущербом для бизнеса?
Кратко: никак.
Теперь чуть подробнее:
Рассмотрим проблему чуть подробнее. У нас есть какая-то рискованная гипотеза. Мы боимся что потеряем существенную часть дохода работающего продукта пока будем ее проверять. Какие у нас есть варианты?
1. Запустить эксперимент на 5% аудитории
При классической схеме мы запускаем эксперимент на 50%. Интуитивно кажется что запуская эксперимент на 5% результаты эксперимента мы будем получать примерно в 10 раз медленнее (на самом деле будет еще медленнее - мощность падает нелинейно).
Наша глобальная цель как бизнеса - откручивать много экспериментов и делать это быстро. Пока мы "возимся" с экспериментом который, как нам кажется, принесет убытки, мы теряем возможность запустить другие эксперименты, которые стоят в очереди и лишают нас возможности зарабатывать больше.
2. Запустить эксперимент на какое-то подмножество пользователей
Ну например: "У нас есть пользователи из 150 стран. Давайте запустим для начала на Бразилию? Там доход не большой. Соответственно потери незначительные. Если покажет себя хорошо - выкатим на 100%".
С уверенностью можно сказать что пользователи Бразилии отличаются от пользователей в Штатах, поэтому предложение выше преобразовывается в "Давайте если в Бразилии прокатит, выкатим на 100% в Штаты не проверяя!". Это странно - я бы предпочел запустить на Штатах тоже на 50% сначала.
3. Не запускать АБ тест
Без комментариев.
Итого:
По умолчанию эксперименты запускаются на 50% вашей аудитории. Исключение - случаи когда вы понимаете что делаете и что выигрываете/теряете.
Хорошие новости: достаточно сложно даже придумать эксперимент который обрушит вам выручку, скажем на 25%. Это очень постараться надо.
Падение в 25% на 50% аудитории конвертируются в падение 12.5% от общей выручки. Помните что вы на половину пользователей запускаете? Фактически это и есть верхняя граница оценки риска.
Удачного тестирования!
Как провести А/Б эксперимент с наименьшим ущербом для бизнеса?
Кратко: никак.
Теперь чуть подробнее:
Рассмотрим проблему чуть подробнее. У нас есть какая-то рискованная гипотеза. Мы боимся что потеряем существенную часть дохода работающего продукта пока будем ее проверять. Какие у нас есть варианты?
1. Запустить эксперимент на 5% аудитории
При классической схеме мы запускаем эксперимент на 50%. Интуитивно кажется что запуская эксперимент на 5% результаты эксперимента мы будем получать примерно в 10 раз медленнее (на самом деле будет еще медленнее - мощность падает нелинейно).
Наша глобальная цель как бизнеса - откручивать много экспериментов и делать это быстро. Пока мы "возимся" с экспериментом который, как нам кажется, принесет убытки, мы теряем возможность запустить другие эксперименты, которые стоят в очереди и лишают нас возможности зарабатывать больше.
2. Запустить эксперимент на какое-то подмножество пользователей
Ну например: "У нас есть пользователи из 150 стран. Давайте запустим для начала на Бразилию? Там доход не большой. Соответственно потери незначительные. Если покажет себя хорошо - выкатим на 100%".
С уверенностью можно сказать что пользователи Бразилии отличаются от пользователей в Штатах, поэтому предложение выше преобразовывается в "Давайте если в Бразилии прокатит, выкатим на 100% в Штаты не проверяя!". Это странно - я бы предпочел запустить на Штатах тоже на 50% сначала.
3. Не запускать АБ тест
Без комментариев.
Итого:
По умолчанию эксперименты запускаются на 50% вашей аудитории. Исключение - случаи когда вы понимаете что делаете и что выигрываете/теряете.
Хорошие новости: достаточно сложно даже придумать эксперимент который обрушит вам выручку, скажем на 25%. Это очень постараться надо.
Падение в 25% на 50% аудитории конвертируются в падение 12.5% от общей выручки. Помните что вы на половину пользователей запускаете? Фактически это и есть верхняя граница оценки риска.
Удачного тестирования!
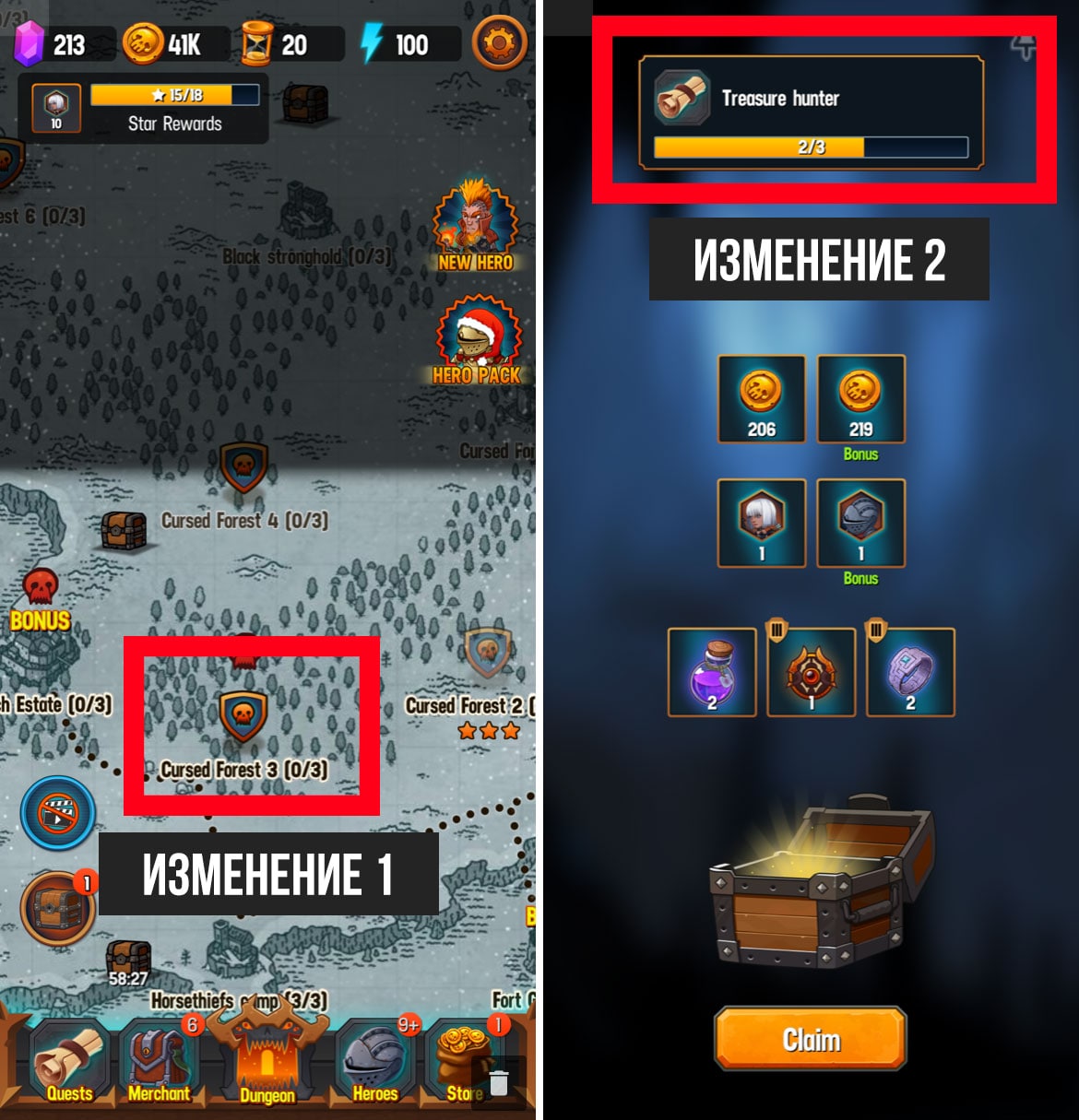
Эксперимент UI в мобильной игре
Нам бывает сложно предсказать результаты экспериментов. Мы планируем улучшить рекламную монетизацию, а по факту увеличиваем доход с инапов.
На прошлой неделе мы завершили такой эксперимент.
Описание:
У нас есть tower defense игра про вторую мировую войну с уровнями. Когда игрок проходит уровень, он получает награду. У игрока есть возможность удвоить эту награду если он посмотрит рекламу.
Гипотеза:
Сейчас соотношение “награды до просмотра рекламы” к “награде после просмотра рекламы” - 50/50. Возможно изменение этого соотношения на 80/20 мотивирует игроков смотреть больше рекламу.
Меняем UI как на скриншоте.
Результат:
Inapp’ы выросли примерно в полтора раза.
Вывод:
Да, мы плохие предсказатели.
Значит будем запускать еще больше экспериментов.
Нам бывает сложно предсказать результаты экспериментов. Мы планируем улучшить рекламную монетизацию, а по факту увеличиваем доход с инапов.
На прошлой неделе мы завершили такой эксперимент.
Описание:
У нас есть tower defense игра про вторую мировую войну с уровнями. Когда игрок проходит уровень, он получает награду. У игрока есть возможность удвоить эту награду если он посмотрит рекламу.
Гипотеза:
Сейчас соотношение “награды до просмотра рекламы” к “награде после просмотра рекламы” - 50/50. Возможно изменение этого соотношения на 80/20 мотивирует игроков смотреть больше рекламу.
Меняем UI как на скриншоте.
Результат:
Inapp’ы выросли примерно в полтора раза.
Вывод:
Да, мы плохие предсказатели.
Значит будем запускать еще больше экспериментов.
{kind=link}
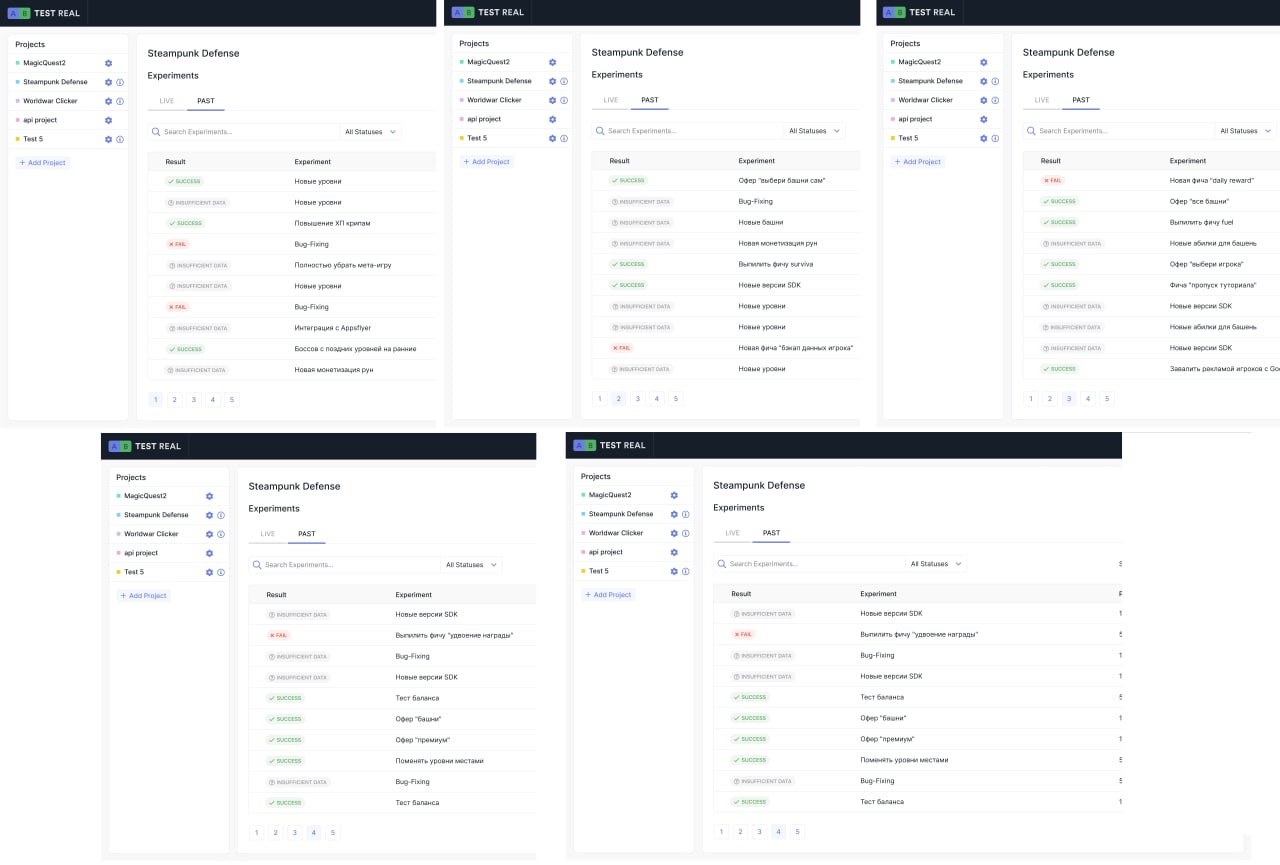
Итоги 2020
Подведем итоги 2020 года на примере игры Steampunk Defense.
За 2020 год мы запустили 44 теста.
LTV/User с $0.67 до $1.12
В этом году мы окончательно отладили нашу платформу abtestreal.com. Теперь мы можем запускать эксперименты без других сервисов (например, Firebase).
Выводы
1. Мы запускаем много тестов на баланс.
Подбираем оптимальную сложность уровней в игре.
2. Большинство тестов не имеют статистически значимых результатов.
Мы смотрим на фичи. Если это обновление SDK или фикс критического бага, то мы выкатываем, даже если статистически значимого результата нет. Если это не жизненно важная фича, то откатываем.
3. Да, баги мы фиксим тоже в рамках АВ-эксперимента.
Часто баги сильно задевают экономику игру, поэтому на них мы часто огребаем фейл. С первого раза не всегда удается выкатить фикс.
4. Много новых фич не дали результата. Мы об этом быстро узнавали и понимали, куда двигаться дальше.
5. А вот когда мы что-то убираем, это, наоборот, часто "успех".
6. В большинстве тестов нет стат. значимости.
Несмотря на то, что эксперимент заканчивается со статусом “неизвестно”, мы видим, как меняется воронка, и используем эти данные в будущих экспериментах. Например, полное выпиливание метаигры улучшило конверсию на ранних стадиях игры, но ухудшило на поздних. Поэтому есть смысл попробовать запускать мета игру на поздних уровнях.
С наступающим 2021 и побольше вам тестов!
Подведем итоги 2020 года на примере игры Steampunk Defense.
За 2020 год мы запустили 44 теста.
LTV/User с $0.67 до $1.12
В этом году мы окончательно отладили нашу платформу abtestreal.com. Теперь мы можем запускать эксперименты без других сервисов (например, Firebase).
Выводы
1. Мы запускаем много тестов на баланс.
Подбираем оптимальную сложность уровней в игре.
2. Большинство тестов не имеют статистически значимых результатов.
Мы смотрим на фичи. Если это обновление SDK или фикс критического бага, то мы выкатываем, даже если статистически значимого результата нет. Если это не жизненно важная фича, то откатываем.
3. Да, баги мы фиксим тоже в рамках АВ-эксперимента.
Часто баги сильно задевают экономику игру, поэтому на них мы часто огребаем фейл. С первого раза не всегда удается выкатить фикс.
4. Много новых фич не дали результата. Мы об этом быстро узнавали и понимали, куда двигаться дальше.
5. А вот когда мы что-то убираем, это, наоборот, часто "успех".
6. В большинстве тестов нет стат. значимости.
Несмотря на то, что эксперимент заканчивается со статусом “неизвестно”, мы видим, как меняется воронка, и используем эти данные в будущих экспериментах. Например, полное выпиливание метаигры улучшило конверсию на ранних стадиях игры, но ухудшило на поздних. Поэтому есть смысл попробовать запускать мета игру на поздних уровнях.
С наступающим 2021 и побольше вам тестов!
{kind=link}
Статья о байесовском подходе. Она поверхностная и будет неинтересна людям, глубоко погруженным в статистику. Глобально в мире статистики есть 2 подхода: частотный и байесовский.
Частотный подход
Подход возник в 20 веке. Главные имена - Госсет (автор критерия Стьюдента), Пирсон и Фишер.
В целом идея такая: допустим, у вас есть какая-то выборка (размеры ног случайно отобранных жителей Земли 38, 42.5, 36, 40 и т.д.).
И у вас есть какие-то параметры.
Пример: вы знаете, что размеры ног нормально распределены. Нормальное распределение - это такой “колокол”. С точки зрения математики этот “колокол” обладает разными интересными свойствами, но мы не будем углубляться в это.
Подходы типа t-test (критерий Стьюдента), z-score, бутстрапа и дальше из всего набора отвечают на вопрос: “Насколько данная выборка соответствует параметрам?”.
Пример: “Насколько вот этот набор размеров ног похож на нормальное распределение?”. Зная параметры распределения и имея на руках данные, вы делаете статистические выводы.
Байесовский подход
Байес жил в 18 веке, т.е. за 200 лет до Фишера. Он сформулировал теорему, которая позволяет вычислить вероятность события при условии другого события.
Пример: у вас есть вероятность “быть блондином при условии, что глаза у вас голубые”. Найти вероятность “голубоглазости при условии, что блондин”.
На первый взгляд, не очень понятно, как это применять. Но современные статистики придумали такую формулировку: “найти вероятность таких данных при условии, что их параметры (смотри выше) вот такие”. На выходе байесовский подход отдает параметры распределения.
Обратите внимание на разницу между подходами:
В частотном подходе параметры распределения заданы. В байесовском они вычисляются.
В чем отличие для нас как пользователей подходов?
Частотный метод
Работая с частотным методом (например критерий Стьюдента) и, подавая ему на вход 2 гипотезы, вы получаете ответ на вопрос: “Какова вероятность увидеть эти данные при условии верности нулевой гипотезы?”. Гипотеза принимается, если вероятность “нулевой гипотезы” (ничего не произошло) <5% (или как говорят p-value <0.05).
Пример: у вас есть синяя кнопка и есть гипотеза “зеленая кнопка улучшает конверсию”. Вы проводите АВ-эксперимент, меняете цвет кнопки, смотрите в данные и задаете себе вопрос выше. Данные такие же как и при синей.
Вывод: мы не можем откинуть нулевую гипотезу. На этом все. Стоит ли вам перекрашивать кнопку в зеленый цвет? Частотный подход не дает ответа.
Байесовский метод
Байесовский метод в примере с кнопкой работает по-другому. Если ему на вход дать те же самые данные, он скажет: “Вероятность, что синяя кнопка лучше - 50%. Вероятность, что зеленая кнопка лучше - тоже 50%”. Короче, “хочешь перекрашивай, хочешь - не перекрашивай”.
Применимость
Для науки
вы используете частотный подход. Если вы утверждаете, что земля квадратная, то вы должны собрать достаточно данных, чтобы отрицать нулевую гипотезу о круглости земли.
Пример: Вы находитесь в своей квартире. У вас есть гипотеза: “земля квадратная”. В частотном подходе вы откидываете эту гипотезу, т. к. все ваши данные не противоречат идее о том, что “земля круглая”.
В бизнесе
вы вполне можете использовать Байеса. В примере с квартирой: “Мы сейчас находимся в квартире и вполне можем считать, что Земля квадратная. Ничего от этого в нашей жизни не изменится”.
Байесовский подход выдает: “Вероятность лучшести этой гипотезы 62%” и мы можем принимать гипотезы, которые не подтверждаются частотным подходом.
Почти все современные платформы АВ-тестирования используют байесовский метод из-за большей наглядности выводов для бизнеса. Интересно, что мир отказывается от подходов 20 века и начинает использовать методы, которые были придуманы еще в 18 веке.
Частотный подход
Подход возник в 20 веке. Главные имена - Госсет (автор критерия Стьюдента), Пирсон и Фишер.
В целом идея такая: допустим, у вас есть какая-то выборка (размеры ног случайно отобранных жителей Земли 38, 42.5, 36, 40 и т.д.).
И у вас есть какие-то параметры.
Пример: вы знаете, что размеры ног нормально распределены. Нормальное распределение - это такой “колокол”. С точки зрения математики этот “колокол” обладает разными интересными свойствами, но мы не будем углубляться в это.
Подходы типа t-test (критерий Стьюдента), z-score, бутстрапа и дальше из всего набора отвечают на вопрос: “Насколько данная выборка соответствует параметрам?”.
Пример: “Насколько вот этот набор размеров ног похож на нормальное распределение?”. Зная параметры распределения и имея на руках данные, вы делаете статистические выводы.
Байесовский подход
Байес жил в 18 веке, т.е. за 200 лет до Фишера. Он сформулировал теорему, которая позволяет вычислить вероятность события при условии другого события.
Пример: у вас есть вероятность “быть блондином при условии, что глаза у вас голубые”. Найти вероятность “голубоглазости при условии, что блондин”.
На первый взгляд, не очень понятно, как это применять. Но современные статистики придумали такую формулировку: “найти вероятность таких данных при условии, что их параметры (смотри выше) вот такие”. На выходе байесовский подход отдает параметры распределения.
Обратите внимание на разницу между подходами:
В частотном подходе параметры распределения заданы. В байесовском они вычисляются.
В чем отличие для нас как пользователей подходов?
Частотный метод
Работая с частотным методом (например критерий Стьюдента) и, подавая ему на вход 2 гипотезы, вы получаете ответ на вопрос: “Какова вероятность увидеть эти данные при условии верности нулевой гипотезы?”. Гипотеза принимается, если вероятность “нулевой гипотезы” (ничего не произошло) <5% (или как говорят p-value <0.05).
Пример: у вас есть синяя кнопка и есть гипотеза “зеленая кнопка улучшает конверсию”. Вы проводите АВ-эксперимент, меняете цвет кнопки, смотрите в данные и задаете себе вопрос выше. Данные такие же как и при синей.
Вывод: мы не можем откинуть нулевую гипотезу. На этом все. Стоит ли вам перекрашивать кнопку в зеленый цвет? Частотный подход не дает ответа.
Байесовский метод
Байесовский метод в примере с кнопкой работает по-другому. Если ему на вход дать те же самые данные, он скажет: “Вероятность, что синяя кнопка лучше - 50%. Вероятность, что зеленая кнопка лучше - тоже 50%”. Короче, “хочешь перекрашивай, хочешь - не перекрашивай”.
Применимость
Для науки
вы используете частотный подход. Если вы утверждаете, что земля квадратная, то вы должны собрать достаточно данных, чтобы отрицать нулевую гипотезу о круглости земли.
Пример: Вы находитесь в своей квартире. У вас есть гипотеза: “земля квадратная”. В частотном подходе вы откидываете эту гипотезу, т. к. все ваши данные не противоречат идее о том, что “земля круглая”.
В бизнесе
вы вполне можете использовать Байеса. В примере с квартирой: “Мы сейчас находимся в квартире и вполне можем считать, что Земля квадратная. Ничего от этого в нашей жизни не изменится”.
Байесовский подход выдает: “Вероятность лучшести этой гипотезы 62%” и мы можем принимать гипотезы, которые не подтверждаются частотным подходом.
Почти все современные платформы АВ-тестирования используют байесовский метод из-за большей наглядности выводов для бизнеса. Интересно, что мир отказывается от подходов 20 века и начинает использовать методы, которые были придуманы еще в 18 веке.
Как провести АВ эксперимент в 2 раза быстрее
Зачем это?
Как сказал Джефф Безос: “Успех Amazon обусловлен тем, сколько экспериментов мы проводим каждый год, месяц, неделю и день”.
Если мы найдем способ проводить больше экспериментов, то мы будем больше зарабатывать. Это очевидное утверждение, но непонятно, как мы можем проводить еще больше экспериментов.
Задача
Мы ограничены числом пользователей. Если мы знаем, что
1. для эксперимента нам надо 14 тысяч пользователей,
2. и количество ежедневных новых пользователей - 2000,
То для эксперимента нам нужна как минимум неделя. Как запустить больше экспериментов при заданных условиях?
Решение
Один из способов - запуск нескольких одновременных экспериментов.
Мы делаем мобильные игры, и сейчас в наших играх в любой момент времени запущено как минимум 2 активных эксперимента:
1. Новая фича
2. Тест на баланс
Длительность двух активных экспериментов никак не связана. Обычно мы быстро проверяем новую фичу и долго тестим баланс.
Где надо быть осторожным
Запускать эксперименты последовательно - не то же самое, что запускать их одновременно.
“Найти максимальное значение метрики при условии, что сначала запущен эксперимент А, а потом запущен эксперимент Б” ч
не то же самое, что
“Найти максимальное значение метрики при условии, что А и Б запущены одновременно”.
Мы стараемся запускать такие эксперименты, которые вряд ли повлияют друг на друга.
Как провести АВ эксперимент в 2 раза быстрее?
Запускать одновременно 2 эксперимента!
Зачем это?
Как сказал Джефф Безос: “Успех Amazon обусловлен тем, сколько экспериментов мы проводим каждый год, месяц, неделю и день”.
Если мы найдем способ проводить больше экспериментов, то мы будем больше зарабатывать. Это очевидное утверждение, но непонятно, как мы можем проводить еще больше экспериментов.
Задача
Мы ограничены числом пользователей. Если мы знаем, что
1. для эксперимента нам надо 14 тысяч пользователей,
2. и количество ежедневных новых пользователей - 2000,
То для эксперимента нам нужна как минимум неделя. Как запустить больше экспериментов при заданных условиях?
Решение
Один из способов - запуск нескольких одновременных экспериментов.
Мы делаем мобильные игры, и сейчас в наших играх в любой момент времени запущено как минимум 2 активных эксперимента:
1. Новая фича
2. Тест на баланс
Длительность двух активных экспериментов никак не связана. Обычно мы быстро проверяем новую фичу и долго тестим баланс.
Где надо быть осторожным
Запускать эксперименты последовательно - не то же самое, что запускать их одновременно.
“Найти максимальное значение метрики при условии, что сначала запущен эксперимент А, а потом запущен эксперимент Б” ч
не то же самое, что
“Найти максимальное значение метрики при условии, что А и Б запущены одновременно”.
Мы стараемся запускать такие эксперименты, которые вряд ли повлияют друг на друга.
Как провести АВ эксперимент в 2 раза быстрее?
Запускать одновременно 2 эксперимента!
Как лгать при помощи статистики
Хафф Дарелл - автор книги "Как лгать при помощи статистики". Книга скорее не о статистике, а о манипуляциях СМИ. Автор на примерах показывает как можно за уши притянуть статистику и доказать все что угодно.
Оказывается Хафф Дарелл на деньги табачной индустрии писал книгу (но не закончил) "Как лгать при помощи статистики курения". В книге критиковалась статистика вреда табака. Автор занимался пропагандой пользы курения.
Как говорится: легко врать с помощью статистики, но без статистики - еще легче.
Хафф Дарелл - автор книги "Как лгать при помощи статистики". Книга скорее не о статистике, а о манипуляциях СМИ. Автор на примерах показывает как можно за уши притянуть статистику и доказать все что угодно.
Оказывается Хафф Дарелл на деньги табачной индустрии писал книгу (но не закончил) "Как лгать при помощи статистики курения". В книге критиковалась статистика вреда табака. Автор занимался пропагандой пользы курения.
Как говорится: легко врать с помощью статистики, но без статистики - еще легче.
Кратко про нашу историю с АВ-тестами в 5 постах
1. Как мы запускали первые АВ-тесты
https://t.me/abtestingmobilegames/2
2. Что изменилось после внедрения AB-тестов
https://t.me/abtestingmobilegames/11
3. Как жулики помогают нам больше зарабатывать
https://t.me/abtestingmobilegames/18
4. Какие книги изучали
https://t.me/abtestingmobilegames/35
5. Как вырастили LTV на 50%
https://t.me/abtestingmobilegames/38
1. Как мы запускали первые АВ-тесты
https://t.me/abtestingmobilegames/2
2. Что изменилось после внедрения AB-тестов
https://t.me/abtestingmobilegames/11
3. Как жулики помогают нам больше зарабатывать
https://t.me/abtestingmobilegames/18
4. Какие книги изучали
https://t.me/abtestingmobilegames/35
5. Как вырастили LTV на 50%
https://t.me/abtestingmobilegames/38
Telegram
A/B-тестирование в мобильных играх
Как мы внедрили АБ тестирование в наших играх
Кто мы
Мы в Stereo7 Games делаем стратегии в жанре tower defense. Наш текущий главный проект - это игра Steampunk Defense: https://play.google.com/store/apps/details…. При разработке, мы уже более 2-ух лет активно…
Кто мы
Мы в Stereo7 Games делаем стратегии в жанре tower defense. Наш текущий главный проект - это игра Steampunk Defense: https://play.google.com/store/apps/details…. При разработке, мы уже более 2-ух лет активно…
Студия “4fan studio games” разрешила рассказать нам об эксперименте, который они запустили вместе с нами.
Ребята делают RPG-рогалик в фэнтази сеттинге. Google Play: Dungeon: Age Of Heroes. В новом апдейте к игре:
1. Поменяли систему уровней. Добавили “этажи” для них.
2. Добавили на каждый последний этаж мини-босса.
3. Улучшили генератор уровней.
Посмотрим, что стало с метриками:
1. Всего игроков в эксперименте: 5000
2. Покупки внутриигровой валюты: без изменений
3. Среднее число показов рекламы на игрока: Статистически значимое улучшение. Было: 17.5, Стало: 20.31
4. 1-day retention: -1.66%
5. Lifetime: от -6 до -1 часа игры
Новый апдейт игроки восприняли как paywall. Они стали чуть меньше времени проводить в игре, но примерно на 17% больше смотреть рекламу.
“4fan studio games”, поздравляем вас с отличным результатом!
Нам очень приятно быть частью вашей истории!
Ребята делают RPG-рогалик в фэнтази сеттинге. Google Play: Dungeon: Age Of Heroes. В новом апдейте к игре:
1. Поменяли систему уровней. Добавили “этажи” для них.
2. Добавили на каждый последний этаж мини-босса.
3. Улучшили генератор уровней.
Посмотрим, что стало с метриками:
1. Всего игроков в эксперименте: 5000
2. Покупки внутриигровой валюты: без изменений
3. Среднее число показов рекламы на игрока: Статистически значимое улучшение. Было: 17.5, Стало: 20.31
4. 1-day retention: -1.66%
5. Lifetime: от -6 до -1 часа игры
Новый апдейт игроки восприняли как paywall. Они стали чуть меньше времени проводить в игре, но примерно на 17% больше смотреть рекламу.
“4fan studio games”, поздравляем вас с отличным результатом!
Нам очень приятно быть частью вашей истории!
{kind=link}
A/B-тестирование в мобильных играх pinned «Кратко про нашу историю с АВ-тестами в 5 постах 1. Как мы запускали первые АВ-тесты https://t.me/abtestingmobilegames/2 2. Что изменилось после внедрения AB-тестов https://t.me/abtestingmobilegames/11 3. Как жулики помогают нам больше зарабатывать ht…»
Anti-fraud
На любую надежную и стройную систему всегда найдется ломатель. Там, где есть товар, всегда есть вор.
Работая с разными системами аналитики, мы заметили отличие суммы на графиках и суммы выплат платформы (App Store или Google Play). Причина простая - fraud. Игрок обманывает игру и получает контент бесплатно.
Техническая сторона чаще всего такая:
1. Жулик скачивает приложение, которое стоит между вызовами игры и Google Play.
2. Жулик делает в игре запрос на покупку.
3. Подключается промежуточное приложение, которое принимает этот запрос и высылает игре подтверждение оплаты.
4. Игра, ничего не подозревая, выдает жулику внутриигровой контент.
5. Жулик счастлив.
Решение простое - перед шагом 4 ваше приложение отправляет запрос на сервер, про который не знает приложение жулика, для проверки транзакции. В нашей платформе, например, такой сценарий реализован и для Android, и для Apple. Все транзакции проверяются на валидность - метрики в экспериментах честные.
На любую надежную и стройную систему всегда найдется ломатель. Там, где есть товар, всегда есть вор.
Работая с разными системами аналитики, мы заметили отличие суммы на графиках и суммы выплат платформы (App Store или Google Play). Причина простая - fraud. Игрок обманывает игру и получает контент бесплатно.
Техническая сторона чаще всего такая:
1. Жулик скачивает приложение, которое стоит между вызовами игры и Google Play.
2. Жулик делает в игре запрос на покупку.
3. Подключается промежуточное приложение, которое принимает этот запрос и высылает игре подтверждение оплаты.
4. Игра, ничего не подозревая, выдает жулику внутриигровой контент.
5. Жулик счастлив.
Решение простое - перед шагом 4 ваше приложение отправляет запрос на сервер, про который не знает приложение жулика, для проверки транзакции. В нашей платформе, например, такой сценарий реализован и для Android, и для Apple. Все транзакции проверяются на валидность - метрики в экспериментах честные.
Как не потерять деньги и спать спокойно.
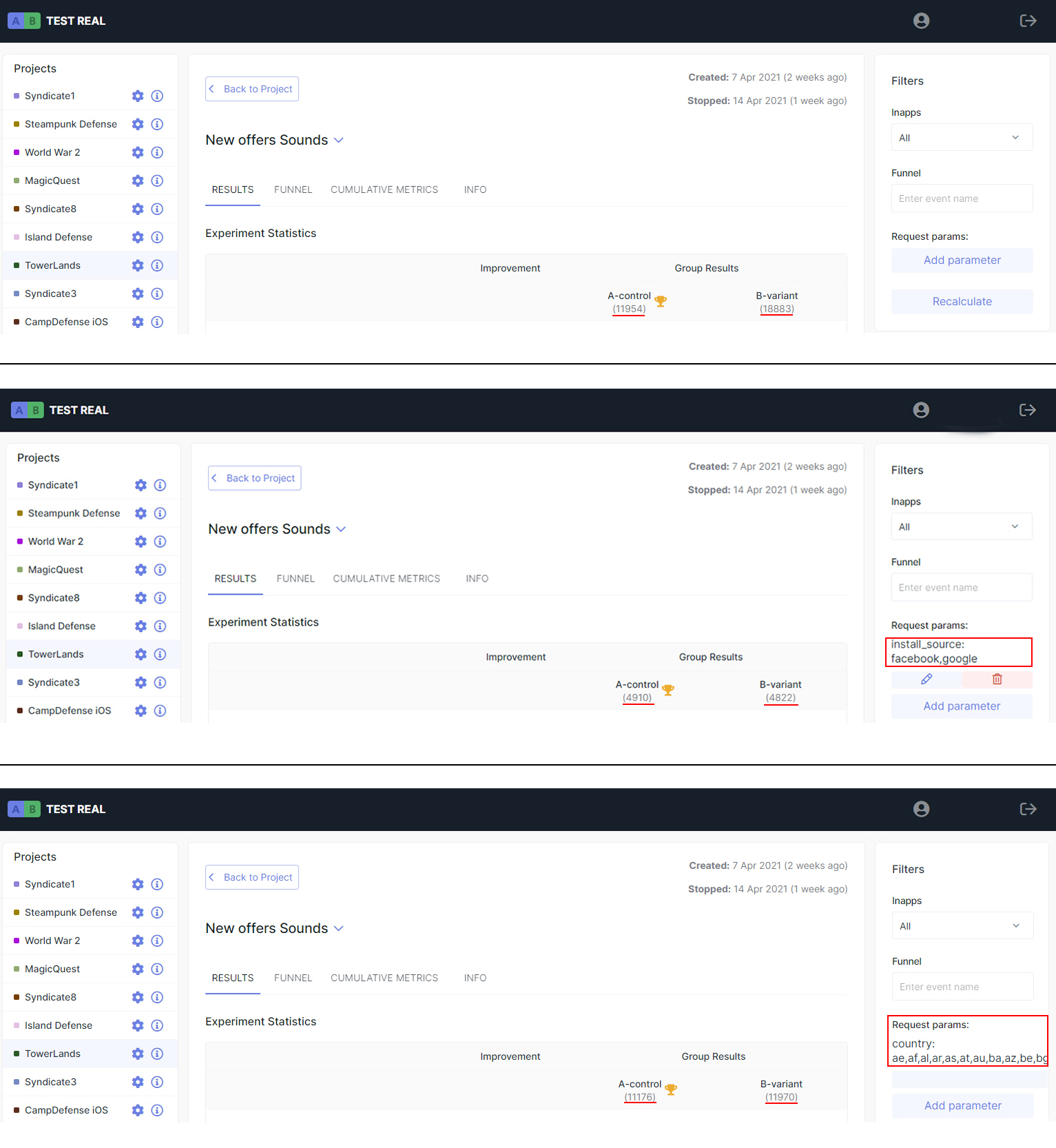
Мобильная игра нашего клиента уже приносит деньги. Он обновляет игру и боится потерять деньги, если обновление не понравится игрокам. Запускать классический АБ эксперимент на 50% аудитории клиент не хочет, т.к. потери на такой части игроков уже болезненны.
Воспользуемся инструментом audience в нашей платформе:
1. Запустим эксперимент на 10% игроков.
Свойство exposure устанавливает долю игроков, которые участвуют в эксперименте. Остальная часть игроков не увидит изменений, а значит деньги клиент не теряет.
2. Запустим эксперимент на когорте игроков.
У клиента 80% дохода - это игроки из фейсбука. Запустим эксперимент на игроках, которые пришли не с фейсбука. Для этого установим параметр install source = unity. Только игроки, которые пришли в игру из рекламной сетки unity, попадут в эксперимент.
На картинке 2 заполненных поля exposure и install source. Они подарили клиенту спокойный сон.
Мобильная игра нашего клиента уже приносит деньги. Он обновляет игру и боится потерять деньги, если обновление не понравится игрокам. Запускать классический АБ эксперимент на 50% аудитории клиент не хочет, т.к. потери на такой части игроков уже болезненны.
Воспользуемся инструментом audience в нашей платформе:
1. Запустим эксперимент на 10% игроков.
Свойство exposure устанавливает долю игроков, которые участвуют в эксперименте. Остальная часть игроков не увидит изменений, а значит деньги клиент не теряет.
2. Запустим эксперимент на когорте игроков.
У клиента 80% дохода - это игроки из фейсбука. Запустим эксперимент на игроках, которые пришли не с фейсбука. Для этого установим параметр install source = unity. Только игроки, которые пришли в игру из рекламной сетки unity, попадут в эксперимент.
На картинке 2 заполненных поля exposure и install source. Они подарили клиенту спокойный сон.
Пираты тестам не помеха
Пираты не только воруют игры, но еще и портят тесты.
В эксперименте с обновлением мобильной игры мы увидели неравное распределение пользователей по тестируемым группам - 12 тысяч и 19 тысяч. В этом эксперименте Google Play делит трафик на равные группы: половина игроков видит старую версию игры, половина - новую. Но наши группы сильно различались по размеру.
Причина в том, что новую версию игры украли пираты, и часть игроков скачала игру с пиратского сайта, а не с Google Play. Эти игроки тоже участвуют в эксперименте и считаются частью группы с новой версией игры, составляя 37% от общего числа игроков в этой группе. При этом в группе со старой версией таких игроков нет.
Поведение игроков, скачавших игру с пиратского сайта, может отличаться от поведения остальных игроков. В результате нельзя сделать однозначный вывод о том, что стало причиной изменения целевых показателей - эксперимент или различие групп по составу.
Как исправить ситуацию? Отфильтровать выборку - убрать из нее игроков, скачавших игру с пиратского сайта.
В нашей платформе для этого используется инструмент filters. Вариантов решения с его помощью два:
1. Отфильтровать выборку по источнику установки. Оставим только тех пользователей, у которых мы точно знаем источник установки, в нашем случае это facebook, google. Выставляем в фильтре параметр install source = facebook; google; тем самым убирая установки из неизвестных источников. Получаем равные группы для обеих версий теста.
2. Отфильтровать выборку по географии установок. Мы заметили, большая часть загрузок новой версии идет из Китая. Выбираем в качестве параметра для фильтра country, в значении задаем все страны, кроме Китая, и получаем равное количество участников для разных версий, выводы по эксперименту будут корректны.
Таким образом, гибкость в работе с выборкой позволяет нам проводить эксперименты, даже когда пираты эту выборку портят.
Пираты не только воруют игры, но еще и портят тесты.
В эксперименте с обновлением мобильной игры мы увидели неравное распределение пользователей по тестируемым группам - 12 тысяч и 19 тысяч. В этом эксперименте Google Play делит трафик на равные группы: половина игроков видит старую версию игры, половина - новую. Но наши группы сильно различались по размеру.
Причина в том, что новую версию игры украли пираты, и часть игроков скачала игру с пиратского сайта, а не с Google Play. Эти игроки тоже участвуют в эксперименте и считаются частью группы с новой версией игры, составляя 37% от общего числа игроков в этой группе. При этом в группе со старой версией таких игроков нет.
Поведение игроков, скачавших игру с пиратского сайта, может отличаться от поведения остальных игроков. В результате нельзя сделать однозначный вывод о том, что стало причиной изменения целевых показателей - эксперимент или различие групп по составу.
Как исправить ситуацию? Отфильтровать выборку - убрать из нее игроков, скачавших игру с пиратского сайта.
В нашей платформе для этого используется инструмент filters. Вариантов решения с его помощью два:
1. Отфильтровать выборку по источнику установки. Оставим только тех пользователей, у которых мы точно знаем источник установки, в нашем случае это facebook, google. Выставляем в фильтре параметр install source = facebook; google; тем самым убирая установки из неизвестных источников. Получаем равные группы для обеих версий теста.
2. Отфильтровать выборку по географии установок. Мы заметили, большая часть загрузок новой версии идет из Китая. Выбираем в качестве параметра для фильтра country, в значении задаем все страны, кроме Китая, и получаем равное количество участников для разных версий, выводы по эксперименту будут корректны.
Таким образом, гибкость в работе с выборкой позволяет нам проводить эксперименты, даже когда пираты эту выборку портят.
{kind=link}
Самый популярный миф в статистике
Ron Kohavi в книге Trustworthy Online Controlled Experiments пишет: “...многие люди неверно истолковывают предположение о нормальности как предположение о выборочном показателе Y…”
Это неправильное предположение. Для применения Т-критерия выборка не должна быть нормально распределена. Нормальное распределение должно быть у среднего выборки.
Но среднее значение нормально распределено по центральной предельной теореме, а следовательно Т-критерий применим.
Интересно, что русская статья в wikipedia содержит ошибочное требование, а английская - верное.
Ron Kohavi в книге Trustworthy Online Controlled Experiments пишет: “...многие люди неверно истолковывают предположение о нормальности как предположение о выборочном показателе Y…”
Это неправильное предположение. Для применения Т-критерия выборка не должна быть нормально распределена. Нормальное распределение должно быть у среднего выборки.
Но среднее значение нормально распределено по центральной предельной теореме, а следовательно Т-критерий применим.
Интересно, что русская статья в wikipedia содержит ошибочное требование, а английская - верное.
Ребята из GameFirst Mobile разрешили рассказать об эксперименте, которые мы провели вместе с ними на игре God Simulator.
Ребята запустили эксперимент с увеличением цен на внутриигровые покупки. Завели новые in-apps в Google Play и выставили для них новые цены. Новые in-apps привязали к существующим продуктам из игры и из нашей платформы передавали в игру параметр, который определял какие in-app’ы предлагаются игроку - с новой ценой или старые.
Результаты
Количество игроков в эксперименте: 130 тысяч
ARPPU: +22%
Conversion: -20%
Вырос платеж на платящего игрока, но упала конверсия и эксперимент не показал статистической значимости в среднем доходе на игрока.
Apple недавно зафичерил игру God Simulator. Поздравляем ребят с этим событием!
Ребята запустили эксперимент с увеличением цен на внутриигровые покупки. Завели новые in-apps в Google Play и выставили для них новые цены. Новые in-apps привязали к существующим продуктам из игры и из нашей платформы передавали в игру параметр, который определял какие in-app’ы предлагаются игроку - с новой ценой или старые.
Результаты
Количество игроков в эксперименте: 130 тысяч
ARPPU: +22%
Conversion: -20%
Вырос платеж на платящего игрока, но упала конверсия и эксперимент не показал статистической значимости в среднем доходе на игрока.
Apple недавно зафичерил игру God Simulator. Поздравляем ребят с этим событием!
{kind=link}
Ron Kohavi в книге Trustworthy Online Controlled Experiments приводит приблизительную формулу для минимального размера выборки. Смотри картинку.
Сигма в числителе - среднеквадратичное отклонение. В Google Sheet - это функция stdev.
Дельта в знаменателе - разница средних, которую мы хотим увидеть.
Пример
Наши пользователи делают платежи.
Сколько пользователей должно участвовать в эксперименте, чтобы обнаружить разницу средних в платежах в 1 цент?
Стандартное отклонение в группе = 1.12
Подставляем в формулу и получаем ответ: 200 тысяч человек.
Сигма в числителе - среднеквадратичное отклонение. В Google Sheet - это функция stdev.
Дельта в знаменателе - разница средних, которую мы хотим увидеть.
Пример
Наши пользователи делают платежи.
Сколько пользователей должно участвовать в эксперименте, чтобы обнаружить разницу средних в платежах в 1 цент?
Стандартное отклонение в группе = 1.12
Подставляем в формулу и получаем ответ: 200 тысяч человек.
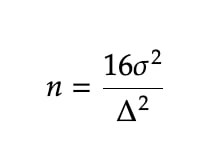{kind=link}
CUPED - это технология, которая увеличивает чувствительность А/Б экспериментов. Booking и Microsoft продвигают ее в своих статьях.
Суть метода в снижении дисперсии за счет использования данных, которые доступны ДО эксперимента. Например:
1. Вы предполагаете, что LTV у вас растет одновременно с retention.
2. Ваша основная метрика при проведении А/Б эксперимента - это LTV.
3. У вас есть прошлые данные, и по ним вы можете увидеть, что LTV и retention растут одновременно.
4. Используя CUPED, вы рассчитываете не LTV, а некую функцию f(LTV, retention), которая имеет меньшую дисперсию и за счет этого увеличивает скорость “покраски” эксперимента.
Вы проводите А/Б эксперименты быстрее, используя знание о том, что retention растет вместе с LTV.
Проблемы у вас начнутся на тех экспериментах, где retention и LTV вместе не растут. В этом случае CUPED для вас будет не методом увеличения чувствительности, а методом ее УМЕНЬШЕНИЯ.
Когда вы начинаете эксперимент, вы заранее не знаете, будет ли у вас расти retention вместе с LTV. Легко представить себе сценарии, когда эти метрики не растут одновременно.
Используя CUPED, вы быстрее завершаете эксперименты не за счет увеличения чувствительности, а за счет уменьшения точности и большего полагания на свою интуицию. Совершенно нормальная практика, но пользуйтесь с осторожностью.
Суть метода в снижении дисперсии за счет использования данных, которые доступны ДО эксперимента. Например:
1. Вы предполагаете, что LTV у вас растет одновременно с retention.
2. Ваша основная метрика при проведении А/Б эксперимента - это LTV.
3. У вас есть прошлые данные, и по ним вы можете увидеть, что LTV и retention растут одновременно.
4. Используя CUPED, вы рассчитываете не LTV, а некую функцию f(LTV, retention), которая имеет меньшую дисперсию и за счет этого увеличивает скорость “покраски” эксперимента.
Вы проводите А/Б эксперименты быстрее, используя знание о том, что retention растет вместе с LTV.
Проблемы у вас начнутся на тех экспериментах, где retention и LTV вместе не растут. В этом случае CUPED для вас будет не методом увеличения чувствительности, а методом ее УМЕНЬШЕНИЯ.
Когда вы начинаете эксперимент, вы заранее не знаете, будет ли у вас расти retention вместе с LTV. Легко представить себе сценарии, когда эти метрики не растут одновременно.
Используя CUPED, вы быстрее завершаете эксперименты не за счет увеличения чувствительности, а за счет уменьшения точности и большего полагания на свою интуицию. Совершенно нормальная практика, но пользуйтесь с осторожностью.