
Как мы внедрили АБ тестирование в наших играх
Кто мы
Мы в Stereo7 Games делаем стратегии в жанре tower defense. Наш текущий главный проект - это игра Steampunk Defense: https://play.google.com/store/apps/details…. При разработке, мы уже более 2-ух лет активно используем АБ-тесты о которых я хотел бы рассказать ниже:
Краткое описание процесса
Наша основная платформа - это Google Play. Google Play дает возможность выкладывать каждый новый билд на 50% аудитории. Таким образом часть игроков видит новую фичу (персонажи, уровни, механики), а часть - не видит. Мы смотрим на игру в течение недели-двух и сравниваем заработок на версии с фичей с версией без фичи.
Что мы пробовали
Начали мы с
𝗔𝗺𝗽𝗹𝗶𝘁𝘂𝗱𝗲: https://amplitude.com/
Для анализа результатов, каждого игрока мы случайно определяли его в группу, которая либо видит новую фичу либо нет. Мы выделяли каждому игроку свойство Tes=[имя теста] и свойство Control или Variant и через Amplitude пытались понять больше мы заработали или меньше. Мы столкнулись с такими проблемами:
1. В Amplitude нет модуля статистики.
Амплитуда не смогла сказать нам - является ли изменение статистически значимым.
Пример: Мы видим
на контрольной группе LTV/DAU=$0.5
а на варианте мы видим LTV/DAU=$0,6
Как понять - мы действительно больше стали зарабатывать или это просто случайность?
Мы говорили с их консультантами - они предлагают подключить Optimizely за $100,000.
2. Amplitude плохо работает с Google Play in-app’ами
Т. к. все цены приходят в локальной валюте сложно посчитать суммарную выручку. 100 долларов + 10 рублей - это сколько?
𝗙𝗶𝗿𝗲𝗯𝗮𝘀𝗲
У Google есть бесплатное решение Firebase, которое решает проблемы выше. У них есть статистический модуль и in-app’ы приводятся к долларам США. Некоторые недостатки мы увидели сразу, но решили на первое время закрыть на них глаза. Вот они:
1. Firebase не позволяет сравнивать средние значения для рекламы.
Т. е. если вы хотите (а мы хотели еще как!) максимизировать число показов рекламы, вы можете сделать это только в случае если используете AdMob. У нас AdMob не единственная сетка, поэтому Firebase не подходил для этой задачи.
2. Firebase не позволяет сравнивать средние значения для произвольной метрики.
Если вы в рамках теста хотите максимизировать число прохождения уровней (например), то Firebase вам это не позволит. Единственное что он даст - это отслеживать конверсию вида: “игрок дошел до 5-го уровня”.
Конечно, с помощью костылей можно извратиться и попытаться отследить среднее для произвольной метрики, он корректно это сделать невозможно.
3. Не очень аккуратная работа с фродом
Firebase в целом отсеивает игроков, которые проводят махинации с in-app’ами, но иногда мы видели разницу в финансовых отчетах от Google Play и Firebase.
Проблема заключается в том что Firebase считает что некоторые игроки заплатили, хотя на самом деле они не платили.
4. Слабый (а точнее никакой) движок обработки тестов
Первое время мы понастроили костылей и решили работать с Firebase, закрыв глаза на пункты выше. Тесты проходили очень быстро. Много тестов заканчивались успехом. Но вот только выручка почему-то не росла...
Чтобы проверить движок, мы начали запускать АА Тесты. АА Тест - это классический прием в АБ тестировании для проверки работоспособности движка обсчета, когда игроки в обеих группах игроки получают в точности одинаковую версию игры.
К нашему удивления Firebase очень быстро находил победителя в АА тестах. Т. е. другими словами он писал “Вариант А лучше с вероятностью 99%” хотя на самом деле никакого варианта А не было - он был в точности равен варианту Б.
𝗢𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗹𝘆
По слухам они работают хорошо, но блин $100,000...
Я с большим скепсисом отношусь к попыткам разработать “свой движок аналитики”, “свою рендерилку” и т. п. И уж точно не разделяю шовинистических идей в духе: “это плохо потому что разработано не нами”.
Короче, мы задумались о своей платформе для АБ тестирования в которой не было бы недостатков выше.
[продолжение следует]
Кто мы
Мы в Stereo7 Games делаем стратегии в жанре tower defense. Наш текущий главный проект - это игра Steampunk Defense: https://play.google.com/store/apps/details…. При разработке, мы уже более 2-ух лет активно используем АБ-тесты о которых я хотел бы рассказать ниже:
Краткое описание процесса
Наша основная платформа - это Google Play. Google Play дает возможность выкладывать каждый новый билд на 50% аудитории. Таким образом часть игроков видит новую фичу (персонажи, уровни, механики), а часть - не видит. Мы смотрим на игру в течение недели-двух и сравниваем заработок на версии с фичей с версией без фичи.
Что мы пробовали
Начали мы с
𝗔𝗺𝗽𝗹𝗶𝘁𝘂𝗱𝗲: https://amplitude.com/
Для анализа результатов, каждого игрока мы случайно определяли его в группу, которая либо видит новую фичу либо нет. Мы выделяли каждому игроку свойство Tes=[имя теста] и свойство Control или Variant и через Amplitude пытались понять больше мы заработали или меньше. Мы столкнулись с такими проблемами:
1. В Amplitude нет модуля статистики.
Амплитуда не смогла сказать нам - является ли изменение статистически значимым.
Пример: Мы видим
на контрольной группе LTV/DAU=$0.5
а на варианте мы видим LTV/DAU=$0,6
Как понять - мы действительно больше стали зарабатывать или это просто случайность?
Мы говорили с их консультантами - они предлагают подключить Optimizely за $100,000.
2. Amplitude плохо работает с Google Play in-app’ами
Т. к. все цены приходят в локальной валюте сложно посчитать суммарную выручку. 100 долларов + 10 рублей - это сколько?
𝗙𝗶𝗿𝗲𝗯𝗮𝘀𝗲
У Google есть бесплатное решение Firebase, которое решает проблемы выше. У них есть статистический модуль и in-app’ы приводятся к долларам США. Некоторые недостатки мы увидели сразу, но решили на первое время закрыть на них глаза. Вот они:
1. Firebase не позволяет сравнивать средние значения для рекламы.
Т. е. если вы хотите (а мы хотели еще как!) максимизировать число показов рекламы, вы можете сделать это только в случае если используете AdMob. У нас AdMob не единственная сетка, поэтому Firebase не подходил для этой задачи.
2. Firebase не позволяет сравнивать средние значения для произвольной метрики.
Если вы в рамках теста хотите максимизировать число прохождения уровней (например), то Firebase вам это не позволит. Единственное что он даст - это отслеживать конверсию вида: “игрок дошел до 5-го уровня”.
Конечно, с помощью костылей можно извратиться и попытаться отследить среднее для произвольной метрики, он корректно это сделать невозможно.
3. Не очень аккуратная работа с фродом
Firebase в целом отсеивает игроков, которые проводят махинации с in-app’ами, но иногда мы видели разницу в финансовых отчетах от Google Play и Firebase.
Проблема заключается в том что Firebase считает что некоторые игроки заплатили, хотя на самом деле они не платили.
4. Слабый (а точнее никакой) движок обработки тестов
Первое время мы понастроили костылей и решили работать с Firebase, закрыв глаза на пункты выше. Тесты проходили очень быстро. Много тестов заканчивались успехом. Но вот только выручка почему-то не росла...
Чтобы проверить движок, мы начали запускать АА Тесты. АА Тест - это классический прием в АБ тестировании для проверки работоспособности движка обсчета, когда игроки в обеих группах игроки получают в точности одинаковую версию игры.
К нашему удивления Firebase очень быстро находил победителя в АА тестах. Т. е. другими словами он писал “Вариант А лучше с вероятностью 99%” хотя на самом деле никакого варианта А не было - он был в точности равен варианту Б.
𝗢𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗹𝘆
По слухам они работают хорошо, но блин $100,000...
Я с большим скепсисом отношусь к попыткам разработать “свой движок аналитики”, “свою рендерилку” и т. п. И уж точно не разделяю шовинистических идей в духе: “это плохо потому что разработано не нами”.
Короче, мы задумались о своей платформе для АБ тестирования в которой не было бы недостатков выше.
[продолжение следует]
[продолжение. cмотри начало в предыдущем посте]
В прошлом посте мы писали, что не нашли на рынке хорошей платформы для проведения А/В-тестов и решили написать свою. В этом посте мы расскажем, из чего состоит её техническая часть.
Давайте рассмотрим пример. На прошлой неделе мы перешли с медиации MoPub на Applovin Max. В рамках теста мы хотим узнать, как это изменение повлияло на основные метрики игры.
Remote Config
Настройка любого теста идет через удаленный конфиг, который хранится на облаке. Каждый раз, когда игрок первый раз открывает игру, игра запрашивает конфиг следующего формата:
Пример
ABTestV2ApplovinAndNewTowers28April02 = {"version":301,"variant":"Variant","parameters":{ }}
ABTestV2ApplovinAndNewTowers28April01 = {"version":300,"variant":"Control","parameters":{ }}
В этом примере мы просто говорим платформе: “Пометь всех игроков контрольной версии 300 как Control, а версию 301 как Variant в рамках теста V2ApplovinAndNewTowers28”.
Разделение игроков на группы
Сейчас мы умеем делить игроков на группы двумя способами:
1. Разбиение в рамках версии. Допустим, у нас на Google Play выложена на 100% аудитории версия 301. Мы запускаем тест на этой аудитории.
2. В рамках разных версий. Как в примере с Applovin. Мы выкладываем новый билд и хотим знать, как у него отличаются метрики по сравнению с контрольным.
Процесс сбора данных
Цель нашего эксперимента - заработать больше денег. Деньги мы получаем из двух источников:
1. Продажа In-App’ов. В нашем случае это золото, новые герои, новые башни и топливо. Для каждого игрока мы собираем всю информацию о его покупках.
2. Показ рекламы (impressions). Чем больше рекламы мы показали, тем больше денег заработали.
ВАЖНО в рамках эксперимента рассматривать не отдельные платежи и показы impressions, а сумму которую игроки тратят. На эту тему будет отдельный пост.
Кроме этого, мы собираем еще много всего, но все решения всегда принимаются только на основе данных о рекламе и in-app’ов. Нам абсолютно неважно, что стало с retention, стали ли игроки отваливаться на 5-ом уровне или нет. Эти метрики мы тоже собираем и обрабатываем, но они никогда не имеют веса в принятии решения, а скорее позволяют нам лучше понять, что произошло. Решение же принимается всегда на основе ответа на вопрос: “Стали мы зарабатывать больше или нет?”. Если стали зарабатывать больше, фича идет в продакшн. Если не стали, мы ее откатываем. Откатываем мы примерно 70% от всех фич. Почему так - это тоже тема отдельного поста.
Антифрод
На данный момент существенный процент игроков получает платный игровой контент, не заплатив. Для нашего эксперимента это проблема, потому что мы получаем кривые данные в рамках эксперимента и можем сделать неправильный вывод. Существует несколько способов (и это тоже тема отдельного поста) обмана разработчиков. Если кратко, то суть нашего антифрода - это проведение транзакций через облако.
1. Код на облаке запрашивает подтверждение о каждой транзакции у Google и отдает нашей игре заключение “Этот игрок не читер” или “Это читер”.
2. Игра помечает все in-app’ы как валидные или невалидные
3. В процессе обработки данных мы смотрим только на валидные in-app’ы.
Хранилище данных
Все данные об игроках хранятся в Google Analytics, и несколько раз в сутки мы выгружаем их в Big Query.
Обработка данных
Ядро нашей платформы написано на R. Мы отправляем запросы в Big Query и на стороне сервера обрабатываем их.
В прошлом посте мы писали, что не нашли на рынке хорошей платформы для проведения А/В-тестов и решили написать свою. В этом посте мы расскажем, из чего состоит её техническая часть.
Давайте рассмотрим пример. На прошлой неделе мы перешли с медиации MoPub на Applovin Max. В рамках теста мы хотим узнать, как это изменение повлияло на основные метрики игры.
Remote Config
Настройка любого теста идет через удаленный конфиг, который хранится на облаке. Каждый раз, когда игрок первый раз открывает игру, игра запрашивает конфиг следующего формата:
Пример
ABTestV2ApplovinAndNewTowers28April02 = {"version":301,"variant":"Variant","parameters":{ }}
ABTestV2ApplovinAndNewTowers28April01 = {"version":300,"variant":"Control","parameters":{ }}
В этом примере мы просто говорим платформе: “Пометь всех игроков контрольной версии 300 как Control, а версию 301 как Variant в рамках теста V2ApplovinAndNewTowers28”.
Разделение игроков на группы
Сейчас мы умеем делить игроков на группы двумя способами:
1. Разбиение в рамках версии. Допустим, у нас на Google Play выложена на 100% аудитории версия 301. Мы запускаем тест на этой аудитории.
2. В рамках разных версий. Как в примере с Applovin. Мы выкладываем новый билд и хотим знать, как у него отличаются метрики по сравнению с контрольным.
Процесс сбора данных
Цель нашего эксперимента - заработать больше денег. Деньги мы получаем из двух источников:
1. Продажа In-App’ов. В нашем случае это золото, новые герои, новые башни и топливо. Для каждого игрока мы собираем всю информацию о его покупках.
2. Показ рекламы (impressions). Чем больше рекламы мы показали, тем больше денег заработали.
ВАЖНО в рамках эксперимента рассматривать не отдельные платежи и показы impressions, а сумму которую игроки тратят. На эту тему будет отдельный пост.
Кроме этого, мы собираем еще много всего, но все решения всегда принимаются только на основе данных о рекламе и in-app’ов. Нам абсолютно неважно, что стало с retention, стали ли игроки отваливаться на 5-ом уровне или нет. Эти метрики мы тоже собираем и обрабатываем, но они никогда не имеют веса в принятии решения, а скорее позволяют нам лучше понять, что произошло. Решение же принимается всегда на основе ответа на вопрос: “Стали мы зарабатывать больше или нет?”. Если стали зарабатывать больше, фича идет в продакшн. Если не стали, мы ее откатываем. Откатываем мы примерно 70% от всех фич. Почему так - это тоже тема отдельного поста.
Антифрод
На данный момент существенный процент игроков получает платный игровой контент, не заплатив. Для нашего эксперимента это проблема, потому что мы получаем кривые данные в рамках эксперимента и можем сделать неправильный вывод. Существует несколько способов (и это тоже тема отдельного поста) обмана разработчиков. Если кратко, то суть нашего антифрода - это проведение транзакций через облако.
1. Код на облаке запрашивает подтверждение о каждой транзакции у Google и отдает нашей игре заключение “Этот игрок не читер” или “Это читер”.
2. Игра помечает все in-app’ы как валидные или невалидные
3. В процессе обработки данных мы смотрим только на валидные in-app’ы.
Хранилище данных
Все данные об игроках хранятся в Google Analytics, и несколько раз в сутки мы выгружаем их в Big Query.
Обработка данных
Ядро нашей платформы написано на R. Мы отправляем запросы в Big Query и на стороне сервера обрабатываем их.
Как мы делаем выводы на основе экспериментальных данных
Мы говорили в прошлом посте, что наша задача - максимизация прибыли. Небольшое лирическое отступление.
Если вы работаете в игровой индустрии достаточно давно, то для вас стала привычной картина, когда аналитики (или кто-то, кто исполняет эту роль) собираются раз в неделю, и начинается:
- Фича зашла просто супер! Конверсия в платящих выросла в 2 раза.
- А бабла почему-то стало меньше.
- Да ну это сезонный спад. На следующей неделе наверстаем!
- Погодите! А ретеншн упал же?
- Да ну не - конверсия в 2 раза выросла, значит все огонь будет.
Через неделю новостей хороших тоже нет, и все примерно повторяется. Потом в штатах наступает рождество какое-нибудь - бабло растет. Все реже смотрят на относительные показатели. Январь - нерабочие дни. И в конце января все хватаются за голову. Владельца бизнеса абсолютно эти мелочи не интересуют. Мы хотим знать одно - делает новое изменение нас богаче или беднее.
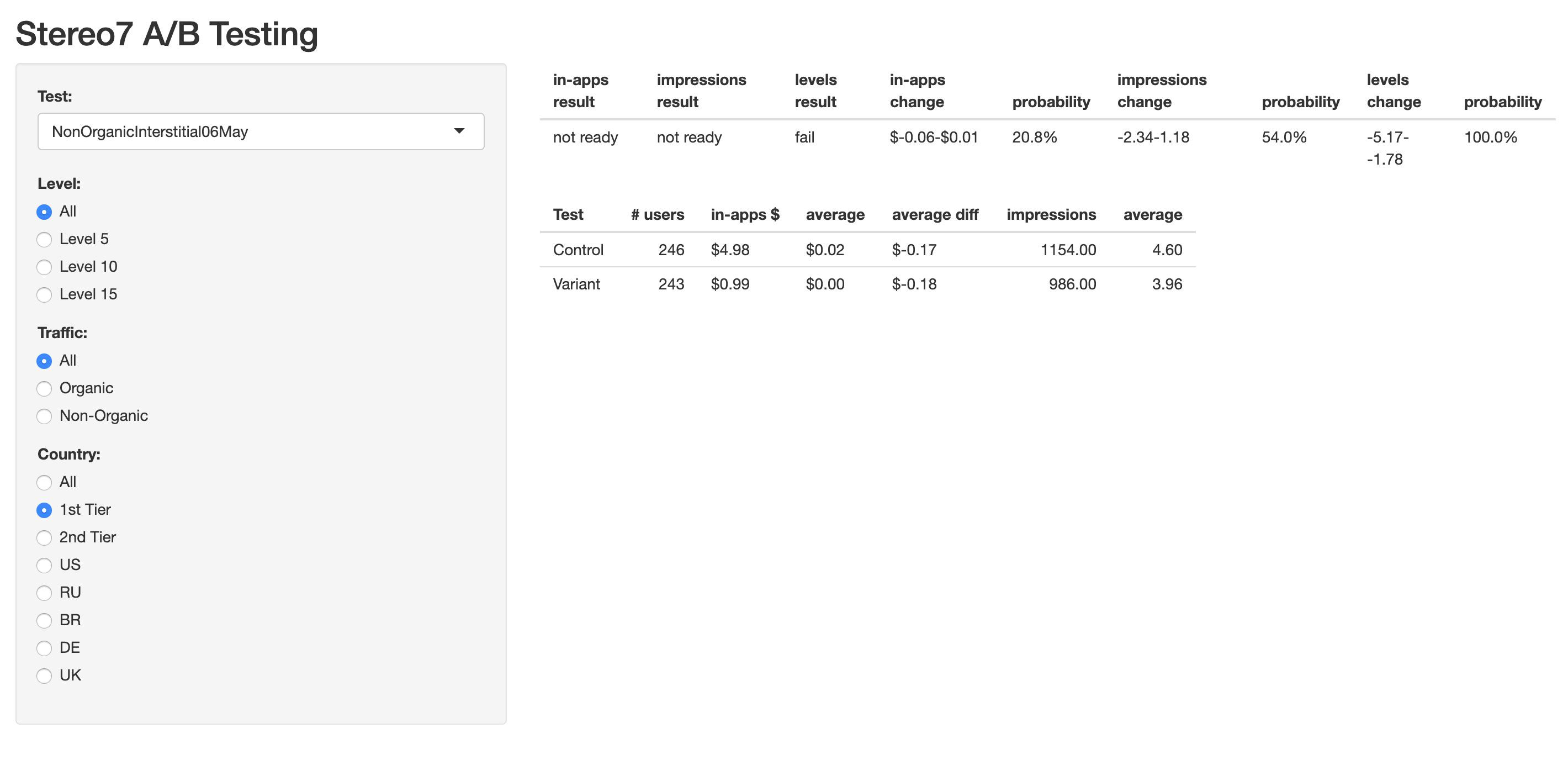
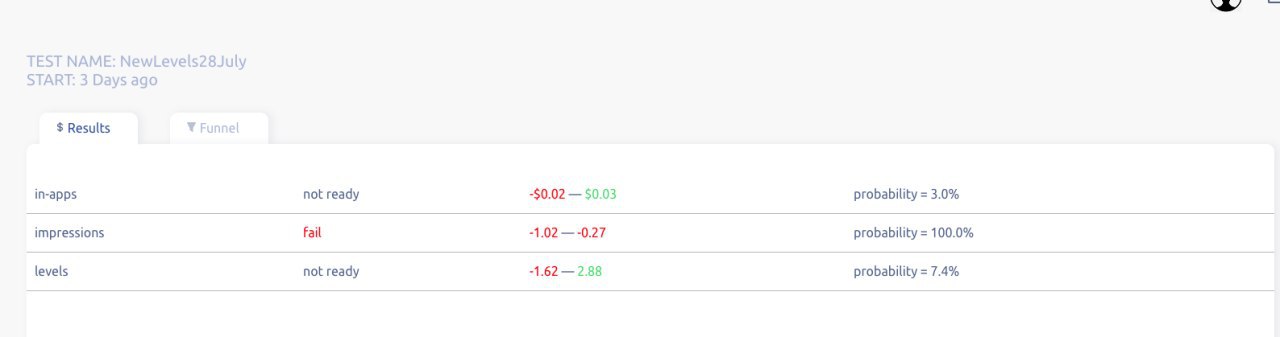
Для ответа на этот вопрос наша платформа на вход получает: Impressions (количество показов рекламы на игрок) и In-Apps (сумма платежей на игрока). На выходе дает заключение - стало лучше или стало хуже. В аттаче иллюстрация нашей старой первой версии платформы.
Слева фильтры, которые позволяют узнать, как эксперимент отразился на разных группах игроков.
Level. Позволяет выделить игроков дошедших до уровня 5, 10 и 15. Часто бывает полезно увидеть, что фича в целом не зашла, но игроки, которые прошли 15 уровней (hardcor’ная аудитория), стали платить в несколько раз больше.
Traffic (organic, non-organic). С его помощью мы делаем кастомизованные под трафик фичи. Об этом отдельный пост будет.
Country. Аудитория наших игр - это 1st tier countries, поэтому мы в первую очередь смотрим на них.
Справа результаты эксперимента: in-apps result (not ready - недостаточно данных для выводов, fail - провал, success - успех) и impressions result (тоже самое про показы рекламы). Решение о дальнейшей судьбе фичи принимается только на основе заключений в этих двух полях. Все остальные данные - позволяют нам лучше понимать, что происходит в игре.
Это лишь самое основное, что есть в платформе. Математика внутри - тема отдельного поста. Как нам живется с платформой сейчас? Вкратце - хорошо. Нас совершенно не интересуют никакие другие показатели, кроме этих двух выводов.
- Мы понятия не имеем, какой у нас 1-day retention. Вот честно - не знаем даже, куда смотреть.
- Мы не хотим даже знать, какая у нас длина сессии на юзера.
- И нам совершенно плевать на то, сколько игроков прошли туториал.
- Не говоря уже о проценте конверсии в платящего игрока.
Хотите чтобы у вас было также? Оставьте заявку - мы вам все настроим! http://abtestreal.com/
Мы говорили в прошлом посте, что наша задача - максимизация прибыли. Небольшое лирическое отступление.
Если вы работаете в игровой индустрии достаточно давно, то для вас стала привычной картина, когда аналитики (или кто-то, кто исполняет эту роль) собираются раз в неделю, и начинается:
- Фича зашла просто супер! Конверсия в платящих выросла в 2 раза.
- А бабла почему-то стало меньше.
- Да ну это сезонный спад. На следующей неделе наверстаем!
- Погодите! А ретеншн упал же?
- Да ну не - конверсия в 2 раза выросла, значит все огонь будет.
Через неделю новостей хороших тоже нет, и все примерно повторяется. Потом в штатах наступает рождество какое-нибудь - бабло растет. Все реже смотрят на относительные показатели. Январь - нерабочие дни. И в конце января все хватаются за голову. Владельца бизнеса абсолютно эти мелочи не интересуют. Мы хотим знать одно - делает новое изменение нас богаче или беднее.
Для ответа на этот вопрос наша платформа на вход получает: Impressions (количество показов рекламы на игрок) и In-Apps (сумма платежей на игрока). На выходе дает заключение - стало лучше или стало хуже. В аттаче иллюстрация нашей старой первой версии платформы.
Слева фильтры, которые позволяют узнать, как эксперимент отразился на разных группах игроков.
Level. Позволяет выделить игроков дошедших до уровня 5, 10 и 15. Часто бывает полезно увидеть, что фича в целом не зашла, но игроки, которые прошли 15 уровней (hardcor’ная аудитория), стали платить в несколько раз больше.
Traffic (organic, non-organic). С его помощью мы делаем кастомизованные под трафик фичи. Об этом отдельный пост будет.
Country. Аудитория наших игр - это 1st tier countries, поэтому мы в первую очередь смотрим на них.
Справа результаты эксперимента: in-apps result (not ready - недостаточно данных для выводов, fail - провал, success - успех) и impressions result (тоже самое про показы рекламы). Решение о дальнейшей судьбе фичи принимается только на основе заключений в этих двух полях. Все остальные данные - позволяют нам лучше понимать, что происходит в игре.
Это лишь самое основное, что есть в платформе. Математика внутри - тема отдельного поста. Как нам живется с платформой сейчас? Вкратце - хорошо. Нас совершенно не интересуют никакие другие показатели, кроме этих двух выводов.
- Мы понятия не имеем, какой у нас 1-day retention. Вот честно - не знаем даже, куда смотреть.
- Мы не хотим даже знать, какая у нас длина сессии на юзера.
- И нам совершенно плевать на то, сколько игроков прошли туториал.
- Не говоря уже о проценте конверсии в платящего игрока.
Хотите чтобы у вас было также? Оставьте заявку - мы вам все настроим! http://abtestreal.com/
{kind=link}
Как я перестал нервничать и начал релизить
Изменения пугают. Каждый апдейт к игре - это всегда риск сломать игру.
Но мы не боимся, потому что отслеживаем воронку. Модель любой игры можно представить в виде событий-конверсий, которые совершает игрок. Например, в Match-3 будут конверсии: 1. Игрок прошёл обучение. 2. Игрок прошёл N-ый уровень.
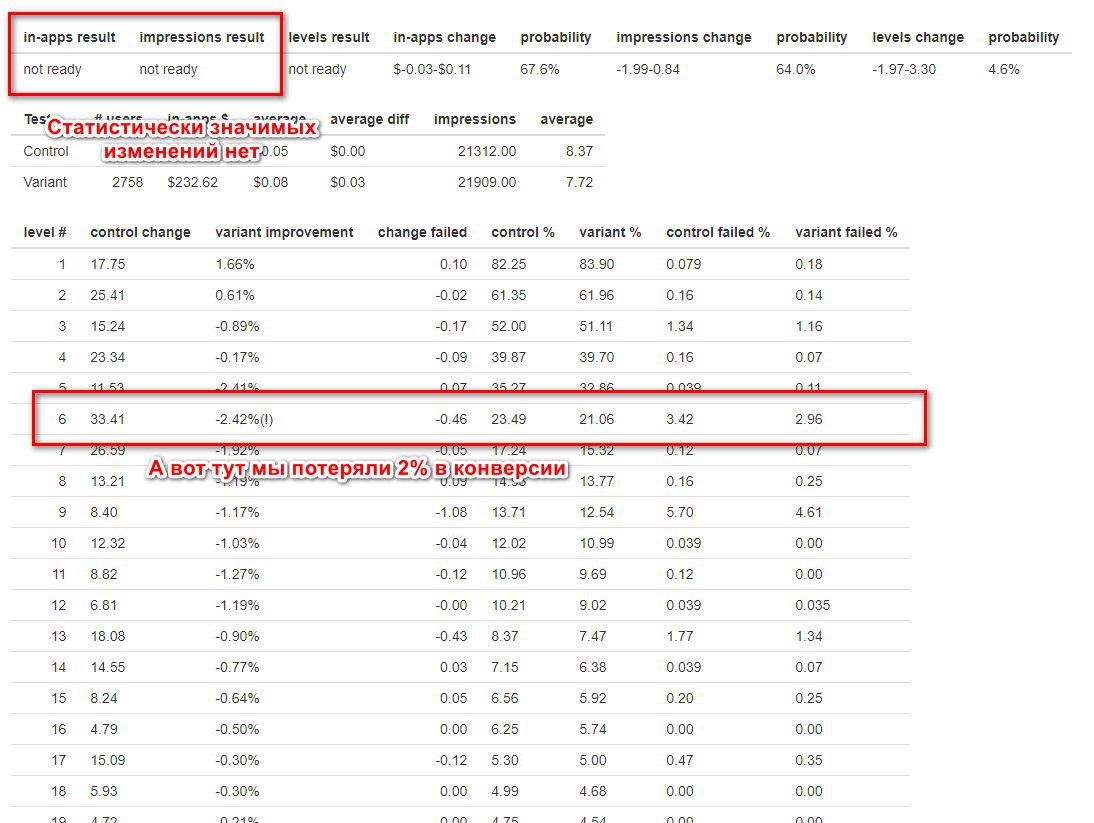
У нас single player и в нашей модели конверсия - это просто “Игрок прошёл N-ый уровень”. Пример: на прошлой неделе мы добавили сохранение прогресса игрока на облаке. На 6-ом уровне у нас появляется NPC и говорит: “Дорогой игрок, ты прошёл достаточно далеко. Хочешь сохранить прогресс?”. Мы отвечаем “Да!” и данные сохраняются на облаке.
Выкатываем 50% функциональности с сохранением на облаке и сравниванием с игроками без сохранения. Мы ожидаем, что конверсия ухудшится на 6-ом уровне. Запускаем тест и получаем результаты.
Восклицательный знак на 6-ом уровне говорит нам, что да, конверсия действительно просела. Там, где мы ждали, результат статистически значим - дальше 6-го уровня мы точно потеряли в DAU. На 5-ом уровне падение в конверсии такое же, но с точки зрения платформы - это может быть и случайность, т.к. восклицательного знака нет.
Итого:
1. В деньгах мы не выиграли.
2. В конверсии на 5-ом уровне проиграли.
Вывод: фичу “Сохранение данных игрока” надо откатить. А как вы проверяете, зашла ли фича? Пишите в комментариях!
Изменения пугают. Каждый апдейт к игре - это всегда риск сломать игру.
Но мы не боимся, потому что отслеживаем воронку. Модель любой игры можно представить в виде событий-конверсий, которые совершает игрок. Например, в Match-3 будут конверсии: 1. Игрок прошёл обучение. 2. Игрок прошёл N-ый уровень.
У нас single player и в нашей модели конверсия - это просто “Игрок прошёл N-ый уровень”. Пример: на прошлой неделе мы добавили сохранение прогресса игрока на облаке. На 6-ом уровне у нас появляется NPC и говорит: “Дорогой игрок, ты прошёл достаточно далеко. Хочешь сохранить прогресс?”. Мы отвечаем “Да!” и данные сохраняются на облаке.
Выкатываем 50% функциональности с сохранением на облаке и сравниванием с игроками без сохранения. Мы ожидаем, что конверсия ухудшится на 6-ом уровне. Запускаем тест и получаем результаты.
Восклицательный знак на 6-ом уровне говорит нам, что да, конверсия действительно просела. Там, где мы ждали, результат статистически значим - дальше 6-го уровня мы точно потеряли в DAU. На 5-ом уровне падение в конверсии такое же, но с точки зрения платформы - это может быть и случайность, т.к. восклицательного знака нет.
Итого:
1. В деньгах мы не выиграли.
2. В конверсии на 5-ом уровне проиграли.
Вывод: фичу “Сохранение данных игрока” надо откатить. А как вы проверяете, зашла ли фича? Пишите в комментариях!
{kind=link}
Что изменилось после того, как мы внедрили AB-тестирование
Когда мы разрабатывали платформу, прежде всего, мы хотели получить инструмент для запуска AB-тестов. Мы не ожидали, что изменится сам процесс. Что изменилось:
1. Мы начали выкладывать апдейты, не тестируя их тщательно.
Наша стратегия - выкладывать как можно больше апдейтов. Платформа сообщает, если мы выложили билд, который сильно ухудшает параметры - тогда можем оперативно откатить его. Мы проводим глубокое регрессионное тестирование после выкладки билда, а фиксим баги в следующем релизе. Так мы сильно увеличиваем частоту апдейтов.
2. На Google Play мы можем выложить апдейт в пятницу вечером.
Если платформа на выходных сигнализирует о проблемах в билде, мы откатываем его буквально одним нажатием кнопки прямо на выходных.
3. У нас нет аналитиков.
Любой член команды может: предложить идею, увидеть, “зашла” фича или нет, увидеть влияние фичи на игру и стат значимость изменения основных параметров в одном дашборде. Освободилась куча времени, нет длительных обсуждений и холиваров. Конечно, меня сейчас съедят. Но для чего ещё нужна автоматизация?
4. Любая фича делается в нескольких вариантах исполнения.
Как правило, в фичу мы закладываем набор параметров, которые можно проверять, не перевыкладывая билд. Мы хотим запускать несколько AB-тестов в рамках одной фичи, чтобы “выжать из неё максимум”.
Пример:
1. В игре мы добавляем карту с ресурсами (смотри рисунок).
2. Как понять сколько кристалликов должно быть на одной ячейке карты? Мы делаем сразу 3-4 варианта: 100, 200, 300 и 400 кристалликов. Храним текущую конфигурацию на сервере. Игра подгружает этот конфиг при запуске.
3. Мы выкладываем новую карту на 50% и последовательно запускаем несколько тестов. Потом просто смотрим, на каком варианте мы заработали больше со статистической достоверностью.
Хорошо, что у нас есть платформа, которая позволяет это делать. Присоединяйтесь к нам!
Когда мы разрабатывали платформу, прежде всего, мы хотели получить инструмент для запуска AB-тестов. Мы не ожидали, что изменится сам процесс. Что изменилось:
1. Мы начали выкладывать апдейты, не тестируя их тщательно.
Наша стратегия - выкладывать как можно больше апдейтов. Платформа сообщает, если мы выложили билд, который сильно ухудшает параметры - тогда можем оперативно откатить его. Мы проводим глубокое регрессионное тестирование после выкладки билда, а фиксим баги в следующем релизе. Так мы сильно увеличиваем частоту апдейтов.
2. На Google Play мы можем выложить апдейт в пятницу вечером.
Если платформа на выходных сигнализирует о проблемах в билде, мы откатываем его буквально одним нажатием кнопки прямо на выходных.
3. У нас нет аналитиков.
Любой член команды может: предложить идею, увидеть, “зашла” фича или нет, увидеть влияние фичи на игру и стат значимость изменения основных параметров в одном дашборде. Освободилась куча времени, нет длительных обсуждений и холиваров. Конечно, меня сейчас съедят. Но для чего ещё нужна автоматизация?
4. Любая фича делается в нескольких вариантах исполнения.
Как правило, в фичу мы закладываем набор параметров, которые можно проверять, не перевыкладывая билд. Мы хотим запускать несколько AB-тестов в рамках одной фичи, чтобы “выжать из неё максимум”.
Пример:
1. В игре мы добавляем карту с ресурсами (смотри рисунок).
2. Как понять сколько кристалликов должно быть на одной ячейке карты? Мы делаем сразу 3-4 варианта: 100, 200, 300 и 400 кристалликов. Храним текущую конфигурацию на сервере. Игра подгружает этот конфиг при запуске.
3. Мы выкладываем новую карту на 50% и последовательно запускаем несколько тестов. Потом просто смотрим, на каком варианте мы заработали больше со статистической достоверностью.
Хорошо, что у нас есть платформа, которая позволяет это делать. Присоединяйтесь к нам!
{kind=link}
Работа с балансом в игре
Хороший баланс в игре - это набор цифр, который в идеале делает игроков счастливее (необязательно) и наполняет кошельки владельцев баблом (обязательно).
Допустим, мы решили усложнить нашу игру. Игроки начнут платить и продолжат играть? Или разбегутся, потому что станет слишком сложно? Сколько нервов гейм-дизайнеров, аналитиков и разработчиков потрачено за спорами!
Вопросы цифр в игре мы решаем всегда одинаково - запускаем эксперимент. Механика наших tower defense стратегий следующая:
1. Есть враги, которые бегут по дорожке.
2. У них есть HP (здоровье).
3. Наши герои и пушки их убивают.
Чем больше здоровья у врагов, тем сложнее наша игра. Здоровье вычисляется по формуле: HP = Base HP * K, где K параметр на облачном сервере. В игру мы передаем параметр: {"version":380,"variant":"Variant","parameters":{"HPRateTest": "2:2:2.8"}}
Ставим K=2.8 для уровня 2 и смотрим, заработали мы больше или нет. Если заработали больше, оставляем K=2.8. Если заработали меньше, то запускаем новый эксперимент и ставим, например, K=0.8. Если заработок не изменился, мы смотрим на более чувствительную метрику “конверсия в третий уровень”.
Хорошо, что у нас есть платформа, которая достоверно определяет, заработали мы больше или меньше.
abtestreal.com
Хороший баланс в игре - это набор цифр, который в идеале делает игроков счастливее (необязательно) и наполняет кошельки владельцев баблом (обязательно).
Допустим, мы решили усложнить нашу игру. Игроки начнут платить и продолжат играть? Или разбегутся, потому что станет слишком сложно? Сколько нервов гейм-дизайнеров, аналитиков и разработчиков потрачено за спорами!
Вопросы цифр в игре мы решаем всегда одинаково - запускаем эксперимент. Механика наших tower defense стратегий следующая:
1. Есть враги, которые бегут по дорожке.
2. У них есть HP (здоровье).
3. Наши герои и пушки их убивают.
Чем больше здоровья у врагов, тем сложнее наша игра. Здоровье вычисляется по формуле: HP = Base HP * K, где K параметр на облачном сервере. В игру мы передаем параметр: {"version":380,"variant":"Variant","parameters":{"HPRateTest": "2:2:2.8"}}
Ставим K=2.8 для уровня 2 и смотрим, заработали мы больше или нет. Если заработали больше, оставляем K=2.8. Если заработали меньше, то запускаем новый эксперимент и ставим, например, K=0.8. Если заработок не изменился, мы смотрим на более чувствительную метрику “конверсия в третий уровень”.
Хорошо, что у нас есть платформа, которая достоверно определяет, заработали мы больше или меньше.
abtestreal.com
Работа с контентом в игре
Реальный случай из жизни. Приходит художник и говорит:
- Нам нужны новые крипы (враги) на уровнях! Солдаты сейчас всех бесят.
- Давай посмотрим!
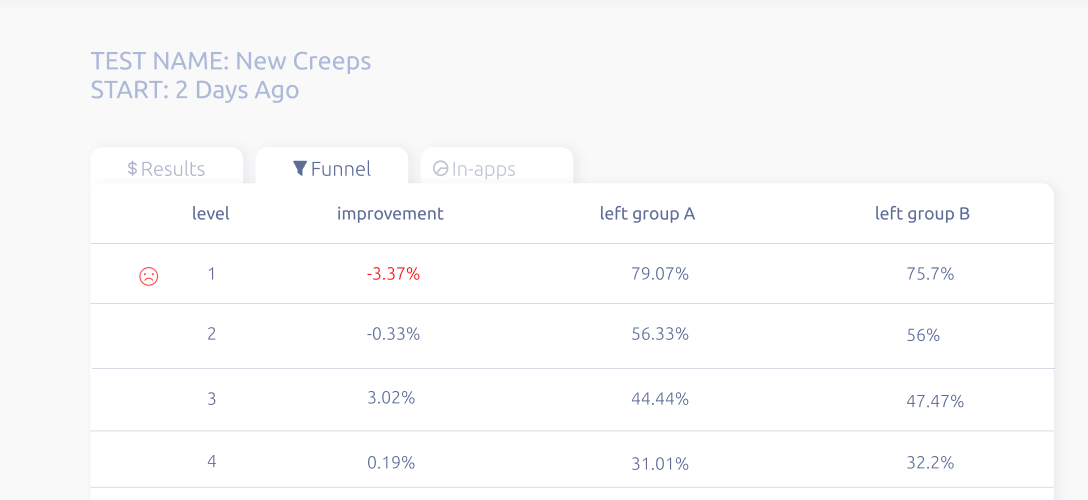
Были солдаты, стали - роботы. Запускаем эксперимент и получаем небольшое, но статистически значимое падение конверсии на первом уровне (смотрите скриншот).
С одной стороны, фейл - хотели улучшить жизнь игрокам, но ничего не изменилось. На самом деле, успех - мы получили знание: игрокам не так уж и важно, КТО именно бегает в качестве крипов. Значит похожее исправление в игре мы планировать в ближайшее время не будем.
Хотите получать знания о своей игре? Давайте к нам! abtestreal.com
Реальный случай из жизни. Приходит художник и говорит:
- Нам нужны новые крипы (враги) на уровнях! Солдаты сейчас всех бесят.
- Давай посмотрим!
Были солдаты, стали - роботы. Запускаем эксперимент и получаем небольшое, но статистически значимое падение конверсии на первом уровне (смотрите скриншот).
С одной стороны, фейл - хотели улучшить жизнь игрокам, но ничего не изменилось. На самом деле, успех - мы получили знание: игрокам не так уж и важно, КТО именно бегает в качестве крипов. Значит похожее исправление в игре мы планировать в ближайшее время не будем.
Хотите получать знания о своей игре? Давайте к нам! abtestreal.com
{kind=link}
АB-тестирование и работа с когортами
О работе с когортами много говорят, но часто непонятно, как с ними правильно работать. Об этом пойдет речь ниже.
Google Universal Campaign - один из источников трафика для нашей игры. Мы оптимизируем кампании под инсталлы, поэтому почти все наши игроки с Google неплатящие. Из экспериментов нам уже известно:
1. Если показывать больше рекламы платящим игрокам на первых уровнях, то такие игроки раньше уходят и суммарное количество показанной рекламы таким игрокам меньше.
2. Игроки с Google проходят меньше уровней в игре.
Мы хотим проверить гипотезу: если показывать больше рекламы на первых уровнях игрокам с Google (которые не платят и рано уходят из игры), суммарное количество показов вырастет.
Запускаем эксперимент только на игроках с Google:
Показываем игрокам рекламу сразу, начиная с первого уровня, и убираем ограничение на показ рекламы (можем в течение 1 минуты показать несколько раз). Для контрольной группы показываем только на уровнях 2, 4, 6… и оставляем ограничение - не более 1 показа в минуту.
Результат. Суммарное количество показов выросло: доверительный интервал -0.098 — 2.94, вероятность 93.2%. Хотя и рекомендуют принимать решение при вероятности выше 95%, мы немного жульничаем и делаем вывод — показываем игрокам с Google больше рекламы на первых уровнях.
О работе с когортами много говорят, но часто непонятно, как с ними правильно работать. Об этом пойдет речь ниже.
Google Universal Campaign - один из источников трафика для нашей игры. Мы оптимизируем кампании под инсталлы, поэтому почти все наши игроки с Google неплатящие. Из экспериментов нам уже известно:
1. Если показывать больше рекламы платящим игрокам на первых уровнях, то такие игроки раньше уходят и суммарное количество показанной рекламы таким игрокам меньше.
2. Игроки с Google проходят меньше уровней в игре.
Мы хотим проверить гипотезу: если показывать больше рекламы на первых уровнях игрокам с Google (которые не платят и рано уходят из игры), суммарное количество показов вырастет.
Запускаем эксперимент только на игроках с Google:
Показываем игрокам рекламу сразу, начиная с первого уровня, и убираем ограничение на показ рекламы (можем в течение 1 минуты показать несколько раз). Для контрольной группы показываем только на уровнях 2, 4, 6… и оставляем ограничение - не более 1 показа в минуту.
Результат. Суммарное количество показов выросло: доверительный интервал -0.098 — 2.94, вероятность 93.2%. Хотя и рекомендуют принимать решение при вероятности выше 95%, мы немного жульничаем и делаем вывод — показываем игрокам с Google больше рекламы на первых уровнях.
{kind=link}
4 июля начинается онлайн интенсив по математической статистике, который проведут наши друзья Виталий Черемисинов и Искандер Мирмахмадов.
Ребята - настоящие специалисты своего дела, которые сильно помогли нам создать нашу платформу. Мы уверены, что они помогут и Вам погрузиться в статистику и разобраться в нюансах проведения А/В-тестов.
Подробная информация: https://www.experiment-fest.ru/ab_course
Ребята - настоящие специалисты своего дела, которые сильно помогли нам создать нашу платформу. Мы уверены, что они помогут и Вам погрузиться в статистику и разобраться в нюансах проведения А/В-тестов.
Подробная информация: https://www.experiment-fest.ru/ab_course
Как правильно выставить цену для in-app’а?
Мы добавили в игру новое специальное предложение, которое дает игроку треть всего внутриигрового контента. Цена - $10. Продажи прут, но на душе неспокойно: “А может мы продешевили? Может надо было $15 сделать? Или вообще $20!”. Ставим эксперимент! Для начала поймем, что такое правильная цена. Рассмотрим следующие варианты.
1. Самая высокая цена.
Вряд-ли. Если поставить цену в $100, покупателей можно и не дождаться.
2. Цена, при которой доход с продажи продукта максимален.
Этот ответ кажется более разумным, но он тоже плохой. Игроки могут больше покупать ваш новый продукт, а старые продукты наоборот - перестать покупать. Проиграем в общем доходе.
3. Цена, при которой суммарный доход максимален.
Похоже, это правильный ответ. С каких бы других продуктов игроки не перескакивали на наш новый, главное, чтобы сумма денежных поступлений по всем продуктам была максимальной.
С задачей разобрались. Подумаем над технической реализацией. Нам надо выставлять цену в каком-то конфиге на облаке и следить за суммарным доходом по игре. Но Google Play позволяет заводить in-app’ы только в игре, и цена на in-app фиксирована. Как нам менять ее?
1. Заводим каждому in-app’у айдишник в игре. Например, ID = SpecialOffer.
2. Заводим несколько in-app’ов на Google Play с разной ценой. Например: SpecialOffer15, SpecialOffer17 и SpecialOffer20.
3. Выносим в конфигуратор на облаке соответствие <ID в игре — ID in-app’а на Google Play>. Например: <SpecialOffer — SpecialOffer15>, где SpecialOffer15 - это ID in-app’а с ценой $15, который мы завели на Google Play.
4. На каждый SpecialOffer со своей ценой проводим AB-тест, в котором сравниваем его с контрольной группой.
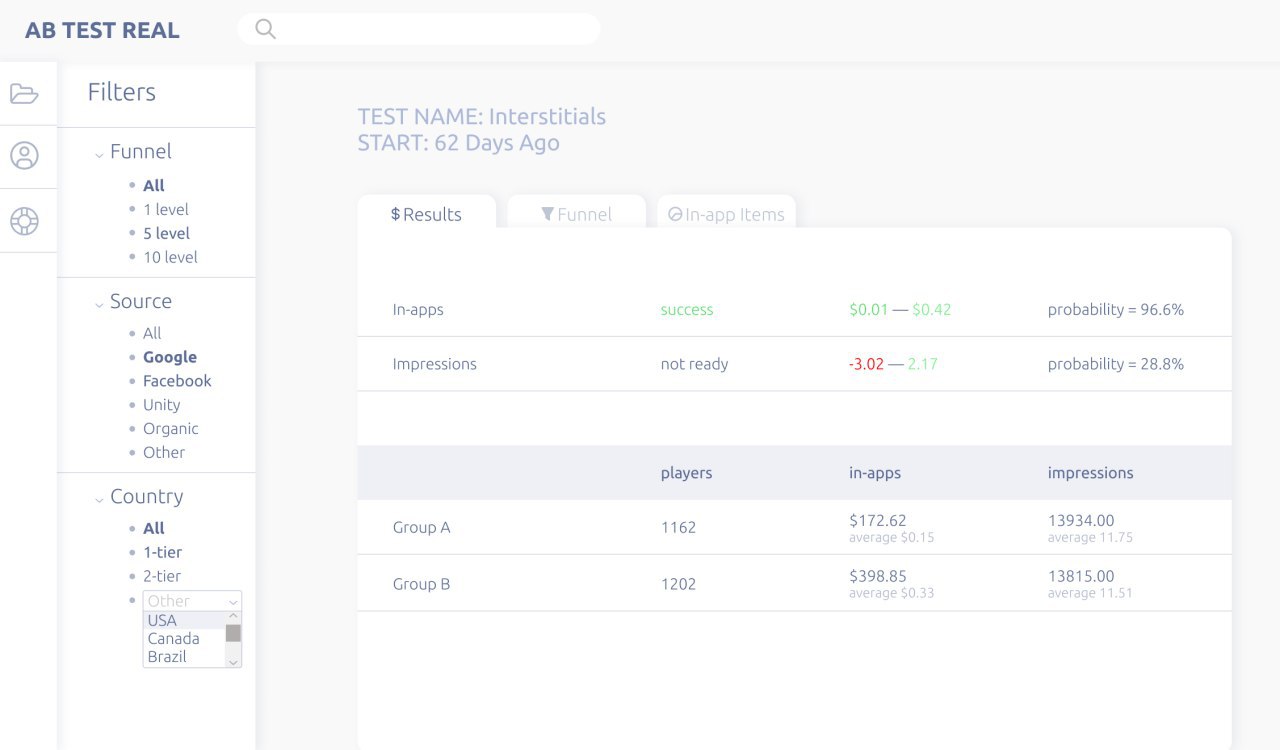
Говорим игре “возьми для контрольной группы in-app с ценой $10, а для экспериментальной $15”. Запускаем эксперимент и получаем результат: улучшение в in-apps от $0.01 до $0.42 с вероятностью 96.6%, а impressions не изменились. Мы получили знание “Цена $15 лучше цены $10”, поэтому меняем нашу цену в игре с $10 на $15 и продолжаем эксперименты!
… с помощью платформы abtestreal.com
Мы добавили в игру новое специальное предложение, которое дает игроку треть всего внутриигрового контента. Цена - $10. Продажи прут, но на душе неспокойно: “А может мы продешевили? Может надо было $15 сделать? Или вообще $20!”. Ставим эксперимент! Для начала поймем, что такое правильная цена. Рассмотрим следующие варианты.
1. Самая высокая цена.
Вряд-ли. Если поставить цену в $100, покупателей можно и не дождаться.
2. Цена, при которой доход с продажи продукта максимален.
Этот ответ кажется более разумным, но он тоже плохой. Игроки могут больше покупать ваш новый продукт, а старые продукты наоборот - перестать покупать. Проиграем в общем доходе.
3. Цена, при которой суммарный доход максимален.
Похоже, это правильный ответ. С каких бы других продуктов игроки не перескакивали на наш новый, главное, чтобы сумма денежных поступлений по всем продуктам была максимальной.
С задачей разобрались. Подумаем над технической реализацией. Нам надо выставлять цену в каком-то конфиге на облаке и следить за суммарным доходом по игре. Но Google Play позволяет заводить in-app’ы только в игре, и цена на in-app фиксирована. Как нам менять ее?
1. Заводим каждому in-app’у айдишник в игре. Например, ID = SpecialOffer.
2. Заводим несколько in-app’ов на Google Play с разной ценой. Например: SpecialOffer15, SpecialOffer17 и SpecialOffer20.
3. Выносим в конфигуратор на облаке соответствие <ID в игре — ID in-app’а на Google Play>. Например: <SpecialOffer — SpecialOffer15>, где SpecialOffer15 - это ID in-app’а с ценой $15, который мы завели на Google Play.
4. На каждый SpecialOffer со своей ценой проводим AB-тест, в котором сравниваем его с контрольной группой.
Говорим игре “возьми для контрольной группы in-app с ценой $10, а для экспериментальной $15”. Запускаем эксперимент и получаем результат: улучшение в in-apps от $0.01 до $0.42 с вероятностью 96.6%, а impressions не изменились. Мы получили знание “Цена $15 лучше цены $10”, поэтому меняем нашу цену в игре с $10 на $15 и продолжаем эксперименты!
… с помощью платформы abtestreal.com
{kind=link}
Как не потерять доход, отдыхая в Тайланде
Мы - руководители игровых студий - находимся в постоянном страхе. С годами он уменьшается, но все равно каждое обновление игры - это мини-стресс.
Произойти может всякое:
- Игра может крэшиться на каком-то уровне, а игроки уходить навсегда.
- Разработчик может случайно пару рекламных сеток отрубить.
- Кнопку “купить” можно сделать невидимой и пропустить во время тестирования.
Баги в играх - норма жизни. Да, мы стремимся их минимизировать, но у вас наверняка тоже были случаи, когда вы выкатили в продакшн какую-то дичь. Поэтому любой новый билд мы сначала выкладываем на 50% аудитории в продакшн и сравниванием его с текущим стабильным билдом.
Я на Новый Год свалил в Тайланд и утром, проверяя дашборд, увидел такую картину - смотри картинку. Грустный смайлик в дашборде сообщил мне: “Эй! На 6-ом уровне статистически значимое проседание в 9%!”. После такого сигнала я сразу откатил тестовый билд и отправил разработчикам: “Ребят, на 6-ом уровне что-то не то. Посмотрите, пожалуйста”.
Мне не надо разбираться, в чем там дело. Мне не надо скачивать игру и смотреть на 6-ой уровень. Мне не надо знать, что планировали разработчики в апдейте. Вся необходимая информация у меня уже есть. Я просто закрываю ноут и иду к шезлонгу.
И вы можете также - подключайтесь к нашей платформе abtestreal.com
Мы - руководители игровых студий - находимся в постоянном страхе. С годами он уменьшается, но все равно каждое обновление игры - это мини-стресс.
Произойти может всякое:
- Игра может крэшиться на каком-то уровне, а игроки уходить навсегда.
- Разработчик может случайно пару рекламных сеток отрубить.
- Кнопку “купить” можно сделать невидимой и пропустить во время тестирования.
Баги в играх - норма жизни. Да, мы стремимся их минимизировать, но у вас наверняка тоже были случаи, когда вы выкатили в продакшн какую-то дичь. Поэтому любой новый билд мы сначала выкладываем на 50% аудитории в продакшн и сравниванием его с текущим стабильным билдом.
Я на Новый Год свалил в Тайланд и утром, проверяя дашборд, увидел такую картину - смотри картинку. Грустный смайлик в дашборде сообщил мне: “Эй! На 6-ом уровне статистически значимое проседание в 9%!”. После такого сигнала я сразу откатил тестовый билд и отправил разработчикам: “Ребят, на 6-ом уровне что-то не то. Посмотрите, пожалуйста”.
Мне не надо разбираться, в чем там дело. Мне не надо скачивать игру и смотреть на 6-ой уровень. Мне не надо знать, что планировали разработчики в апдейте. Вся необходимая информация у меня уже есть. Я просто закрываю ноут и иду к шезлонгу.
И вы можете также - подключайтесь к нашей платформе abtestreal.com
{kind=link}
Как жулики помогают нам больше зарабатывать
На любую надежную и стройную систему всегда найдется ломатель. Там, где есть товар, всегда есть вор.
Работая с разными системами аналитики, мы начали обращать внимание на отличие суммы на графиках и суммы выплат платформы (App Store или Google Play). Причина простая - fraud. Игрок обманывает игру и получает внутриигровой контент бесплатно.
Техническая сторона чаще всего такая:
1. Жулик скачивает приложение, которое стоит между вызовами игры и Google Play.
2. Жулик делает в игре запрос на покупку.
3. Подключается промежуточное приложение, которое принимает этот запрос и высылает игре подтверждение оплаты.
4. Игра, ничего не подозревая, выдает жулику внутриигровой контент.
5. Жулик счастлив.
Решение простое - перед шагом 4 игра отправляет запрос на свой сервер, про который не знает приложение жулика, для проверки транзакции. Выявлять жуликов мы научились. Что теперь с ними делать? Первая наша мысль - банить игроков-жуликов, но мы провели AB-эксперимент.
В контрольной группе мы не давали in-app’ы игрокам-жуликам. В экспериментальной давали жуликам контент, который они хотели получить, и отмечали таких игроков как жуликов. Экспериментальная группа получила статистически значимое увеличение показов рекламы! Оказалось, что жулики нам полезны даже с учетом наворованного.
Поэтому сейчас мы “поддаемся” жуликам и помечаем их для корректного раcчёта in-app’ов. А как fraud отражается на вашей игре? Проверьте с помощью платформы abtestreal.com
На любую надежную и стройную систему всегда найдется ломатель. Там, где есть товар, всегда есть вор.
Работая с разными системами аналитики, мы начали обращать внимание на отличие суммы на графиках и суммы выплат платформы (App Store или Google Play). Причина простая - fraud. Игрок обманывает игру и получает внутриигровой контент бесплатно.
Техническая сторона чаще всего такая:
1. Жулик скачивает приложение, которое стоит между вызовами игры и Google Play.
2. Жулик делает в игре запрос на покупку.
3. Подключается промежуточное приложение, которое принимает этот запрос и высылает игре подтверждение оплаты.
4. Игра, ничего не подозревая, выдает жулику внутриигровой контент.
5. Жулик счастлив.
Решение простое - перед шагом 4 игра отправляет запрос на свой сервер, про который не знает приложение жулика, для проверки транзакции. Выявлять жуликов мы научились. Что теперь с ними делать? Первая наша мысль - банить игроков-жуликов, но мы провели AB-эксперимент.
В контрольной группе мы не давали in-app’ы игрокам-жуликам. В экспериментальной давали жуликам контент, который они хотели получить, и отмечали таких игроков как жуликов. Экспериментальная группа получила статистически значимое увеличение показов рекламы! Оказалось, что жулики нам полезны даже с учетом наворованного.
Поэтому сейчас мы “поддаемся” жуликам и помечаем их для корректного раcчёта in-app’ов. А как fraud отражается на вашей игре? Проверьте с помощью платформы abtestreal.com
Если вы что-то ищете, то вы всегда найдете “что-то”
Как-то наблюдал такой разговор:
Разработчик: Завтра мы выкатываем новую фичу
Аналитик: ОК. Затречьте мне как можно больше событий. Мне нужны: конверсия захода в магазин, количество кликов на кнопке с новой фичей, воронка прохождения игрока от туториала до покупки и список трат ресурсов.
Разработчик: На что ты будешь смотреть в первую очередь?
Аналитик: На все. Посмотрим, как фича зашла игрокам.
Разработчик: При каких условиях мы будем откатывать фичу?
Аналитик: Ни при каких. Если какие-то параметры просядут, будем думать, как улучшить эти параметры.
Если говорить совсем просто, то такая практика порочна. Представьте себе такой эксперимент. Вместо конверсии и воронки вы смотрите, как разные люди подбрасывают монетку 5 раз. Мы знаем, что вероятность выброса орла составляет 50%. Допустим, 5 человек подбрасывают монетку.
Вася: Орел, Решка, Решка, Орел, Орел
Петя: Решка, Решка, Орел, Орел, Орел
Ваня: Решка, Решка, Решка, Решка, Орел
Слава: Решка, Решка, Орел, Орел, Орел
Игорь: Орел, Орел, Решка, Орел, Орел
Если вы рассуждаете как аналитик из примера, то вы можете подумать: “А Ваня хорош в решке! Надо его промоутить как-то. И надо еще на Игоря обратить внимание - как он так научился орлы выбрасывать? Может мы и этому навыку найдем применение?”. Хотя выпадания случайны. Да, пример выглядит абсурдно, но так работают очень многие в игровой индустрии. Очень многие ищут “что-то” и “что-то” находят.
Некорректные множественные сравнения - это одна из форм p-hacking’а. При производстве лекарств нечистоплотные производители ставят большое число экспериментов и, когда они закончены, выбирают тот, который соответствует их гипотезе.
Этот трюк давно известен в научной среде, поэтому если вы хотите опубликовать свою работу в серьезном научном журнале, вы должны подать заявку со списком отслеживаемых параметров ДО ЭКСПЕРИМЕНТА. Вас просто не опубликуют в журнале, если вы придете в один день и заявите: “После новой фичи у нас вырос LTV на игрока!”.
Что делать?
Есть разные способы, но в целом - определяться с отслеживаемыми параметрами до выката фичи. Если вы хотите отслеживать какие-то другие параметры, отслеживайте их в рамках следующих экспериментов.
Возникает вопрос: “А если я хочу смотреть на среднее время сессии, ретеншн, LTV и конверсию?”. Ответ: “Не надо так!”.
Статей на эту тему просто гора. Но самые доходчивые мы нашли в книжке “Доказательная медицина от магии до поисков бессмертия”, Талантов Петр.
Как-то наблюдал такой разговор:
Разработчик: Завтра мы выкатываем новую фичу
Аналитик: ОК. Затречьте мне как можно больше событий. Мне нужны: конверсия захода в магазин, количество кликов на кнопке с новой фичей, воронка прохождения игрока от туториала до покупки и список трат ресурсов.
Разработчик: На что ты будешь смотреть в первую очередь?
Аналитик: На все. Посмотрим, как фича зашла игрокам.
Разработчик: При каких условиях мы будем откатывать фичу?
Аналитик: Ни при каких. Если какие-то параметры просядут, будем думать, как улучшить эти параметры.
Если говорить совсем просто, то такая практика порочна. Представьте себе такой эксперимент. Вместо конверсии и воронки вы смотрите, как разные люди подбрасывают монетку 5 раз. Мы знаем, что вероятность выброса орла составляет 50%. Допустим, 5 человек подбрасывают монетку.
Вася: Орел, Решка, Решка, Орел, Орел
Петя: Решка, Решка, Орел, Орел, Орел
Ваня: Решка, Решка, Решка, Решка, Орел
Слава: Решка, Решка, Орел, Орел, Орел
Игорь: Орел, Орел, Решка, Орел, Орел
Если вы рассуждаете как аналитик из примера, то вы можете подумать: “А Ваня хорош в решке! Надо его промоутить как-то. И надо еще на Игоря обратить внимание - как он так научился орлы выбрасывать? Может мы и этому навыку найдем применение?”. Хотя выпадания случайны. Да, пример выглядит абсурдно, но так работают очень многие в игровой индустрии. Очень многие ищут “что-то” и “что-то” находят.
Некорректные множественные сравнения - это одна из форм p-hacking’а. При производстве лекарств нечистоплотные производители ставят большое число экспериментов и, когда они закончены, выбирают тот, который соответствует их гипотезе.
Этот трюк давно известен в научной среде, поэтому если вы хотите опубликовать свою работу в серьезном научном журнале, вы должны подать заявку со списком отслеживаемых параметров ДО ЭКСПЕРИМЕНТА. Вас просто не опубликуют в журнале, если вы придете в один день и заявите: “После новой фичи у нас вырос LTV на игрока!”.
Что делать?
Есть разные способы, но в целом - определяться с отслеживаемыми параметрами до выката фичи. Если вы хотите отслеживать какие-то другие параметры, отслеживайте их в рамках следующих экспериментов.
Возникает вопрос: “А если я хочу смотреть на среднее время сессии, ретеншн, LTV и конверсию?”. Ответ: “Не надо так!”.
Статей на эту тему просто гора. Но самые доходчивые мы нашли в книжке “Доказательная медицина от магии до поисков бессмертия”, Талантов Петр.
{kind=link}
Что мы делаем, когда разработчики заняты
Порой разработчики длительно заняты большой задачей. Например, 3 недели назад мы начали пилить крупный апдейт, который займет примерно месяц. Раньше мы сильно переживали, что игроки надолго остаются без апдейтов. Учитывая, что много апдейтов мы откатываем, можно загрустить.
Сейчас вместо того чтобы торопить разработчиков и срывать нервы, мы:
1. Запускаем тесты на баланс (об этом было подробно в прошлых статьях).
2. Запускаем тесты на удаление фич.
Пункт 2 - наш самый любимый. Запустить его можно очень дешево, а эффект бывает как от дорогой фичи. Рассмотрим пример. В нашей многоуровневой tower defense игре Island Defense есть механика Survival. Крипы вылезают из всех щелей, надо продержаться как можно дольше, чем дольше продержишься, тем больше приз.
Шаги эксперимента:
1. Делим игроков на две группы: контрольная получает версию с фичей (“есть survival”), вторая - без фичи (“нет survival”).
2. Скармливаем данные о покупках и показах рекламы нашей платформе (рассмотрим далее на примере показов).
3. Платформа считает показы для каждого игрока в двух группах: Игрок 2346 - 5 показов, Игрок 5435 - 7 показов, …
4. Собираются данные на 2000-4000 игроков. По предыдущему опыту мы знаем, что примерно на таком количестве наши тесты “красятся”, т.е. платформе достаточно данных для выдачи заключения.
5. Платформа строит распределение разницы средних значений показов через бутстрап. Возможно, страшно прозвучало сейчас :) Бутстрап - это тема отдельной статьи, но если говорить совсем просто, то это моделирование подсчета среднего значения на основе существующих данных. Или еще проще: бутстрап показывает, как могло бы выглядеть среднее на наших данных, если бы они были немного другими.
На графике в этом примере:
1. 95% доверительный интервал разницы находится ниже 0. На человеческий язык это переводится так: “Со значительной степенью уверенности можно говорить, что разница есть”.
2. Границы доверительного интервала: -1.17, -4.64. И опять в переводе на человеческий язык: “Увеличение составляет от 1.17 до 4.64 показа на игрока”.
Ура! Времени потрачено мало, а эффект большой! Выпиливаем survival, чтобы показывать еще больше рекламы игрокам.
Честно говоря, мы показали хороший сценарий, что происходит редко. В большинстве случаев мы не ждем, что выпиливание фичи даст результат. Но когда разработчики заняты, и интересный эксперимент запустить не получается… Почему бы не выпиливать фичи?
Порой разработчики длительно заняты большой задачей. Например, 3 недели назад мы начали пилить крупный апдейт, который займет примерно месяц. Раньше мы сильно переживали, что игроки надолго остаются без апдейтов. Учитывая, что много апдейтов мы откатываем, можно загрустить.
Сейчас вместо того чтобы торопить разработчиков и срывать нервы, мы:
1. Запускаем тесты на баланс (об этом было подробно в прошлых статьях).
2. Запускаем тесты на удаление фич.
Пункт 2 - наш самый любимый. Запустить его можно очень дешево, а эффект бывает как от дорогой фичи. Рассмотрим пример. В нашей многоуровневой tower defense игре Island Defense есть механика Survival. Крипы вылезают из всех щелей, надо продержаться как можно дольше, чем дольше продержишься, тем больше приз.
Шаги эксперимента:
1. Делим игроков на две группы: контрольная получает версию с фичей (“есть survival”), вторая - без фичи (“нет survival”).
2. Скармливаем данные о покупках и показах рекламы нашей платформе (рассмотрим далее на примере показов).
3. Платформа считает показы для каждого игрока в двух группах: Игрок 2346 - 5 показов, Игрок 5435 - 7 показов, …
4. Собираются данные на 2000-4000 игроков. По предыдущему опыту мы знаем, что примерно на таком количестве наши тесты “красятся”, т.е. платформе достаточно данных для выдачи заключения.
5. Платформа строит распределение разницы средних значений показов через бутстрап. Возможно, страшно прозвучало сейчас :) Бутстрап - это тема отдельной статьи, но если говорить совсем просто, то это моделирование подсчета среднего значения на основе существующих данных. Или еще проще: бутстрап показывает, как могло бы выглядеть среднее на наших данных, если бы они были немного другими.
На графике в этом примере:
1. 95% доверительный интервал разницы находится ниже 0. На человеческий язык это переводится так: “Со значительной степенью уверенности можно говорить, что разница есть”.
2. Границы доверительного интервала: -1.17, -4.64. И опять в переводе на человеческий язык: “Увеличение составляет от 1.17 до 4.64 показа на игрока”.
Ура! Времени потрачено мало, а эффект большой! Выпиливаем survival, чтобы показывать еще больше рекламы игрокам.
Честно говоря, мы показали хороший сценарий, что происходит редко. В большинстве случаев мы не ждем, что выпиливание фичи даст результат. Но когда разработчики заняты, и интересный эксперимент запустить не получается… Почему бы не выпиливать фичи?
{kind=link}
Как мы выбираем, ЧТО тестировать дальше
Когда стоит выбор, в какой области игры проводить следующий АВ-тест, у нас есть 2 варианта:
1. Искать новые точки роста.
2. Прокачивать существующие.
Мы недавно запустили новую игру и первым делом начали прогонять тесты на баланс и улучшение воронки уровней. Ранее мы писали, что запускаем серию АВ-тестов и подбираем оптимальное значение HP врагов, меняя коэффициент K в формуле: HP крипа = базовое HP * K.
Сначала мы запускаем серию тестов на “поиск точек роста”, чтобы подобрать оптимальное K. Успехом мы будем считать прохождение игроком игры как можно дальше по воронке уровней: 1-ый, 2-ой, 3-ий и т.д.
В играх, которые уже существуют долго, мы так никогда не делаем. В них нас интересуют в первую очередь деньги, а не прохождение. Но т.к. у этой игры монетизация еще не настроена, мы можем позволить себе запустить несколько АВ-тестов на продвижение игроков вглубь игры.
1. Первым шагом мы настраиваем идеальный, с нашей точки зрения как игроков, баланс с K=1.
2. Потом мы запускаем АВ-тест с K=0.8 (у крипов меньше здоровья, уровни простые) и сравниваем значение с контрольной группой, где K=1.
3. Затем с K=1.2 (у крипов совсем много здоровья, уровни совсем сложные).
Получаем результаты тестов:
1. Вариант с K=1.2 (сложный) оказался хуже контрольной группы.
2. Вариант с K=0.8 (легкий) оказался лучше контрольной группы.
Ура! Мы улучшили игру!
Но мы еще и получили знание. Похоже, что мы как разработчики предпочитаем более сложный вариант баланса, чем наши игроки. Взяв эту мысль за гипотезу, мы попробуем прокачать существующую точку роста. Давайте попробуем сделать K=0.6? Сразу скажу, этот тест команда запускает с каменными лицами. С K=1 - играть было интересно. С K=0.8 игра из стратегии уже превратилась в какой-то кликер. K=0.6 - это уже вообще за гранью. Запускаем тест и получаем еще один успешный результат.
Как аналитики мы счастливы. Как разработчики мы получили баланс, который нам не нравится абсолютно. Такая вот точка роста.
Следующим нашим тестом будет K=0.4. А потом будем расставлять пэйволы!
Когда стоит выбор, в какой области игры проводить следующий АВ-тест, у нас есть 2 варианта:
1. Искать новые точки роста.
2. Прокачивать существующие.
Мы недавно запустили новую игру и первым делом начали прогонять тесты на баланс и улучшение воронки уровней. Ранее мы писали, что запускаем серию АВ-тестов и подбираем оптимальное значение HP врагов, меняя коэффициент K в формуле: HP крипа = базовое HP * K.
Сначала мы запускаем серию тестов на “поиск точек роста”, чтобы подобрать оптимальное K. Успехом мы будем считать прохождение игроком игры как можно дальше по воронке уровней: 1-ый, 2-ой, 3-ий и т.д.
В играх, которые уже существуют долго, мы так никогда не делаем. В них нас интересуют в первую очередь деньги, а не прохождение. Но т.к. у этой игры монетизация еще не настроена, мы можем позволить себе запустить несколько АВ-тестов на продвижение игроков вглубь игры.
1. Первым шагом мы настраиваем идеальный, с нашей точки зрения как игроков, баланс с K=1.
2. Потом мы запускаем АВ-тест с K=0.8 (у крипов меньше здоровья, уровни простые) и сравниваем значение с контрольной группой, где K=1.
3. Затем с K=1.2 (у крипов совсем много здоровья, уровни совсем сложные).
Получаем результаты тестов:
1. Вариант с K=1.2 (сложный) оказался хуже контрольной группы.
2. Вариант с K=0.8 (легкий) оказался лучше контрольной группы.
Ура! Мы улучшили игру!
Но мы еще и получили знание. Похоже, что мы как разработчики предпочитаем более сложный вариант баланса, чем наши игроки. Взяв эту мысль за гипотезу, мы попробуем прокачать существующую точку роста. Давайте попробуем сделать K=0.6? Сразу скажу, этот тест команда запускает с каменными лицами. С K=1 - играть было интересно. С K=0.8 игра из стратегии уже превратилась в какой-то кликер. K=0.6 - это уже вообще за гранью. Запускаем тест и получаем еще один успешный результат.
Как аналитики мы счастливы. Как разработчики мы получили баланс, который нам не нравится абсолютно. Такая вот точка роста.
Следующим нашим тестом будет K=0.4. А потом будем расставлять пэйволы!
Сигнал и шум
Не все улучшения игры видно сразу. Когда мы вносим исправления в туториал в начале игры, обычно мы сразу видим результат. Много игроков проходят начальное обучение -> много игроков остаются в игре -> много просмотров рекламы. Самое приятное, что эти изменения мы видим практически сразу же в первый день после выката изменения.
Совсем другое дело, когда мы выкатываем изменения на поздних этапах игры. Если мы внесли исправления на 100-ом уровне, на котором у нас 1% игроков, как мы поймем, что игроки оценили изменения? Даже если изменения будут значительными, их очень сложно разглядеть на 1% игроков.
Для этого мы используем фильтры. Смотрим на стат. значимость изменений не по всем игрокам, а только по тем, которые дошли до 100-го уровня. Таким образом мы устраняем шум - не рассматриваем игроков, которые не дошли до 100-го уровня.
Мы проводили такой эксперимент. В нашей tower defense игре в конце уровня выходил босс - большой сильный крип, которого сложно убить. Уровни поздние, поэтому в рамках эксперимента мы не видели ничего. Отфильтровали только тех игроков, которые реально дошли до уровня с боссом, и увидели проседание в конверсии. Похоже, что игрокам не нужны боссы. Тогда мы попробовали оставить босса как графический элемент, но сделать его таким же слабым как остальные крипы. Т.е. визуал стал интереснее, но геймплей особо не изменился. На таком изменении мы увидели стат. значимость.
Возникает вопрос: Зачем вообще вносить изменения, которые можно увидеть только под микроскопом?
Да, мы стараемся менять игру для всех. Но иногда бывает полезно нащупать стратегическое направление. Например, по незначительному изменению на 100-ом уровне мы видим, что игрокам оно интересно, а следовательно можно продолжать развивать игру в таком же направлении.
Не все улучшения игры видно сразу. Когда мы вносим исправления в туториал в начале игры, обычно мы сразу видим результат. Много игроков проходят начальное обучение -> много игроков остаются в игре -> много просмотров рекламы. Самое приятное, что эти изменения мы видим практически сразу же в первый день после выката изменения.
Совсем другое дело, когда мы выкатываем изменения на поздних этапах игры. Если мы внесли исправления на 100-ом уровне, на котором у нас 1% игроков, как мы поймем, что игроки оценили изменения? Даже если изменения будут значительными, их очень сложно разглядеть на 1% игроков.
Для этого мы используем фильтры. Смотрим на стат. значимость изменений не по всем игрокам, а только по тем, которые дошли до 100-го уровня. Таким образом мы устраняем шум - не рассматриваем игроков, которые не дошли до 100-го уровня.
Мы проводили такой эксперимент. В нашей tower defense игре в конце уровня выходил босс - большой сильный крип, которого сложно убить. Уровни поздние, поэтому в рамках эксперимента мы не видели ничего. Отфильтровали только тех игроков, которые реально дошли до уровня с боссом, и увидели проседание в конверсии. Похоже, что игрокам не нужны боссы. Тогда мы попробовали оставить босса как графический элемент, но сделать его таким же слабым как остальные крипы. Т.е. визуал стал интереснее, но геймплей особо не изменился. На таком изменении мы увидели стат. значимость.
Возникает вопрос: Зачем вообще вносить изменения, которые можно увидеть только под микроскопом?
Да, мы стараемся менять игру для всех. Но иногда бывает полезно нащупать стратегическое направление. Например, по незначительному изменению на 100-ом уровне мы видим, что игрокам оно интересно, а следовательно можно продолжать развивать игру в таком же направлении.
Как не надо считать деньги
Мы в Stereo7 делаем игры, главная задача которых - приносить нам деньги. Внедряя новые механики в игры, мы хотим больше зарабатывать. Когда мы внедряем новую фичу в игру, мы хотим знать хотя бы примерно, сколько денег она принесла. Для этого мы используем A/B-тестирование. Каждый игрок случайным образом получает либо вариант А (без фичи), либо вариант B (с фичей). Этой статьей мы перечислим неправильные способы считать деньги при A/B-тестировании. Все приемы ниже мы наблюдали либо в реальной работе, либо в обсуждениях тематических сообществ.
1. Вычисление суммарных значений
В варианте А (игра без фичи) - 1000 игроков заплатили суммарно $1000. В варианте B (игра с фичей) - 1000 игроков заплатили суммарно $10,000. Ура, новая фича принесла нам дополнительные $9000! Фиксируем улучшение в 1000% и идем отмечать в ближайший бар.
К сожалению для аналитиков и к счастью для всех остальных, есть специфика мобильных игр - игроки очень разные. Один может заплатить $1, другой - в 10 тысяч раз больше. Что будет, если мы посмотрим в сырые данные эксперимента? Может в варианте А у нас 1000 платежей в $1, а в варианте B один случайный платеж в 10000. Вариант B уже не выглядит таким классным - это просто случайность. Игрок-транжира мог и в первой группе с таким же успехом оказаться. Поход в бар отменяется.
2. Мониторинг конверсии
“Большая конверсия - хорошо. Маленькая - плохо. Надо стремиться увеличивать конверсию!”.
Красиво заявление, но к деньгам неприменимо. В супермаркете возле вашего дома конверсия 100%, т.к. каждый посетитель что-нибудь покупает. В магазине Gucci конверсия может быть пониже, но вряд-ли они завидуют супермаркету у дома у которого конверсия 100%. С точки зрения микроэкономики, у каждого товара есть оптимальная цена, при которой прибыль максимальна. Часто бывает так, что с повышением цены товара растет прибыль. Конверсия при этом падает. Падает, и фиг бы с ней! Главное, чтобы прибыль была больше.
3. Использование калькуляторов конверсий для A/B-тестов
Часто концепция выше подается под соусом “научности”. Берется знаменитый калькулятор для A/B-тестов (типа evanmiller.org), которому на вход подается: общее число пользователей для вариантов А и В и число конвертированных пользователей для вариантов А и В. И на выходе калькулятор говорит “есть” или “нет статистической значимости”. К сожалению, усложнение неправильной концепции (смотри пункт 1) не делает ее правильной, а частый совет на вопрос “Как считать?” - “Используй калькуляторы!” в этом случае неприменим.
4. Использование T-test (критерия Стьюдента)
“А мы же в институте проходили это! Все давно уже придумано до нас! Загоняем данные в статистический критерий T-test, и он сам нам скажет, есть статистическая значимость или нет”. Любой статистический критерий имеет какие-то требования. Например, для T-критерия есть такие требования:
а) Нормальность распределения
Почему-то в институте на парах тервера всем нам вдолбили мысль, что вообще любые данные нормально распределены. Эта мысль настолько укоренилась в наших головах, что некоторые “отличники” готовы выборы объявить недобросовестными, просто потому что распределение ненормальное. Пример: habr.com/ru/post/352424.
Если поразмыслить на эту тему больше 5 минут, то понятно, что график распределения платежей - это может быть просто 2 дискретные палки. По оси X цена товара $1 и $10, например. Ну т.е. никакого нормального распределения нет и критерий применять нельзя.
б) Независимость выборок
Один пользователь может заплатить несколько раз. Поэтому ваши выборки уже содержат “зависимые” данные. Это проблема легко решается, но в целом все равно надо понимать, что вы делаете.
Возникает вопрос - как правильно считать деньги? Ответа простого нет. Сложный такой: “Зависит от объема и характера ваших данных”. Мы в своей платформе abtestreal.com используем в частности бутстрэп, про который мы напишем в следующих статьях. Нам было бы очень интересно на эту тему пообщаться. Какой подход вы используете в вашей компании? Пишите в комментариях. Если тема чувствительная, давайте в личке обсудим?
Мы в Stereo7 делаем игры, главная задача которых - приносить нам деньги. Внедряя новые механики в игры, мы хотим больше зарабатывать. Когда мы внедряем новую фичу в игру, мы хотим знать хотя бы примерно, сколько денег она принесла. Для этого мы используем A/B-тестирование. Каждый игрок случайным образом получает либо вариант А (без фичи), либо вариант B (с фичей). Этой статьей мы перечислим неправильные способы считать деньги при A/B-тестировании. Все приемы ниже мы наблюдали либо в реальной работе, либо в обсуждениях тематических сообществ.
1. Вычисление суммарных значений
В варианте А (игра без фичи) - 1000 игроков заплатили суммарно $1000. В варианте B (игра с фичей) - 1000 игроков заплатили суммарно $10,000. Ура, новая фича принесла нам дополнительные $9000! Фиксируем улучшение в 1000% и идем отмечать в ближайший бар.
К сожалению для аналитиков и к счастью для всех остальных, есть специфика мобильных игр - игроки очень разные. Один может заплатить $1, другой - в 10 тысяч раз больше. Что будет, если мы посмотрим в сырые данные эксперимента? Может в варианте А у нас 1000 платежей в $1, а в варианте B один случайный платеж в 10000. Вариант B уже не выглядит таким классным - это просто случайность. Игрок-транжира мог и в первой группе с таким же успехом оказаться. Поход в бар отменяется.
2. Мониторинг конверсии
“Большая конверсия - хорошо. Маленькая - плохо. Надо стремиться увеличивать конверсию!”.
Красиво заявление, но к деньгам неприменимо. В супермаркете возле вашего дома конверсия 100%, т.к. каждый посетитель что-нибудь покупает. В магазине Gucci конверсия может быть пониже, но вряд-ли они завидуют супермаркету у дома у которого конверсия 100%. С точки зрения микроэкономики, у каждого товара есть оптимальная цена, при которой прибыль максимальна. Часто бывает так, что с повышением цены товара растет прибыль. Конверсия при этом падает. Падает, и фиг бы с ней! Главное, чтобы прибыль была больше.
3. Использование калькуляторов конверсий для A/B-тестов
Часто концепция выше подается под соусом “научности”. Берется знаменитый калькулятор для A/B-тестов (типа evanmiller.org), которому на вход подается: общее число пользователей для вариантов А и В и число конвертированных пользователей для вариантов А и В. И на выходе калькулятор говорит “есть” или “нет статистической значимости”. К сожалению, усложнение неправильной концепции (смотри пункт 1) не делает ее правильной, а частый совет на вопрос “Как считать?” - “Используй калькуляторы!” в этом случае неприменим.
4. Использование T-test (критерия Стьюдента)
“А мы же в институте проходили это! Все давно уже придумано до нас! Загоняем данные в статистический критерий T-test, и он сам нам скажет, есть статистическая значимость или нет”. Любой статистический критерий имеет какие-то требования. Например, для T-критерия есть такие требования:
а) Нормальность распределения
Почему-то в институте на парах тервера всем нам вдолбили мысль, что вообще любые данные нормально распределены. Эта мысль настолько укоренилась в наших головах, что некоторые “отличники” готовы выборы объявить недобросовестными, просто потому что распределение ненормальное. Пример: habr.com/ru/post/352424.
Если поразмыслить на эту тему больше 5 минут, то понятно, что график распределения платежей - это может быть просто 2 дискретные палки. По оси X цена товара $1 и $10, например. Ну т.е. никакого нормального распределения нет и критерий применять нельзя.
б) Независимость выборок
Один пользователь может заплатить несколько раз. Поэтому ваши выборки уже содержат “зависимые” данные. Это проблема легко решается, но в целом все равно надо понимать, что вы делаете.
Возникает вопрос - как правильно считать деньги? Ответа простого нет. Сложный такой: “Зависит от объема и характера ваших данных”. Мы в своей платформе abtestreal.com используем в частности бутстрэп, про который мы напишем в следующих статьях. Нам было бы очень интересно на эту тему пообщаться. Какой подход вы используете в вашей компании? Пишите в комментариях. Если тема чувствительная, давайте в личке обсудим?
{kind=link}
Как обнаружить проблему
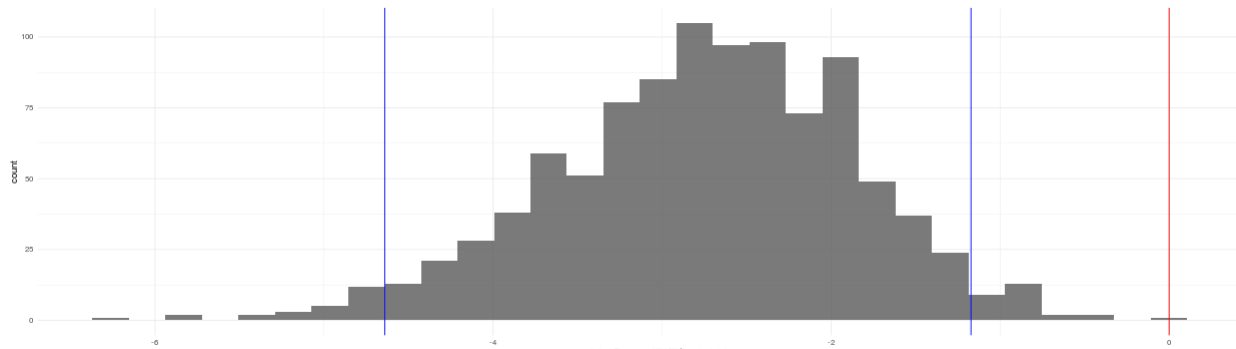
Сегодня мы столкнулись с очень неприятной ситуацией. Мы собрали результаты АБ теста, который запустили в начале недели. Тест показал проседание в рекламе. Вероятность 100%. В среднем мы потеряли примерно 20% от всех impressions (смотри скриншот).
Катастрофа. Ужас. Пожар.
Эксперимент был такой: добавить 20 новых уровней в игру. Каким образом 20 новых уровней могли так сильно сломать рекламу? Непонятно.
1. Может быть новые уровни как-то сломали более ранние уровни?
Например новый контент мог привести к крэшам из-за нехватки памяти.
Мы посмотрели на среднее количество уровней, которые проходит игрок. Оно не изменилось (изменение с вероятностью 7.4% - очень маленькая)
2. Более того. Когда мы посмотрели на воронку - ни один игрок даже не дошел до новых уровней!
На основе этих данных мы делаем вывод: проблема не связана с новыми уровнями.
Но как такое может быть если кроме новых уровней мы ничего не выкладывали?
Начали смотреть коммиты в репозитории. О оказалось что в процессе выкладки, мы случайно выпилили старый фикс бага, который относился к рекламе. Об этом никто не знал, но система все равно "не пропустила" плохой билд.
Иногда в билды проникают изменения о которых мы не знаем. Иногда такие изменения портят игру. Но если каждый билд мы прогоняем через АБ тесты, мы можем обнаружить проблему и все поправить.
Сегодня мы столкнулись с очень неприятной ситуацией. Мы собрали результаты АБ теста, который запустили в начале недели. Тест показал проседание в рекламе. Вероятность 100%. В среднем мы потеряли примерно 20% от всех impressions (смотри скриншот).
Катастрофа. Ужас. Пожар.
Эксперимент был такой: добавить 20 новых уровней в игру. Каким образом 20 новых уровней могли так сильно сломать рекламу? Непонятно.
1. Может быть новые уровни как-то сломали более ранние уровни?
Например новый контент мог привести к крэшам из-за нехватки памяти.
Мы посмотрели на среднее количество уровней, которые проходит игрок. Оно не изменилось (изменение с вероятностью 7.4% - очень маленькая)
2. Более того. Когда мы посмотрели на воронку - ни один игрок даже не дошел до новых уровней!
На основе этих данных мы делаем вывод: проблема не связана с новыми уровнями.
Но как такое может быть если кроме новых уровней мы ничего не выкладывали?
Начали смотреть коммиты в репозитории. О оказалось что в процессе выкладки, мы случайно выпилили старый фикс бага, который относился к рекламе. Об этом никто не знал, но система все равно "не пропустила" плохой билд.
Иногда в билды проникают изменения о которых мы не знаем. Иногда такие изменения портят игру. Но если каждый билд мы прогоняем через АБ тесты, мы можем обнаружить проблему и все поправить.
{kind=link}