Forwarded from Алексей
Зародыши мозга в лаборатории проявили спонтанную согласованную активность
У мини-мозга (органоида) зарегистрирована ритмическая электрическая активность.
———
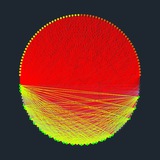
Этой весной из нейронов со стохастическими бинарными синапсами я собрал свой искусственный мини-брэйн, и он так же, спустя некоторое время, затраченное на формирование связей, продемонстрировал ритмическую активность как и его биологический прототип. Причём путём тюнинга можно добиться практически меандра с крутыми фронтами.
Модель представляет собой полносвязную однослойную сеть. Коннектом самостоятельно формируется благодаря спонтанной активности нейронов.
Судя по карте весов, в сети самоорганизуется небольшая группа нейронов, берущих на себя функцию хабов, с которыми имеют слабые связи остальные нейроны.
У мини-мозга (органоида) зарегистрирована ритмическая электрическая активность.
———
Этой весной из нейронов со стохастическими бинарными синапсами я собрал свой искусственный мини-брэйн, и он так же, спустя некоторое время, затраченное на формирование связей, продемонстрировал ритмическую активность как и его биологический прототип. Причём путём тюнинга можно добиться практически меандра с крутыми фронтами.
Модель представляет собой полносвязную однослойную сеть. Коннектом самостоятельно формируется благодаря спонтанной активности нейронов.
Судя по карте весов, в сети самоорганизуется небольшая группа нейронов, берущих на себя функцию хабов, с которыми имеют слабые связи остальные нейроны.
Forwarded from Алексей
Встретился мне в каком-то научпоп фильме эксперимент про иерархию. Стайным животным важно понимать своё и чужое место в иерархии. Эксперимент был, если не ошибаюсь, с гусями, которым демонстрировали разноцветные карточки. Левая половина карточки была закрашена в один цвет, правая в другой. Цвета соответствовали цифрам от 1 до 9 (или больше). Цветовое кодирование выбрано видимо для того, чтобы не обучать их ещё распознаванию чисел.
Обучали гусей поощрением едой при демонстрации и, соответственно, выборе гусем карточки, на которой правое число больше левого. А тестировали их на полном наборе. Через какое-то время гуси начинали выбирать верные карточки чаще случайного выбора. То есть, демонстрировали понимание, что 5 больше 1 и т.п.
Я смоделировал такой механизм. Причём он получился элементарным.
Понятно, что у нас есть две сущности с неким взаимоотношением. Можем представить каждую карточку уникальной парой чисел: 1-2. Соберём из тестового набора направленный граф, где вершинам соответствует числа, а ребро указывает на правое число в паре.
Поиск ответа для пары чисел [A, B], упорядоченной по возрастанию - это поиск пути в графе из вершины A в вершину B. Если путь найден, то порядок верный. That's all, folks!
Результаты
Набор из 10 элементов/чисел. Полное число комбинаций = 100; число комбинаций (a < b) = 45.
1) Доля обучающей выборки 25%. Среднее число попаданий 72%
2) Доля обучающей выборки 50%. Среднее число попаданий 88%
Подобный результат гуси и демонстрировали.
Далее я поиграл с количеством объектов и размером обучающей выборки. Перейду к самому интересному.
Набор из 1000 элементов/чисел. Полное число комбинаций = 1000000; число комбинаций (a < b) = 499500.
Доля обучающей выборки 10%. Среднее число попаданий 97%
Чем больше элементов в иерархии, тем точнее результат и тем меньше требуется обучающая выборка (в процентном отношении).
На один элемент из этого примера выходит примерно по 50 связей. То есть, связность вершин друг с другом довольно низкая, 50 / 1000 = 0.05. Но этого достаточно, чтобы связями сшить куски чего-то заранее неизвестной природы в некий континуум, пространство и затем находить в нём путь.
Для оптимизации поиска пути я применил ранее описанный алгоритм волны. "Глубина" распространения волны поиска оказалась менее 10 переходов. То есть, волна возбуждения прокатывается по цепочке длиной менее 10 вершин/нейронов, чтобы успеть найти путь, или затухнуть, если путь не найден. Такая короткая цепочка нейронов для поиска ответа среди 1000 элементов хорошо соответствует факту о небольшой длине нейронной цепи от сенсорных нейронов до моторных.
Так как элементы/вершины - это абстракция, можно получить такой же обучающий набор (и результаты) для других применений. Если привязать к текущим координатам направления взгляда бинаризованные векторы его смены (влево/вправо и вверх/вниз) в следующую позицию, то просто подвигав глазами десятки тысяч раз, получим две обучающие выборки, аналогичные из примера выше. Один граф станет выдавать пространственное отношение любых двух участков поля зрения по оси X, другой - по оси Y.
Обучали гусей поощрением едой при демонстрации и, соответственно, выборе гусем карточки, на которой правое число больше левого. А тестировали их на полном наборе. Через какое-то время гуси начинали выбирать верные карточки чаще случайного выбора. То есть, демонстрировали понимание, что 5 больше 1 и т.п.
Я смоделировал такой механизм. Причём он получился элементарным.
Понятно, что у нас есть две сущности с неким взаимоотношением. Можем представить каждую карточку уникальной парой чисел: 1-2. Соберём из тестового набора направленный граф, где вершинам соответствует числа, а ребро указывает на правое число в паре.
Поиск ответа для пары чисел [A, B], упорядоченной по возрастанию - это поиск пути в графе из вершины A в вершину B. Если путь найден, то порядок верный. That's all, folks!
Результаты
Набор из 10 элементов/чисел. Полное число комбинаций = 100; число комбинаций (a < b) = 45.
1) Доля обучающей выборки 25%. Среднее число попаданий 72%
2) Доля обучающей выборки 50%. Среднее число попаданий 88%
Подобный результат гуси и демонстрировали.
Далее я поиграл с количеством объектов и размером обучающей выборки. Перейду к самому интересному.
Набор из 1000 элементов/чисел. Полное число комбинаций = 1000000; число комбинаций (a < b) = 499500.
Доля обучающей выборки 10%. Среднее число попаданий 97%
Чем больше элементов в иерархии, тем точнее результат и тем меньше требуется обучающая выборка (в процентном отношении).
На один элемент из этого примера выходит примерно по 50 связей. То есть, связность вершин друг с другом довольно низкая, 50 / 1000 = 0.05. Но этого достаточно, чтобы связями сшить куски чего-то заранее неизвестной природы в некий континуум, пространство и затем находить в нём путь.
Для оптимизации поиска пути я применил ранее описанный алгоритм волны. "Глубина" распространения волны поиска оказалась менее 10 переходов. То есть, волна возбуждения прокатывается по цепочке длиной менее 10 вершин/нейронов, чтобы успеть найти путь, или затухнуть, если путь не найден. Такая короткая цепочка нейронов для поиска ответа среди 1000 элементов хорошо соответствует факту о небольшой длине нейронной цепи от сенсорных нейронов до моторных.
Так как элементы/вершины - это абстракция, можно получить такой же обучающий набор (и результаты) для других применений. Если привязать к текущим координатам направления взгляда бинаризованные векторы его смены (влево/вправо и вверх/вниз) в следующую позицию, то просто подвигав глазами десятки тысяч раз, получим две обучающие выборки, аналогичные из примера выше. Один граф станет выдавать пространственное отношение любых двух участков поля зрения по оси X, другой - по оси Y.
Forwarded from Алексей
Автоматическое разбиение потока слов на слоги частично биоподобным образом
Первичные сенсорные области кодируют пары сигналов: текущий и предыдущий.
* см. ортогональное кодирование сенсорных сигналов
Аналогичным образом разделяем входной поток символов на пересекающиеся пары, и формируем из них поток биграмм.
'пыхтелка'
Входной поток символов:
Собираем статистику по встречаемости каждой биграммы в корпусе текста.
Биграммы можно дополнять триграммами, но из-за более низкой частотности их влияние незначительно.
Первичные сенсорные области кодируют пары сигналов: текущий и предыдущий.
* см. ортогональное кодирование сенсорных сигналов
Аналогичным образом разделяем входной поток символов на пересекающиеся пары, и формируем из них поток биграмм.
'пыхтелка'
Входной поток символов:
[п, ы, х, т, е, л, к, а]Выходной поток биграмм:
[пы, ых, хт, те, ел, лк, ка]Слоги же представляют из себя непересекающиеся последовательности различной длины 2-4.
Собираем статистику по встречаемости каждой биграммы в корпусе текста.
пы 14Каждый символ присутствует в двух соседних биграммах потока. Относим символ к биграмме с большей встречаемостью.
ых 31
хт 3
те 219
ел 236
лк 29
ка 584
п*В результате некоторые биграммы оказываются 'пустыми', на их месте делаем вставку разделителя. После этого сливаем оставшиеся биграммы в выходной поток слогов.
ых
**
т*
ел
**
ка
пых'пых-тел-ка'
тел
ка
Биграммы можно дополнять триграммами, но из-за более низкой частотности их влияние незначительно.
пы 14#syllables
ых 31
хт 3
те 219
ел 236
лк 29
ка 584
пых 1
ыхт 2
хте 1
тел 48
елк 9
лка 8
Forwarded from Алексей
Telegraph
Модель переноса воспоминаний из рабочей памяти в долговременную
Две сети Сеть рабочей памяти и сеть долговременной памяти. Сети связаны друг с другом в одну комплексную сеть. Долговременная память может представлять из себя большую глубокую сеть, обучаемую обратным распространением ошибки. Рабочая память – однослойная…
Forwarded from Data Secrets
Итак, разбор статьи про xLSTM уже можно найти на нашем сайте! В тексте вы найдете:
➡️ Пошаговое объяснение того, как работает ванильная LSTM. Разберетесь, даже если вы ничего не слышали про эту архитектуру до этого.
➡️ Структурированный разбор каждого улучшения, которое предложили ученые в xLSTM.
➡️ Множество схем и примеров.
➡️ Сравнение xLSTM с трансформерами.
➡️ Рассуждение на тему "имеют ли xLSTM шансы стать будущим LLM?"
Сохраняйте и читайте, не пожалеете: https://datasecrets.ru/articles/10
Сохраняйте и читайте, не пожалеете: https://datasecrets.ru/articles/10
Please open Telegram to view this post
VIEW IN TELEGRAM
datasecrets.ru
Погружение в xLSTM – обновленную LSTM, которая может оказаться заменой трансформера | Data Secrets
Исследователи, которые в 1997 году изобрели архитектуру LSTM, спустя 27 лет выпустили «обновление». Разбираемся, как это работает, и почему может стать прорывом для больших языковых моделей.
Forwarded from Sber AI
Чем заменить Chain-of-Thought?
Исследователи из Нью-Йоркского университета рассмотрели в новой статье, могут ли языковые модели использовать в процессе рассуждений вместо известной техники промптинга цепочки повторяющихся одинаковых символов (“...”).
Chain-of-Thought — популярный способ повысить качество сгенерированных текстов (вместо того, чтобы отвечать сразу, модель просят давать комментарии по ходу решения задачи). Считается, что такой подход позволяет приблизить процесс её “мышления” к человеческому.
Что предположили авторы работы?
🤹 В некоторых случаях модели генерируют промежуточные токены между вопросом и окончательным ответом не для того, чтобы рассуждать, а с целью проведения вычислений, которые нужны ей для ответа на вопрос 🤓
🤹 Получается, во время “рассуждений” модели может использоваться и последовательность повторяющихся символов (filling tokens).
А в некоторых задачах такие токены могут оказаться даже предпочтительнее, чем генерация рассуждений, похожих на человеческие. В качестве доказательства этого тезиса приводятся два датасета 3SUM и 2SUM-Transform, содержащие задачи по нахождению трёх и двух чисел, дающих в сумме ноль, соответственно.
Для экспериментов брали модель Llama-34M*. У неё не получилось решить эти задачи без посторонней помощи, но использование filling tokens (в качестве промежуточных, сгенерированных между вопросом и финальным ответом модели) повысило точность до 94% (2SUM-Transform) и 100% (3SUM). Более того, промежуточные токены становились тем важнее, чем выше была сложность заданий.
* продукт экстремистской организации, деятельность которой запрещена на территории РФ
Изображение New York University
Исследователи из Нью-Йоркского университета рассмотрели в новой статье, могут ли языковые модели использовать в процессе рассуждений вместо известной техники промптинга цепочки повторяющихся одинаковых символов (“...”).
Chain-of-Thought — популярный способ повысить качество сгенерированных текстов (вместо того, чтобы отвечать сразу, модель просят давать комментарии по ходу решения задачи). Считается, что такой подход позволяет приблизить процесс её “мышления” к человеческому.
Что предположили авторы работы?
А в некоторых задачах такие токены могут оказаться даже предпочтительнее, чем генерация рассуждений, похожих на человеческие. В качестве доказательства этого тезиса приводятся два датасета 3SUM и 2SUM-Transform, содержащие задачи по нахождению трёх и двух чисел, дающих в сумме ноль, соответственно.
Для экспериментов брали модель Llama-34M*. У неё не получилось решить эти задачи без посторонней помощи, но использование filling tokens (в качестве промежуточных, сгенерированных между вопросом и финальным ответом модели) повысило точность до 94% (2SUM-Transform) и 100% (3SUM). Более того, промежуточные токены становились тем важнее, чем выше была сложность заданий.
* продукт экстремистской организации, деятельность которой запрещена на территории РФ
Изображение New York University
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Sber AI
This media is not supported in your browser
VIEW IN TELEGRAM
Продолжаем изучать пользу, которую приносит нам 3D Gaussian Splatting. Этот метод генерации решил проблемы и длительного рендеринга, и обучения этому моделей 💥
Но есть нюансы☺️
Результат всё же зависит от входной картинки. В тех случаях, когдаснято на тапок изображение размыто или к движениям камеры есть претензии (они слишком резкие или трясущиеся 🤬 ), ту же нечёткость, плохое воссоздание деталей, скачки и потряхивания мы получим и на выходе.
Появилось решение. Нейросеть Deblur-GS из размытого “гуляющего” изображения делает “конфетку”🎂
Стабилизирует видео, а объектам придаёт чёткие границы. Качество картинки значительно улучшается, движения становятся плавнее.
Но есть нюансы
Результат всё же зависит от входной картинки. В тех случаях, когда
Появилось решение. Нейросеть Deblur-GS из размытого “гуляющего” изображения делает “конфетку”
Стабилизирует видео, а объектам придаёт чёткие границы. Качество картинки значительно улучшается, движения становятся плавнее.
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
TKAN: Temporal Kolmogorov-Arnold Networks
https://arxiv.org/abs/2405.07344
https://arxiv.org/abs/2405.07344
Inspired by the Kolmogorov-Arnold Networks (KANs) a promising alternatives to MultiLayer Perceptrons (MLPs), we proposed a new neural networks architecture inspired by KAN and the LSTM, the Temporal Kolomogorov-Arnold Networks (TKANs). TKANs combined the strenght of both networks, it is composed of Recurring Kolmogorov-Arnold Networks (RKANs) Layers embedding memory management.
Full causal self-attention layer in O(NlogN) computation steps and O(logN) time rather than O(N^2) computation steps and O(1) time, with a big caveat, but hope for the future.
https://www.reddit.com/r/MachineLearning/comments/1cri6h6/d_full_causal_selfattention_layer_in_onlogn/
- Автор утверждает, что разработал метод расчета полного causal self-attention слоя за O(N) шагов вычислений и время O(logN), что является значительным улучшением по сравнению с традиционными O(N^2) шагами вычислений.
- Метод включает в себя использование техники параллельного сканирования для вычисления базисных функций ряда Тейлора, которые затем используются для вычисления числителя и знаменателя softmax-активации полного causal self-attention слоя.
- В настоящее время этот метод неэффективен и непрактичен, но автор надеется, что он вдохновит на дальнейшие исследования по поиску более эффективных альтернатив.
https://www.reddit.com/r/MachineLearning/comments/1cri6h6/d_full_causal_selfattention_layer_in_onlogn/
- Автор утверждает, что разработал метод расчета полного causal self-attention слоя за O(N) шагов вычислений и время O(logN), что является значительным улучшением по сравнению с традиционными O(N^2) шагами вычислений.
- Метод включает в себя использование техники параллельного сканирования для вычисления базисных функций ряда Тейлора, которые затем используются для вычисления числителя и знаменателя softmax-активации полного causal self-attention слоя.
- В настоящее время этот метод неэффективен и непрактичен, но автор надеется, что он вдохновит на дальнейшие исследования по поиску более эффективных альтернатив.
Convolutional Kolmogorov-Arnold Network (CKAN)
Convolutional-KANs: This project extends the idea of the innovative architecture of Kolmogorov-Arnold Networks (KAN) to the Convolutional Layers, changing the classic linear transformation of the convolution to learnable non linear activations in each pixel.
https://github.com/AntonioTepsich/Convolutional-KANs
Convolutional-KANs: This project extends the idea of the innovative architecture of Kolmogorov-Arnold Networks (KAN) to the Convolutional Layers, changing the classic linear transformation of the convolution to learnable non linear activations in each pixel.
https://github.com/AntonioTepsich/Convolutional-KANs
Forwarded from Новости нейронаук и нейротехнологий
Нейронауки в Science и Nature. Выпуск 286: не всякий сон влияет на контакты между нейронами
Согласно гипотезе синаптического гомеостаза, синапсы – контакты между нервными клетками – увеличиваются в количестве во время бодрствования и устраняются во время сна. Исследователи из Университетского колледжа Лондона выяснили, что таким эффектом обладает только сон «высокого давления», который случается после длительного бодрствования. Причем величина эффекта «синаптических потерь» зависит от подтипа нейронов. Подробности работы опубликованы в журнале Nature.
Читать дальше:
https://neuronovosti.ru/nejronauki-v-science-i-nature-vypusk-286-ne-vsyakij-son-vliyaet-na-kontakty-mezhdu-nejronami/
Согласно гипотезе синаптического гомеостаза, синапсы – контакты между нервными клетками – увеличиваются в количестве во время бодрствования и устраняются во время сна. Исследователи из Университетского колледжа Лондона выяснили, что таким эффектом обладает только сон «высокого давления», который случается после длительного бодрствования. Причем величина эффекта «синаптических потерь» зависит от подтипа нейронов. Подробности работы опубликованы в журнале Nature.
Читать дальше:
https://neuronovosti.ru/nejronauki-v-science-i-nature-vypusk-286-ne-vsyakij-son-vliyaet-na-kontakty-mezhdu-nejronami/