
Друзья, каналу @R4marketing сегодня исполняется 5 лет, первый небольшой юбилей.
1 ноября 2018 года я сообщил о запуске канала у себя в facebook.
При желании можно поддержать канал по этой ссылке, либо переводом 5 USDT на TrustWallet по этой ссылке.
Спасибо вам!
1 ноября 2018 года я сообщил о запуске канала у себя в facebook.
При желании можно поддержать канал по этой ссылке, либо переводом 5 USDT на TrustWallet по этой ссылке.
Спасибо вам!
{kind=link}
Опубликован 14ый, и завершающий урок курса по разработке пакетов на языке R: Создание мета-пакета
В заключительном уроке курса мы с вами научимся создавать собственные мета пакеты. Мета пакет это не самостоятельный пакет, а просто коллекция объединённых пакетов, одним из наиболее известных мета-пакетов является
Это самый короткий урок данного курса.
Тайм коды:
00:00 Вступление
01:10 Пример создания мета-пакета с помощью пакета
05:47 Аргументы функции
07:12 Заключение
————————————
Сегодня опубликован 14ый, и последний урок курса по разработке пакетов, работа над курсом продлилась ровно 3 месяца, 7 августа был опубликован 1ый урок, и сегодня - 7 ноября, последний.
Надеюсь курс поможет вам в написании своих собственных пакетов, если вы ранее ещё не имели такой практики, а тем кто уже активно пишет свои пакеты использовать наиболее продвинутые и современные техники в их разработке.
В ближайшие дни опубликую курс на bookdown, о чём тут отдельно сообщу.
————————————
Ссылки:
1. Сайт курса
2. Видео на YouTube
#курсы_по_R
В заключительном уроке курса мы с вами научимся создавать собственные мета пакеты. Мета пакет это не самостоятельный пакет, а просто коллекция объединённых пакетов, одним из наиболее известных мета-пакетов является
tidyverse, в ядро которого входят такие пакеты как: dplyr, tidyr, ggplot2, stringr и т.д.Это самый короткий урок данного курса.
Тайм коды:
00:00 Вступление
01:10 Пример создания мета-пакета с помощью пакета
pkgverse05:47 Аргументы функции
pkgverse()07:12 Заключение
————————————
Сегодня опубликован 14ый, и последний урок курса по разработке пакетов, работа над курсом продлилась ровно 3 месяца, 7 августа был опубликован 1ый урок, и сегодня - 7 ноября, последний.
Надеюсь курс поможет вам в написании своих собственных пакетов, если вы ранее ещё не имели такой практики, а тем кто уже активно пишет свои пакеты использовать наиболее продвинутые и современные техники в их разработке.
В ближайшие дни опубликую курс на bookdown, о чём тут отдельно сообщу.
————————————
Ссылки:
1. Сайт курса
2. Видео на YouTube
#курсы_по_R
YouTube
Разработка пакетов на R #14: Создание мета пакета
В заключительном уроке мы с вами научимся создавать собственные мета пакета. Мета пакет это не самостоятельный пакет, а просто коллекция объединённых пакетов, одним из наиболее известных мета-пакетов является tidyverse, в ядро которого входят такие пакеты…
Уес МакКинни присоединился к Posit (ex. RStudio)
Несомненно это пожалуй самая громкая новость в мире R как минимум за этот год. Ниже приведу перевод сообщения из рассылки Posit. в котором они поделились этой новостью.
Мы рады сообщить, что Уэс МакКинни присоединился к Posit!
—————————————
Уэс МакКинни — предприниматель и разработчик ПО с открытым исходным кодом, который за последние 15 лет внес значительный вклад в развитие сообществ науки о данных и аналитики.
Его пакет pandas стал стандартом для анализа и обработки данных Python. Его книга «Python для анализа данных» научила целое поколение ученых, занимающихся данными, как продуктивно работать с новой платформой pandas, NumPy, matplotlib и Jupyter.
С момента создания pandas Уэс неустанно работал над тем, чтобы сделать основные системы, которые мы используем для обработки и анализа данных, масштабируемыми, совместимыми и компонуемыми с помощью таких проектов, как Ibis , Apache Arrow и Feather .
И теперь мы очень рады сотрудничать с Уэсом и внести свой вклад в экосистему PyData. Когда мы сменили название на Posit, нашей целью было объединить усилия для создания отличных инструментов для анализа данных, независимо от языка, и сотрудничество с Уэсом — огромный шаг вперед в реализации этой мечты.
Прочтите сообщение в блоге Уэса, чтобы узнать больше о том, над чем он планирует работать в Posit. Нам не терпится увидеть, что он создаст в ближайшие годы!
—————————————
Пожелаем Уэсу успехов!
#новости_и_релизы_по_R
Несомненно это пожалуй самая громкая новость в мире R как минимум за этот год. Ниже приведу перевод сообщения из рассылки Posit. в котором они поделились этой новостью.
Мы рады сообщить, что Уэс МакКинни присоединился к Posit!
—————————————
Уэс МакКинни — предприниматель и разработчик ПО с открытым исходным кодом, который за последние 15 лет внес значительный вклад в развитие сообществ науки о данных и аналитики.
Его пакет pandas стал стандартом для анализа и обработки данных Python. Его книга «Python для анализа данных» научила целое поколение ученых, занимающихся данными, как продуктивно работать с новой платформой pandas, NumPy, matplotlib и Jupyter.
С момента создания pandas Уэс неустанно работал над тем, чтобы сделать основные системы, которые мы используем для обработки и анализа данных, масштабируемыми, совместимыми и компонуемыми с помощью таких проектов, как Ibis , Apache Arrow и Feather .
И теперь мы очень рады сотрудничать с Уэсом и внести свой вклад в экосистему PyData. Когда мы сменили название на Posit, нашей целью было объединить усилия для создания отличных инструментов для анализа данных, независимо от языка, и сотрудничество с Уэсом — огромный шаг вперед в реализации этой мечты.
Прочтите сообщение в блоге Уэса, чтобы узнать больше о том, над чем он планирует работать в Posit. Нам не терпится увидеть, что он создаст в ближайшие годы!
—————————————
Пожелаем Уэсу успехов!
#новости_и_релизы_по_R
{kind=link}
rlinkedinads - Пакет для работы с Linkedin Advertising API
Ранее никогда не приходилось работать с Linkedin API, но в этом месяце была задача написать скрипт, который бы запрашивал статистику их рекламного кабинета Linkedin, соответственно в ходе её решения появился пакет для работы с Linkedin Advertising API.
На данный момент в пакете реализован следующий функционал:
● Интерфейс авторизации
● Запрос всех объектов рекламного кабинета
● Запрос статистики из рекламного кабинета
Установить пакет можно из CRAN или Github:
Пример кода:
В ближайшее время запишу видео урок по работе с пакетом.
#новости_и_релизы_по_R
Ранее никогда не приходилось работать с Linkedin API, но в этом месяце была задача написать скрипт, который бы запрашивал статистику их рекламного кабинета Linkedin, соответственно в ходе её решения появился пакет для работы с Linkedin Advertising API.
На данный момент в пакете реализован следующий функционал:
● Интерфейс авторизации
● Запрос всех объектов рекламного кабинета
● Запрос статистики из рекламного кабинета
Установить пакет можно из CRAN или Github:
install.packages('rlinkedinads')
pak::pak('selesnow/rlinkedinads')Пример кода:
library(rlinkedinads)
lkd_set_login('ВАШ ЛОГИН')
lkd_set_account_id(ID ВАШЕГО РЕКЛАМНОГО АККАУНТА)
# Иерархия рекламного аккаунта
accounts <- lkd_get_accounts()
user_accounts <- lkd_get_accounts_by_authenticated_user()
account_users <- lkd_get_ad_account_users_by_accounts(account_urn_id = 'urn:li:sponsoredAccount:511009658')
campaign_groups <- lkd_get_campaign_groups()
campaigns <- lkd_get_campaigns()
creatives <- lkd_get_creatives()
# Запрос аналитики
report <- lkd_get_ads_analytics(
pivot = 'CAMPAIGN',
date_from = '2023-01-01,
date_to = '2023-06-30,
time_granularity = 'DAILY',
fields = c(
'pivotValues',
'dateRange',
'clicks',
'impressions',
'dateRange',
'costInUsd',
'oneClickLeads',
'externalWebsiteConversions'
),
facets = list(
accounts = 'urn:li:sponsoredAccount:511009658',
campaigns = "urn:li:sponsoredCampaign:253102116",
campaigns = "urn:li:sponsoredCampaign:229686963"
)
)
В ближайшее время запишу видео урок по работе с пакетом.
#новости_и_релизы_по_R
{kind=link}
Вышел httr2 1.0.0
Команда Хедли работала над вторым поколением
httr2 является преемником httr.Основное его отличие состоит в том, что у него есть явный объект запроса, который можно создать с помощью нескольких вызовов функций. Это делает интерфейс более естественным для работы в пайпах и в целом упрощает жизнь, поскольку вы можете итеративно создавать сложный запрос. httr2 также основан на 10-летнем опыте разработки пакетов, который мы накопили с момента создания httr, поэтому его использование должно быть более удобным. Если вы в настоящее время являетесь пользователем httr, вам не нужно переходить на него, поскольку мы продолжим поддерживать пакет в течение многих лет, но если вы начинаете новый проект, я бы рекомендовал вам попробовать httr2.
От себя добавлю, что с момента выхода
————————————————
Что нового в httr2 1.0.0
В этом выпуске представлены улучшенные инструменты для выполнения нескольких запросов, а также множество исправлений ошибок и незначительных улучшений для OAuth.
Для управления политикой отправки набора запросов в данном релизе добавлены следующие 3 функции:
●
●
●
Небольшой пример кода для работы с набором запросов:
● В функцию
-
-
-
● Так же у пакета теперь появился официальный логотип, который вы видите на изображении к посту.
Ссылки:
- Прочитать о выпуске httr2 1.0.0 можно по ссылке
Полезные материалы по httr2:
- Начало работы с httr2
- Оборачиваем API с помощью httr2
- Видео урок по созданию пакета обёртки над API с помощью httr2
#новости_и_релизы_по_R
Команда Хедли работала над вторым поколением
httr на протяжении последних двух лет, и вчера был официальный релиз стабильной версии httr2.httr2 является преемником httr.Основное его отличие состоит в том, что у него есть явный объект запроса, который можно создать с помощью нескольких вызовов функций. Это делает интерфейс более естественным для работы в пайпах и в целом упрощает жизнь, поскольку вы можете итеративно создавать сложный запрос. httr2 также основан на 10-летнем опыте разработки пакетов, который мы накопили с момента создания httr, поэтому его использование должно быть более удобным. Если вы в настоящее время являетесь пользователем httr, вам не нужно переходить на него, поскольку мы продолжим поддерживать пакет в течение многих лет, но если вы начинаете новый проект, я бы рекомендовал вам попробовать httr2.
От себя добавлю, что с момента выхода
httr2 все свои новые пакеты я уже писал на его основе. ————————————————
Что нового в httr2 1.0.0
В этом выпуске представлены улучшенные инструменты для выполнения нескольких запросов, а также множество исправлений ошибок и незначительных улучшений для OAuth.
Для управления политикой отправки набора запросов в данном релизе добавлены следующие 3 функции:
●
req_perform_sequential() - берет список запросов и выполняет их по одному.●
req_perform_parallel() - берет список запросов и выполняет их параллельно (до 6 одновременно по умолчанию). По смыслу похоже на req_perform_sequential(), но, очевидно, быстрее за счет потенциальной нагрузки на сервер. У него также есть некоторые ограничения: самое главное, он не может обновить токен OAuth с истекшим сроком действия и игнорирует политику обработки ошибок настроенную через`req_retry()` и ограничение скорости отправки запросов через req_throttle().●
req_perform_iterative() - принимает один запрос и функцию обратного вызова для генерации следующего запроса из предыдущего ответа. Это будет продолжаться до тех пор, пока функция обратного вызова не вернется NULL или max_reqs не будут выполнены запросы. Это очень полезно для API с поддержкой пагинации, которые сообщают только URL-адрес следующей страницы.Небольшой пример кода для работы с набором запросов:
# формируем URL для запроса
urls <- paste0("https://swapi.dev/api/people/", 1:10)
# генерируем список объектов запроса
reqs <- lapply(urls, request)
# последовательно отправляем каждый запрос из списка
resps <- req_perform_sequential(reqs)
# функция для парсинга результатов
sw_data <- function(resp) {
tibble::as_tibble(resp_body_json(resp)[1:9])
}
# парсинг результата
resps |> resps_data(sw_data)
● В функцию
req_url_query() добавлен аргумент .multi, который позволяет управлять поведением параметра, если вы передаёте в него набор значений в виде вектора:-
.multi = "comma" - разделение значений через запятую-
.multi = "pipe" - разделение значений через |-
.multi = "explode" - создание одного параметра для каждого значения (например a = c(1, 2) конвертируется в ?a=1&a=2)● Так же у пакета теперь появился официальный логотип, который вы видите на изображении к посту.
Ссылки:
- Прочитать о выпуске httr2 1.0.0 можно по ссылке
Полезные материалы по httr2:
- Начало работы с httr2
- Оборачиваем API с помощью httr2
- Видео урок по созданию пакета обёртки над API с помощью httr2
#новости_и_релизы_по_R
{kind=link}
Опубликовал видео воркшопа по анализу показателя качества ключевых слов в Google Ads с помощью пакета rgoogleads
Воркшоп прошел ещё 14 сентября, но у меня только недавно добрались руки до его записи.
Описание:
Воркшоп по работе с Google Ads API с помощью языка R и пакета rgoogleads. В ходе которого мы с нуля разберёмся как пройти авторизацию, запрашивать отчёты из Google Ads, и проанализируем показатель качества ключевых слов рекламного аккаунта.
Тайм коды:
00:00:00 Приветствие
00:01:12 О спикере
00:03:43 Программа воркшопа
00:04:14 Что такое контекстная реклама и сервис Google Ads
00:06:34 Варианты авторизации в пакете rgoogleads
00:07:24 Авторизация в Google Ads с помощью дефолтных параметров пакета rgoogleads
00:10:00 Создание собственных учётных данных для авторизации
00:21:12 Авторизация в Google Ads с помощью собственных учётных данных
00:23:00 Иерархия аккаунтов в Google Ads API
00:24:53 Ограничения при использовании собственных учётных данных
00:25:54 Автоматизация процесса авторизации с помощью переменных среды
00:26:43 Опции пакета rgoogleads
00:27:34 Запрос отчётов из Google Ads API
00:30:49 GAQL QueryBuilder
00:34:52 Пример запроса отчётов из Google Ads API
00:39:54 Аргументы функции gads_get_report()
00:41:13 Загрузка отчётов из Google Ads API в многопоточном режиме
00:44:34 Запрос объектов рекламного кабинета Google Ads
00:45:49 Что такое показатель качества ключевых слов и как проходит аукцион среди рекламодателей в Google Ads
00:47:47 Что влияет на показатель качества ключевых слов Google Ads
00:48:29 На что влияет показатель качества Google Ads
00:49:16 Пример анализа качества ключевых слов
01:03:36 Ответы на вопросы
Организаторы:
- Дмитрий Серебренников
- Kazakhstan Sociology Lab (сайт, инстаграм, LinkedIn, группа в тг)
Ссылки:
- Видео на YouTube
- Страница с материалами воркшопа
#видео_уроки_по_R
Воркшоп прошел ещё 14 сентября, но у меня только недавно добрались руки до его записи.
Описание:
Воркшоп по работе с Google Ads API с помощью языка R и пакета rgoogleads. В ходе которого мы с нуля разберёмся как пройти авторизацию, запрашивать отчёты из Google Ads, и проанализируем показатель качества ключевых слов рекламного аккаунта.
Тайм коды:
00:00:00 Приветствие
00:01:12 О спикере
00:03:43 Программа воркшопа
00:04:14 Что такое контекстная реклама и сервис Google Ads
00:06:34 Варианты авторизации в пакете rgoogleads
00:07:24 Авторизация в Google Ads с помощью дефолтных параметров пакета rgoogleads
00:10:00 Создание собственных учётных данных для авторизации
00:21:12 Авторизация в Google Ads с помощью собственных учётных данных
00:23:00 Иерархия аккаунтов в Google Ads API
00:24:53 Ограничения при использовании собственных учётных данных
00:25:54 Автоматизация процесса авторизации с помощью переменных среды
00:26:43 Опции пакета rgoogleads
00:27:34 Запрос отчётов из Google Ads API
00:30:49 GAQL QueryBuilder
00:34:52 Пример запроса отчётов из Google Ads API
00:39:54 Аргументы функции gads_get_report()
00:41:13 Загрузка отчётов из Google Ads API в многопоточном режиме
00:44:34 Запрос объектов рекламного кабинета Google Ads
00:45:49 Что такое показатель качества ключевых слов и как проходит аукцион среди рекламодателей в Google Ads
00:47:47 Что влияет на показатель качества ключевых слов Google Ads
00:48:29 На что влияет показатель качества Google Ads
00:49:16 Пример анализа качества ключевых слов
01:03:36 Ответы на вопросы
Организаторы:
- Дмитрий Серебренников
- Kazakhstan Sociology Lab (сайт, инстаграм, LinkedIn, группа в тг)
Ссылки:
- Видео на YouTube
- Страница с материалами воркшопа
#видео_уроки_по_R
YouTube
Воркшоп: Анализ показателя качества ключевых слов в Google Ads с помощью пакета rgoogleads
Воркшоп по работе с Google Ads API с помощью языка R и пакета rgoogleads. В ходе которого мы с нуля разберёмся как пройти авторизацию, запрашивать отчёты из Google Ads, и проанализируем показатель качества ключевых слов рекламного аккаунта.
|===========…
|===========…
Курс "Разработка пакетов на языке R" опубликован на bookdown.org
В начале месяца я упоминал о завершении разработки последнего, 14-го урока курса и о планах опубликовать его на bookdown. Итак, рад сообщить, что курс теперь доступен на указанной платформе.
О курсе:
Что касается содержания курса, он был создан под впечатлением от книги Хедли Викхема и Дженни Брайан "R Packages (2e)". Мой опыт в разработке R-пакетов начался в 2016 году, и, как выяснилось, мои первые шаги были далеко не самыми эффективными. Книга Хедли предоставила современный и эффективный подход к разработке пакетов, что я внедрил в этот курс.
Курс объединяет мой семилетний опыт в создании пакетов с тем, что было представлено Викхемом и Брайан в их книге. У этих авторов есть чему поучиться.
Этот курс будет полезен как тем, кто только начинает свой путь в создании пакетов, так и тем, кто уже обладает опытом, поскольку в нем рассматриваются передовые практики в разработке пакетов. Так, что если вы не пробовали ещё себя в разработке пакета, то самое время попробовать.
Хотя некоторые теоретические главы книги были опущены, вместо них были добавлены уроки по созданию пакетов-обёрток над API с использованием
В целом, я считаю, что курс получился полезным, и надеюсь, что вы также оцените его.
Программа курса:
1. Обзор рабочего процесса разработки пакета
2. Настройка системы и интеграция с GitHub
3. Рекомендации по организации R кода
4. Добавление данных в пакет
5. DESCRIPTION - Метаданные пакета
6. NAMESPACE - Зависимости пакета
7. Разработка юнит-тестов к функциям пакета (пакет testthat)
8. Написание документации к функциям пакета
9. Виньетки и прочая опциональная документация пакета
10. Разработка сайта пакета (пакет pkgdown)
11. Публикация в CRAN
12. Разработка пакета обёртки над API (пакет httr2)
13. Разработка пакета обёртки для Google API (пакет gargle)
14. Как создать коллекцию пакетов
Буду признателен за репосты!
Ссылки:
- Курс на bookdown
- Сайт курса
- Плейлист на YouTube
- Благодарности автору
#курсы_по_R
В начале месяца я упоминал о завершении разработки последнего, 14-го урока курса и о планах опубликовать его на bookdown. Итак, рад сообщить, что курс теперь доступен на указанной платформе.
О курсе:
Что касается содержания курса, он был создан под впечатлением от книги Хедли Викхема и Дженни Брайан "R Packages (2e)". Мой опыт в разработке R-пакетов начался в 2016 году, и, как выяснилось, мои первые шаги были далеко не самыми эффективными. Книга Хедли предоставила современный и эффективный подход к разработке пакетов, что я внедрил в этот курс.
Курс объединяет мой семилетний опыт в создании пакетов с тем, что было представлено Викхемом и Брайан в их книге. У этих авторов есть чему поучиться.
Этот курс будет полезен как тем, кто только начинает свой путь в создании пакетов, так и тем, кто уже обладает опытом, поскольку в нем рассматриваются передовые практики в разработке пакетов. Так, что если вы не пробовали ещё себя в разработке пакета, то самое время попробовать.
Хотя некоторые теоретические главы книги были опущены, вместо них были добавлены уроки по созданию пакетов-обёрток над API с использованием
httr2 и gargle.В целом, я считаю, что курс получился полезным, и надеюсь, что вы также оцените его.
Программа курса:
1. Обзор рабочего процесса разработки пакета
2. Настройка системы и интеграция с GitHub
3. Рекомендации по организации R кода
4. Добавление данных в пакет
5. DESCRIPTION - Метаданные пакета
6. NAMESPACE - Зависимости пакета
7. Разработка юнит-тестов к функциям пакета (пакет testthat)
8. Написание документации к функциям пакета
9. Виньетки и прочая опциональная документация пакета
10. Разработка сайта пакета (пакет pkgdown)
11. Публикация в CRAN
12. Разработка пакета обёртки над API (пакет httr2)
13. Разработка пакета обёртки для Google API (пакет gargle)
14. Как создать коллекцию пакетов
Буду признателен за репосты!
Ссылки:
- Курс на bookdown
- Сайт курса
- Плейлист на YouTube
- Благодарности автору
#курсы_по_R
YouTube
Разработка пакетов на R: Вводное слово
Несколько вводных слов о курсе "Разработка пакетов на R".
|===========================================|
Ссылка на курс: https://selesnow.github.io/r_package_course/
|===========================================|
Поддержать канал:
Вы можете поддержать канал…
|===========================================|
Ссылка на курс: https://selesnow.github.io/r_package_course/
|===========================================|
Поддержать канал:
Вы можете поддержать канал…
Время обновить пакеты rfacebookstat и rlinkedinads
1.
Пакет был переведён на работу с Facebook Marketing API v18.
Пользователям пакета необходимо только установить его новую версию, все скрипты будут работать без каких либо дополнительных изменений.
2.
В
#новости_и_релизы_по_R
1.
rfacebookstat - пакет для запроса статистики из рекламных кабинетов Facebook и InstagramПакет был переведён на работу с Facebook Marketing API v18.
Пользователям пакета необходимо только установить его новую версию, все скрипты будут работать без каких либо дополнительных изменений.
2.
rlinkedinads - пакет для запроса статистики из рекламных кабинетов LinkedonВ
rlinkedinads была исправлена ошибка обновления токена. Кроме обновления никаких дополнительных действий не требуется.#новости_и_релизы_по_R
{kind=link}
Релиз bigrquery 1.5.0
Я довольно плотно работаю с BigQuery, соответственно не редко использую для этого пакет
Что нового:
Основные изменения:
* Из пакета были исключены все устаревшие функции, т.е. те, названия которых начинаются НЕ с префикса
*
* Теперь
Изменение в DBI интерфейсе:
* Наборы данных и таблицы bigquery теперь будут отображаться на панели подключений при использовании
* Добавлена поддержка функций
* В
Так же ряд менее значительных изменений получил и
Более подробно обо всех изменениях можно почитать на GitHub.
#новости_и_релизы_по_R
Я довольно плотно работаю с BigQuery, соответственно не редко использую для этого пакет
bigrquery. Пару дней назад был достаточно важный релиз bigrquery 1.5.0,Что нового:
Основные изменения:
* Из пакета были исключены все устаревшие функции, т.е. те, названия которых начинаются НЕ с префикса
bq_.*
bq_table_download() теперь возвращает в текстовом формате поля, которые в BigQuery хранятся в неизвестном для R типе. Ранее вы получали ошибку при попытке загрузить таблицы с полями которые имели тип BIGNUMERIC или JSON.* Теперь
bigrquery анализирует даты с помощью пакета clock. Это приводит к значительному повышению производительности и гарантирует корректный анализ дат до 1970-01-01.Изменение в DBI интерфейсе:
* Наборы данных и таблицы bigquery теперь будут отображаться на панели подключений при использовании
dbConnect().* Добавлена поддержка функций
dbAppendTable(), dbCreateTable() и dbExecute()* В
dbGetQuery() и dbSendQuery() поддерживают передачу параметров запросов с помощью аргумента params.Так же ряд менее значительных изменений получил и
dbplyr интерфейс, например tbl() теперь работает не только с физическими таблицами, но и с представлениями (View).Более подробно обо всех изменениях можно почитать на GitHub.
#новости_и_релизы_по_R
{kind=link}
Добавляем полезные аннотации к части вызова пакетв в своих скриптах
Принято прописывать команды загрузки пакетов в начале вашего скрипта, обычно это выглядит как-то так:
Это реальный пример загрузки пакетов в одном из моих скриптов. Пакет
1. Annotate package calls in active file
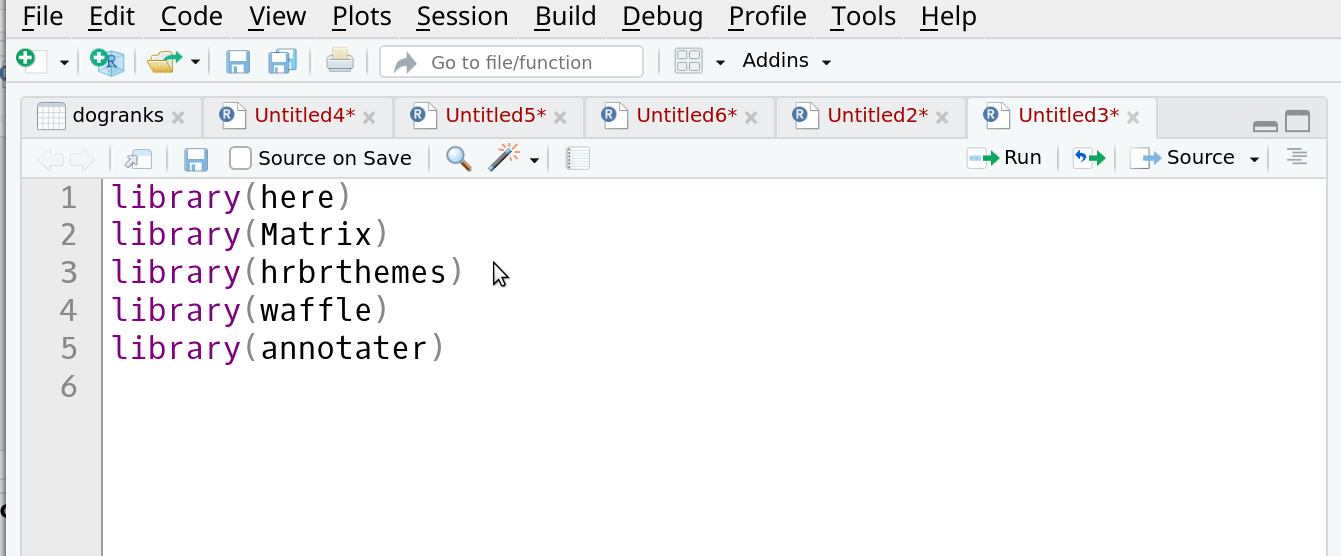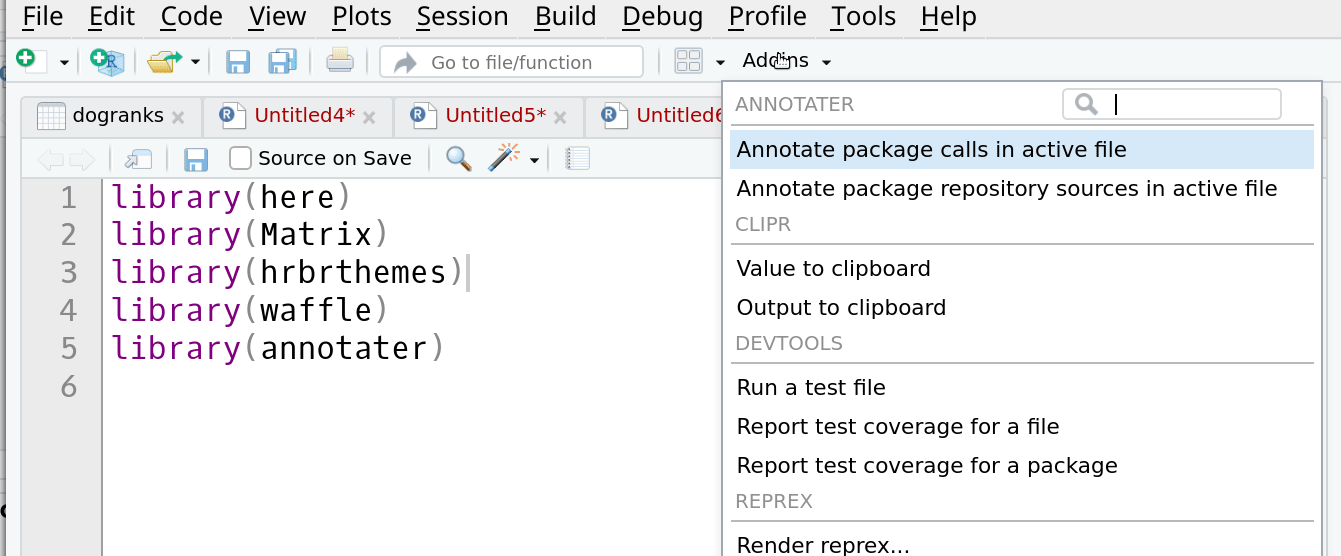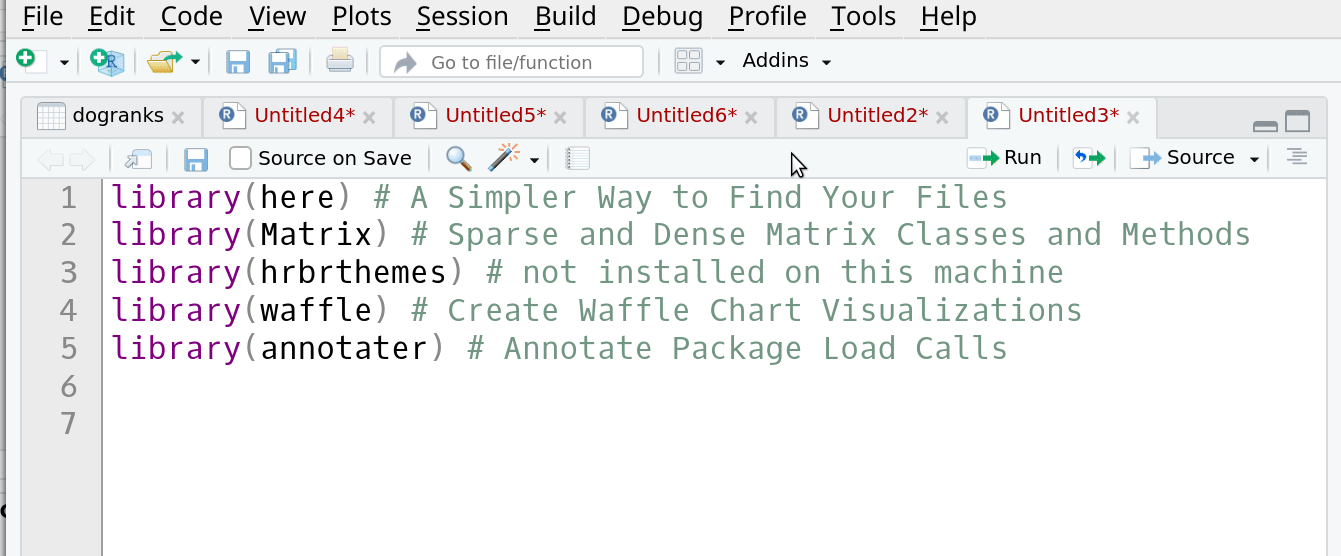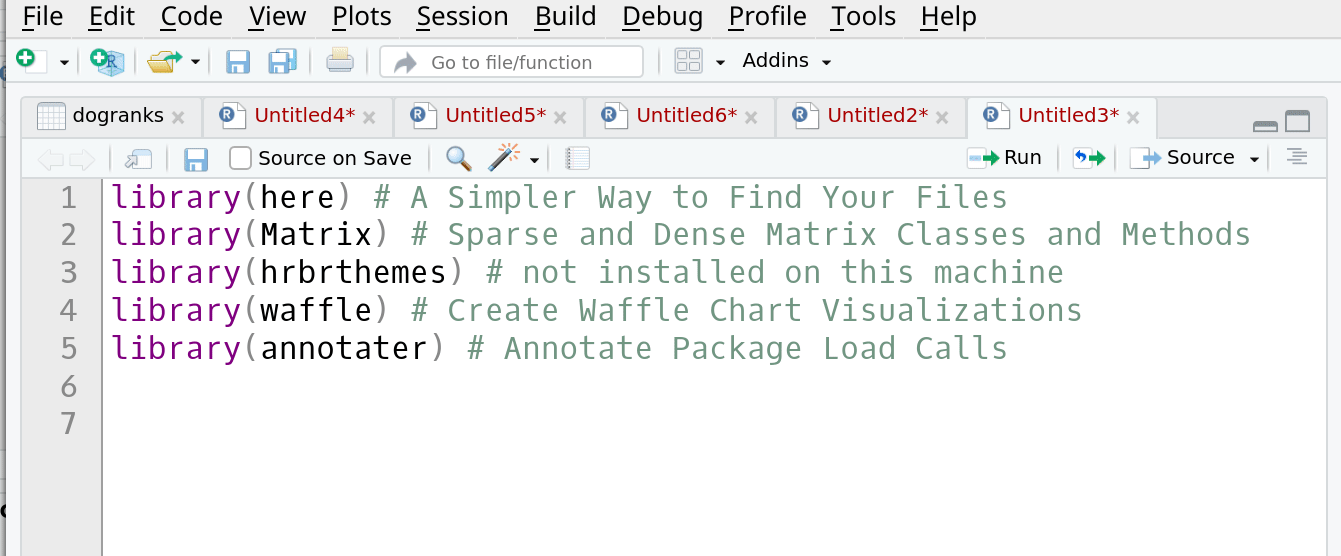
Добавляет тайтлы пакетов к команде их вызовов. т.е. превратит пример выше в следующий:
2. Annotate package repository source in active file
Добавляет информацию о репозитории и версии пакета:
3. Annotate tittles and repository sources in active file
Эта опция добавит одновременно и описание пакета и описание репозитория и его версии
4. Annotate each package's function calls
Пропишет возле вызова пакета список функций. который в текущем скрипте из этого пакета используется.
5. Expand metapackages
Разворачивает вызов метапакета, в отдельные вызовы для каждого пакета, который в него входит.
Например вызов
Функционал довольно полезный, особенно если вы планируете разбирать чужой скрипт, в котором используются неизвестные вам пакеты.
Пример работы на изображении к посту.
Ссылка на GitHub пакета
#заметки_по_R
Принято прописывать команды загрузки пакетов в начале вашего скрипта, обычно это выглядит как-то так:
library(rjira)
library(dplyr)
library(tidyr)
library(snakecase)
library(purrr)
library(stringr)
library(bigrquery)
library(googlesheets4)
library(glue)
Это реальный пример загрузки пакетов в одном из моих скриптов. Пакет
annotater добавляет в RStudio Addon, который позволяет добавить описание вызовам пакетов, на данный момент доступно 5 типов аннотаций:1. Annotate package calls in active file
Добавляет тайтлы пакетов к команде их вызовов. т.е. превратит пример выше в следующий:
library(rjira) # Work with Jira API
library(dplyr) # A Grammar of Data Manipulation
library(tidyr) # Tidy Messy Data
library(snakecase) # Convert Strings into any Case
library(purrr) # Functional Programming Tools
library(stringr) # Simple, Consistent Wrappers for Common String Operations
library(bigrquery) # An Interface to Google's 'BigQuery' 'API'
library(googlesheets4) # Access Google Sheets using the Sheets API V4
library(glue) # Interpreted String Literals
2. Annotate package repository source in active file
Добавляет информацию о репозитории и версии пакета:
library(rjira) # [github::selesnow/rjira] v0.0.0.9000
library(dplyr) # CRAN v1.1.2
library(tidyr) # CRAN v1.2.1
library(snakecase) # CRAN v0.11.0
library(purrr) # CRAN v0.3.4
library(stringr) # CRAN v1.4.1
library(bigrquery) # CRAN v1.5.0
library(googlesheets4) # CRAN v1.0.1
library(glue) # CRAN v1.6.2
3. Annotate tittles and repository sources in active file
Эта опция добавит одновременно и описание пакета и описание репозитория и его версии
4. Annotate each package's function calls
Пропишет возле вызова пакета список функций. который в текущем скрипте из этого пакета используется.
library(rjira) # jr_get_fields jr_issue_search
library(dplyr) # %>% filter mutate left_join group_by row_number ungroup pull select all_of coalesce any_of where rename_with matches across
library(tidyr) # %>% all_of any_of unnest_wider matches hoist
library(snakecase) # to_snake_case
library(purrr) # %>% map_dfc map
library(stringr) # %>% str_remove
library(bigrquery) # bq_auth bq_dataset bq_dataset_query bq_table bq_table_upload
library(googlesheets4) # gs4_auth range_read %>%
library(glue) # glue_sql
5. Expand metapackages
Разворачивает вызов метапакета, в отдельные вызовы для каждого пакета, который в него входит.
Например вызов
library(tidyverse) будет преобразован в:####
library(ggplot2)
library(tibble)
library(tidyr)
library(readr)
library(purrr)
library(dplyr)
library(stringr)
library(forcats)
library(lubridate)
####
Функционал довольно полезный, особенно если вы планируете разбирать чужой скрипт, в котором используются неизвестные вам пакеты.
Пример работы на изображении к посту.
Ссылка на GitHub пакета
annotater.#заметки_по_R
{kind=link}
Как разбить таблицу на части по заданному количеству строк
Иногда вам может потребоваться разбить таблицу на части, либо по количеству строк, либо по значениям какого то поля, в этом вам поможет функция
Для начала построим тестовую таблицу:
Теперь разобьём таблицу на части по значению поля
Так же мы можем разбить таблицу на части по заданному количеству строк:
#заметки_по_R
Иногда вам может потребоваться разбить таблицу на части, либо по количеству строк, либо по значениям какого то поля, в этом вам поможет функция
split() из базового R.Для начала построим тестовую таблицу:
# к-во строк в тестовой таблице
rows_in_table <- 570
# тестовая таблица
df <- data.frame(
row_num = 1:rows_in_table,
numbers = sample(1:9000, size = rows_in_table, replace = T),
letters = sample(letters, size = rows_in_table, replace = T)
)
Теперь разобьём таблицу на части по значению поля
letters:# Разбивка по значению какого либо поля
df_split_by_column <- split(df, df$letters)
$a
# A tibble: 28 x 3
row_num numbers letters
<int> <int> <chr>
1 3 8 a
2 11 2217 a
3 19 1948 a
4 34 338 a
5 54 604 a
6 64 754 a
7 68 3479 a
8 92 3942 a
9 160 7475 a
10 169 2507 a
# i 18 more rows
# i Use `print(n = ...)` to see more rows
$b
# A tibble: 20 x 3
row_num numbers letters
<int> <int> <chr>
1 9 4438 b
2 14 56 b
3 109 6039 b
4 159 1749 b
5 175 8068 b
6 200 7444 b
7 220 1101 b
8 234 2396 b
9 260 3112 b
10 296 7411 b
11 302 4639 b
12 354 7716 b
13 396 4090 b
14 398 1540 b
15 424 6738 b
16 426 728 b
17 441 333 b
18 503 3346 b
19 548 3347 b
20 564 651 b
$c
# A tibble: 17 x 3
row_num numbers letters
<int> <int> <chr>
1 47 1900 c
2 89 8522 c
3 130 6156 c
4 131 246 c
5 148 8591 c
6 151 640 c
7 154 8428 c
8 209 4218 c
9 216 7774 c
10 298 753 c
11 307 8839 c
12 355 5903 c
13 421 5147 c
14 433 2422 c
15 442 3224 c
16 557 4346 c
17 562 8635 c
...
Так же мы можем разбить таблицу на части по заданному количеству строк:
# Разбивка по заданному количеству строк
chunk <- 100 # размер одной части в к-ве строк
n <- nrow(df) # вычисляем к-во строк исходной таблицы
r <- rep(1:ceiling(n/chunk),each=chunk)[1:n] # определяем каждую строку в определённую часть таблицы
df_split_by_100_rows <- split(df,r) # Разбиваем таблицу
$`1`
row_num numbers letters
1 1 1210 h
2 2 5087 y
3 3 81 y
4 4 5459 a
5 5 5665 j
6 6 3735 v
7 7 4309 p
8 8 3858 i
9 9 847 x
10 10 91 e
11 11 3859 k
...
#заметки_по_R
{kind=link}
ggplot 3.5.0.
Привет, друзья! Давно я тут ничего не публиковал, но думаю пора возвращаться из творческого отпуска.
Хедли со своей командой в феврале этого года анонсировали выход новой версии
1. Обновления в темах графиков:
В новой версии
2. Усовершенствованные функции для координатных систем:
Введены улучшения в работе с координатными системами. Новые функции позволяют гибче настраивать масштабирование и пропорции графиков, что особенно полезно при работе с данными, требующими специфического отображения.
3. Новые геометрические объекты:
Добавлены новые геометрические объекты, такие как
4. Оптимизация производительности:
Разработчики внесли изменения, которые улучшают производительность пакета. Графики теперь строятся быстрее, что особенно заметно при работе с большими наборами данных.
Примеры использования
Вот пример использования новой функции geom_density2d_filled для создания двухмерного плотностного графика:
Пробуйте новые функции, делитесь своими впечатлениями и находками в комментариях.
Ссылки:
● Статья "ggplot2 3.5.0" в блоге Tidyverse
#новости_и_релизы_по_R
Привет, друзья! Давно я тут ничего не публиковал, но думаю пора возвращаться из творческого отпуска.
Хедли со своей командой в феврале этого года анонсировали выход новой версии
ggplot2 3.5.0. А в конце апреля вышел к ней патч 3.5.1. Этот релиз включает множество улучшений и новых возможностей, которые делают работу с графиками еще более удобной и мощной. Давайте разберемся, что нового появилось в этой версии.1. Обновления в темах графиков:
В новой версии
ggplot2 добавлены улучшения в настройках тем. Теперь стало проще задавать стили для текста, фона и сетки графиков. Это делает ваши визуализации еще более настраиваемыми и привлекательными.2. Усовершенствованные функции для координатных систем:
Введены улучшения в работе с координатными системами. Новые функции позволяют гибче настраивать масштабирование и пропорции графиков, что особенно полезно при работе с данными, требующими специфического отображения.
3. Новые геометрические объекты:
Добавлены новые геометрические объекты, такие как
geom_density2d_filled, которые позволяют создавать двухмерные плотностные графики с заполненными областями. Это значительно расширяет возможности для анализа данных.4. Оптимизация производительности:
Разработчики внесли изменения, которые улучшают производительность пакета. Графики теперь строятся быстрее, что особенно заметно при работе с большими наборами данных.
Примеры использования
Вот пример использования новой функции geom_density2d_filled для создания двухмерного плотностного графика:
library(ggplot2)
# Создаем примерный набор данных
data <- data.frame(x = rnorm(1000), y = rnorm(1000))
# Строим график с использованием новой функции
ggplot(data, aes(x = x, y = y)) +
geom_density2d_filled() +
theme_minimal() +
labs(title = "2D Density Plot with geom_density2d_filled",
x = "X Axis",
y = "Y Axis")
Пробуйте новые функции, делитесь своими впечатлениями и находками в комментариях.
Ссылки:
● Статья "ggplot2 3.5.0" в блоге Tidyverse
#новости_и_релизы_по_R
{kind=link}
Видео: Личные кейсы использования ChatGPT в рутинных рабочих задачах
Друзья, я выпустил новый видеоурок, где делюсь своим опытом использования ChatGPT 4 в работе аналитика данных. В этом видео вы узнаете о моих успешных и не очень успешных кейсах применения ChatGPT для генерации кода на R и M, а также какие сложности возникли при переводе Python кода в R.
Что вас ждет в видео:
● Обзор пользовательских GPT для аналитиков данных
● Успешные примеры генерации R и M кода для различных задач
● Опыт автоматизации задач с помощью ChatGPT
● Пример неудачной попытки перевода кода с Python на R
Тайм-коды:
00:00 Вступление
01:08 Пользовательские GTP для аналитика данных
07:31 Успешный кейс №1: Генерация R кода для запроса курсов валют
13:33 Успешный кейс №2: Генерация кода на языке M для генерации справочников в Power Query
20:05 Успешный кейс №3: Генерация R кода для отправки HTTP запроса по скриншоту из Postman
24:56 Неуспешный кейс: Перевод Python кода в R
28:33 Заключение
В комментариях делитесь своими кейсами использования в работе ChatGPT.
Ссылки:
● Статья с конспектом к видео уроку
● Видео на YouTube
#видео_уроки_по_R
Друзья, я выпустил новый видеоурок, где делюсь своим опытом использования ChatGPT 4 в работе аналитика данных. В этом видео вы узнаете о моих успешных и не очень успешных кейсах применения ChatGPT для генерации кода на R и M, а также какие сложности возникли при переводе Python кода в R.
Что вас ждет в видео:
● Обзор пользовательских GPT для аналитиков данных
● Успешные примеры генерации R и M кода для различных задач
● Опыт автоматизации задач с помощью ChatGPT
● Пример неудачной попытки перевода кода с Python на R
Тайм-коды:
00:00 Вступление
01:08 Пользовательские GTP для аналитика данных
07:31 Успешный кейс №1: Генерация R кода для запроса курсов валют
13:33 Успешный кейс №2: Генерация кода на языке M для генерации справочников в Power Query
20:05 Успешный кейс №3: Генерация R кода для отправки HTTP запроса по скриншоту из Postman
24:56 Неуспешный кейс: Перевод Python кода в R
28:33 Заключение
В комментариях делитесь своими кейсами использования в работе ChatGPT.
Ссылки:
● Статья с конспектом к видео уроку
● Видео на YouTube
#видео_уроки_по_R
YouTube
ChatGPT для аналитика данных. Успешные и не успешные кейсы использования в работе.
В этом видео я делюсь своим опытом использования ChatGPT 4 в работе аналитика данных. С мая 2024 года ChatGPT 4 стал доступен бесплатно, хоть и с ограниченным доступом, что позволяет нам исследовать его потенциал без дополнительных затрат.
Я расскажу о нескольких…
Я расскажу о нескольких…
Новое видео на YouTube: Как настроить запуск R скриптов по расписанию с помощью GitHub Action
В новом видеоуроке я погружаюсь в мир непрерывной интеграции и развёртывания (CI/CD), а также расскажу, как автоматизировать запуск скриптов с помощью GitHub Actions. Я покажу способ, который позволяет настроить расписание запуска ваших скриптов без необходимости аренды серверов.
Что вы узнаете из видео:
● Основы CI/CD и их роль в автоматизации.
● Настройка рабочего процесса с GitHub Actions.
● Конфигурация YAML файлов для управления рабочими процессами.
● Настройка автоматического запуска скриптов по расписанию.
Тайм-коды:
00:00 Вступление
00:49 CI/CD: Непрерывная интеграция и непрерывное развёртывание
01:45 Что такое GitHub Actions
02:30 Обзор рабочего процесса
03:05 Создание репозитория на GitHub
05:11 Добавляем в репозиторий R-скрипт
08:03 Настройка GitHub Actions
09:47 Конфигурация YAML файла, описывающего рабочий процесс
10:10 Настройка расписания запуска в YAML файле
12:17 Разбираем все команды в YAML файле рабочего процесса
19:01 Создание переменных среды в GitHub репозитории
20:26 Отправляем проект на GitHub
20:52 Запускаем GitHub Action
22:46 Заключение
Если видео окажется полезным и наберёт много откликов то в будущем запишу такое же видео про GitLab.
Ссылки:
● Видео урок
● Статья с конспектом к уроку
#видео_уроки_по_R
В новом видеоуроке я погружаюсь в мир непрерывной интеграции и развёртывания (CI/CD), а также расскажу, как автоматизировать запуск скриптов с помощью GitHub Actions. Я покажу способ, который позволяет настроить расписание запуска ваших скриптов без необходимости аренды серверов.
Что вы узнаете из видео:
● Основы CI/CD и их роль в автоматизации.
● Настройка рабочего процесса с GitHub Actions.
● Конфигурация YAML файлов для управления рабочими процессами.
● Настройка автоматического запуска скриптов по расписанию.
Тайм-коды:
00:00 Вступление
00:49 CI/CD: Непрерывная интеграция и непрерывное развёртывание
01:45 Что такое GitHub Actions
02:30 Обзор рабочего процесса
03:05 Создание репозитория на GitHub
05:11 Добавляем в репозиторий R-скрипт
08:03 Настройка GitHub Actions
09:47 Конфигурация YAML файла, описывающего рабочий процесс
10:10 Настройка расписания запуска в YAML файле
12:17 Разбираем все команды в YAML файле рабочего процесса
19:01 Создание переменных среды в GitHub репозитории
20:26 Отправляем проект на GitHub
20:52 Запускаем GitHub Action
22:46 Заключение
Если видео окажется полезным и наберёт много откликов то в будущем запишу такое же видео про GitLab.
Ссылки:
● Видео урок
● Статья с конспектом к уроку
#видео_уроки_по_R
YouTube
Запуск R скриптов по расписанию с помощью GitHub Actions
В этом видео уроке мы подробно рассмотрим концепцию CI/CD, то есть непрерывной интеграции и непрерывного развёртывания. Мы узнаем, как настроить автоматический запуск ваших скриптов по расписанию с помощью сервиса GitHub Actions, что позволяет обходиться…
Please open Telegram to view this post
VIEW IN TELEGRAM
Преобразовываем речь в текст с помощью R и Google Speech-to-Text API
Привет, друзья! Сегодня я расскажу вам, как создать функцию на R, которая преобразует речь из MP3, Wav или OGG (голосовые сообщения в телеге) файла в текст. Это особенно полезно для расшифровки аудиозаписей, подкастов или голосовых заметок.
Google Speech-to-Text API является условно бесплатным, т.е. бесплатно вы можете в месяц с помощью этого сервиса преобразовать час аудио в текст.
Давайте пройдемся по всему процессу шаг за шагом.
1️⃣ Настройка проекта Google Cloud
Прежде чем начать кодить, нам нужно настроить проект в Google Cloud:
1. Зайдите на console.cloud.google.com и создайте новый проект.
2. Включите API Speech-to-Text в разделе "APIs & Services".
3. Создайте учетные данные (Service Account Key) для доступа к API:
3.1. Перейдите в "APIs & Services" > "Credentials"
3.2. Нажмите "Create Credentials" > "Service Account Key"
3.3. Выберите роль "Project" > "Owner"
3.4. Скачайте JSON файл с ключом
2️⃣ Установка необходимых пакетов R
3️⃣ Код функции
Вот функция, которая делает всю магию:
4️⃣ Использование функции
В результате получим следующее:
Ниже два небольших файла, один в mp3, второй в ogg формате, для тестов.
#заметки_по_R
Привет, друзья! Сегодня я расскажу вам, как создать функцию на R, которая преобразует речь из MP3, Wav или OGG (голосовые сообщения в телеге) файла в текст. Это особенно полезно для расшифровки аудиозаписей, подкастов или голосовых заметок.
Google Speech-to-Text API является условно бесплатным, т.е. бесплатно вы можете в месяц с помощью этого сервиса преобразовать час аудио в текст.
Давайте пройдемся по всему процессу шаг за шагом.
1️⃣ Настройка проекта Google Cloud
Прежде чем начать кодить, нам нужно настроить проект в Google Cloud:
1. Зайдите на console.cloud.google.com и создайте новый проект.
2. Включите API Speech-to-Text в разделе "APIs & Services".
3. Создайте учетные данные (Service Account Key) для доступа к API:
3.1. Перейдите в "APIs & Services" > "Credentials"
3.2. Нажмите "Create Credentials" > "Service Account Key"
3.3. Выберите роль "Project" > "Owner"
3.4. Скачайте JSON файл с ключом
2️⃣ Установка необходимых пакетов R
install.packages(c("tuneR", "seewave", "googledrive", "googleAuthR", "googleLanguageR", "av"))3️⃣ Код функции
Вот функция, которая делает всю магию:
library(tuneR)
library(seewave)
library(googledrive)
library(googleAuthR)
library(googleLanguageR)
library(av)
speech_to_text_from_audio <- function(audio_file_path) {
# Определяем расширение файла
file_ext <- tolower(tools::file_ext(audio_file_path))
# Создаем временный WAV файл
temp_wav_file <- tempfile(fileext = ".wav")
# Обработка в зависимости от типа файла
if (file_ext == "mp3") {
audio <- readMP3(audio_file_path)
} else if (file_ext == "wav") {
audio <- readWave(audio_file_path)
} else if (file_ext == "ogg") {
# Конвертируем OGG в WAV
av_audio_convert(audio_file_path, temp_wav_file)
audio <- readWave(temp_wav_file)
} else {
stop("Неподдерживаемый формат файла. Поддерживаются только MP3, WAV и OGG.")
}
# Если аудио стерео, конвертируем в моно
if (audio@stereo) {
audio <- mono(audio, "both")
}
# Изменяем частоту дискретизации на 16000 Гц, только если текущая частота отличается
if (audio@samp.rate != 16000) {
audio_resampled <- resamp(audio, g = 16000, output = "Wave")
} else {
audio_resampled <- audio
}
# Записываем обработанное аудио во временный WAV файл
writeWave(audio_resampled, temp_wav_file)
# Выполняем распознавание речи
result <- tryCatch({
gl_speech(temp_wav_file,
languageCode = "ru-RU",
sampleRateHertz = 16000)$transcript
}, error = function(e) {
return(paste("Ошибка при распознавании речи:", e$message))
})
# Удаляем временный WAV файл
file.remove(temp_wav_file)
# Возвращаем результат
return(result$transcript)
}
4️⃣ Использование функции
# Пример использования:
# Не забудьте аутентифицироваться перед использованием функции
gl_auth("path/to/your/google_cloud_credentials.json")
# Теперь вы можете использовать функцию так:
mp3_file <- "path/to/your/voice.mp3"
ogg_file <- "path/to/your/voice.ogg"
transcript_mp3 <- speech_to_text_from_audio(mp3_file)
transcript_ogg <- speech_to_text_from_audio(ogg_file)
В результате получим следующее:
> transcript_mp3
[1] "небольшая текстовая начитка для преобразования речи в текст с помощью языка R"
Ниже два небольших файла, один в mp3, второй в ogg формате, для тестов.
#заметки_по_R
{kind=link}
Обновления в книге по созданию Telegram-ботов!
Привет, друзья! Рад сообщить вам о свежих обновлениях в моей книге. Вот что нового:
● Новая обложка: Книга обзавелась новым дизайном.
● Глава 1: В раздел [Создаём бота, и отправляем с его помощью сообщения в Telegram] добавлен новый раздел [Настраиваем запуск расписания отправки сообщения с помощью GitHub Actions]. Теперь вы узнаете, как автоматизировать отправку сообщений с помощью мощных инструментов CI/CD.
● Глава 2: В раздел [Добавляем боту поддержку команд и фильтры сообщений, класс Updater] добавлен новый раздел [Обработка голосовых сообщений. Переводим голосовое сообщение в текст]. Мы рассмотрим, как преобразовать голосовые сообщения в текст и приведём пример бота, выполняющего эту задачу.
● Глава 2: Также добавлен новый раздел [Бот для сбора статистики из Telegram чатов]. Вы научитесь создавать бота, который собирает и анализирует статистику из чатов, что может быть полезно для анализа активности и взаимодействия.
● Предисловие и заключение: К книге добавлены новые предисловие и заключение, чтобы дать вам лучшее представление о содержании и итогах работы.
● Обновления в каждой главе: Предисловия и заключения в каждой главе переписаны для лучшего понимания материала и плавного перехода между темами.
В данный момент я работаю над новой главой книги, и буду рад поделиться с вами новыми подробностями, как только они будут готовы.
#онлайн_книги_по_R
Привет, друзья! Рад сообщить вам о свежих обновлениях в моей книге. Вот что нового:
● Новая обложка: Книга обзавелась новым дизайном.
● Глава 1: В раздел [Создаём бота, и отправляем с его помощью сообщения в Telegram] добавлен новый раздел [Настраиваем запуск расписания отправки сообщения с помощью GitHub Actions]. Теперь вы узнаете, как автоматизировать отправку сообщений с помощью мощных инструментов CI/CD.
● Глава 2: В раздел [Добавляем боту поддержку команд и фильтры сообщений, класс Updater] добавлен новый раздел [Обработка голосовых сообщений. Переводим голосовое сообщение в текст]. Мы рассмотрим, как преобразовать голосовые сообщения в текст и приведём пример бота, выполняющего эту задачу.
● Глава 2: Также добавлен новый раздел [Бот для сбора статистики из Telegram чатов]. Вы научитесь создавать бота, который собирает и анализирует статистику из чатов, что может быть полезно для анализа активности и взаимодействия.
● Предисловие и заключение: К книге добавлены новые предисловие и заключение, чтобы дать вам лучшее представление о содержании и итогах работы.
● Обновления в каждой главе: Предисловия и заключения в каждой главе переписаны для лучшего понимания материала и плавного перехода между темами.
В данный момент я работаю над новой главой книги, и буду рад поделиться с вами новыми подробностями, как только они будут готовы.
#онлайн_книги_по_R
{kind=link}
Как настроить запуск R скриптов по расписанию в Google Cloud Run
Продолжаем изучать тему удалённой автоматизации запуска ваших скриптов. В этом видео мы погружаемся в мир Google Cloud Run и разбираемся с тем, как автоматизировать запуск R скриптов по расписанию. Мы подробно разберём каждый шаг — от настройки облачной платформы до создания Docker образа и его публикации. Итог — условно бесплатная автоматизированная система для выполнения скриптов без постоянного вмешательства.
Что вы узнаете из видео:
● Какой софт понадобится для настройки и запуска скриптов.
● Что такое Google Cloud Run и как он поможет автоматизировать задачи.
● Как настроить проект в Google Cloud для работы с R скриптами.
● Как создать Docker образ и развернуть его в облаке.
● Как настроить регулярный запуск скрипта с помощью триггеров.
Тайм-коды:
00:00 Введение
00:32 Какой софт нам понадобится
01:01 Что такое Google Cloud Run
02:25 Обзор рабочего процесса
03:26 Создание и настройка проекта в Google Cloud
05:36 Обзор R скрипта, который мы будет запускать по расписанию
07:07 Создание Dockerfile
09:54 Локальная сборка Docker образа и запуск контейнера
11:51 Инициализация проекта Google Cloud с Google Cloud SDK Shell
13:43 Отправка Docker образа в Google Container Registry
14:33 Создание Job в Google Cloud Run
16:07 Создание триггера для запуска скрипта по расписанию
18:31 Заключение
Полезные ссылки, которые я упоминаю в видео:
● Как создать Telegram бота и получить токен
● Как упаковать Telegram бота в Docker
● Курс по разработке Telegram ботов на R
Не забывайте подписываться на YouTube канал!
#видео_уроки_по_R
Продолжаем изучать тему удалённой автоматизации запуска ваших скриптов. В этом видео мы погружаемся в мир Google Cloud Run и разбираемся с тем, как автоматизировать запуск R скриптов по расписанию. Мы подробно разберём каждый шаг — от настройки облачной платформы до создания Docker образа и его публикации. Итог — условно бесплатная автоматизированная система для выполнения скриптов без постоянного вмешательства.
Что вы узнаете из видео:
● Какой софт понадобится для настройки и запуска скриптов.
● Что такое Google Cloud Run и как он поможет автоматизировать задачи.
● Как настроить проект в Google Cloud для работы с R скриптами.
● Как создать Docker образ и развернуть его в облаке.
● Как настроить регулярный запуск скрипта с помощью триггеров.
Тайм-коды:
00:00 Введение
00:32 Какой софт нам понадобится
01:01 Что такое Google Cloud Run
02:25 Обзор рабочего процесса
03:26 Создание и настройка проекта в Google Cloud
05:36 Обзор R скрипта, который мы будет запускать по расписанию
07:07 Создание Dockerfile
09:54 Локальная сборка Docker образа и запуск контейнера
11:51 Инициализация проекта Google Cloud с Google Cloud SDK Shell
13:43 Отправка Docker образа в Google Container Registry
14:33 Создание Job в Google Cloud Run
16:07 Создание триггера для запуска скрипта по расписанию
18:31 Заключение
Полезные ссылки, которые я упоминаю в видео:
● Как создать Telegram бота и получить токен
● Как упаковать Telegram бота в Docker
● Курс по разработке Telegram ботов на R
Не забывайте подписываться на YouTube канал!
#видео_уроки_по_R
YouTube
Как настроить запуск R скриптов по расписанию с помощью Google Cloude Run Job
В этом видео мы погружаемся в мир Google Cloud Run и покажем, как автоматизировать запуск ваших R скриптов по расписанию. Мы подробно разберём каждый шаг процесса, от настройки облачной платформы до создания Docker образа и его публикации. В результате вы…
Новый урок на YouTube: Развёртывание Telegram-бота в Google Cloud Run!
Привет, друзья!
Не так давно я рассказывал о том, что работаю над новой главой книги по разработке telegram ботов на R. Так вот, мы на финишной прямой нашего пути по созданию Telegram-ботов, и я рад представить вам новый видеоурок, в котором мы освоим важный шаг — развертывание бота в облаке с помощью Google Cloud Run!
В этом видео вы узнаете:
● Что такое Google Cloud Run и как он поможет вашему боту
● Как настроить и развернуть бота в облаке
● Основы технологии Webhook и Docker
● Пошаговое руководство по созданию, сборке и запуску Docker образа
Тайм-коды:
00:00 Вступление
00:37 Какой софт нам потребуется
01:25 Что такое Google Cloud Run
02:45 Обзор рабочего процесса
04:30 Код бота
05:20 Технология Webhook
10:44 Обзор Dockerfile
14:33 Локальная сборка Docker образа
17:35 Настройка проекта в Google Cloud
19:45 Инициализация Google Cloud SDK
22:10 Тегирование и пушинг Docker образа
23:04 Первый запуск бота
24:14 Корректировка WEBHOOK_URL
25:33 Пересборка и пушинг Docker образа
27:03 Развёртывание в Google Cloud Run
27:14 Проверка бота
28:10 Заключение
Ссылки:
● Видео урок
#видео_уроки_по_R
Привет, друзья!
Не так давно я рассказывал о том, что работаю над новой главой книги по разработке telegram ботов на R. Так вот, мы на финишной прямой нашего пути по созданию Telegram-ботов, и я рад представить вам новый видеоурок, в котором мы освоим важный шаг — развертывание бота в облаке с помощью Google Cloud Run!
В этом видео вы узнаете:
● Что такое Google Cloud Run и как он поможет вашему боту
● Как настроить и развернуть бота в облаке
● Основы технологии Webhook и Docker
● Пошаговое руководство по созданию, сборке и запуску Docker образа
Тайм-коды:
00:00 Вступление
00:37 Какой софт нам потребуется
01:25 Что такое Google Cloud Run
02:45 Обзор рабочего процесса
04:30 Код бота
05:20 Технология Webhook
10:44 Обзор Dockerfile
14:33 Локальная сборка Docker образа
17:35 Настройка проекта в Google Cloud
19:45 Инициализация Google Cloud SDK
22:10 Тегирование и пушинг Docker образа
23:04 Первый запуск бота
24:14 Корректировка WEBHOOK_URL
25:33 Пересборка и пушинг Docker образа
27:03 Развёртывание в Google Cloud Run
27:14 Проверка бота
28:10 Заключение
Ссылки:
● Видео урок
#видео_уроки_по_R
YouTube
Разворачиваем Telegram бота в Google Cloud Run
В этом видео мы завершаем наш путь в создании Telegram бота и переходим к важному этапу – публикации и запуску бота в облаке! Сегодня мы будем использовать мощный инструмент Google Cloud Run, чтобы обеспечить бесперебойную работу нашего бота на облачной платформе.…