
Forwarded from Елена Александровна
This media is not supported in your browser
VIEW IN TELEGRAM
Рассказ от ИИ
Запрос - Девушка потерялась в лесу, её родителям удалось найти лишь дряхлую, страшную куклу на месте исчезновения. Вскоре они узнают, что кукла и есть их дочь. И она оживает.
Ответ - Звучит так, как будто вы описываете сверхъестественное или волшебное событие, когда девочка, заблудившаяся в лесу, превращается в куклу. Если родителям девочки удастся найти куклу и забрать ее домой, их может ждать сюрприз, когда кукла оживет и покажет, что это их дочь. Это может быть очень неприятным и запутанным опытом для родителей, поскольку у них, вероятно, будет много вопросов о том, что случилось с их дочерью и как она стала куклой. Они также могут испытывать чувство вины или ответственности за то, что не смогли защитить свою дочь и не дать ей заблудиться в лесу. Возможно, превращение девочки в куклу и последующее возвращение в человеческую форму может иметь долгосрочные последствия для нее и ее семьи, и им может потребоваться помощь, чтобы справиться с тем, что произошло, и понять, что произошло.
Запрос - Девушка потерялась в лесу, её родителям удалось найти лишь дряхлую, страшную куклу на месте исчезновения. Вскоре они узнают, что кукла и есть их дочь. И она оживает.
Ответ - Звучит так, как будто вы описываете сверхъестественное или волшебное событие, когда девочка, заблудившаяся в лесу, превращается в куклу. Если родителям девочки удастся найти куклу и забрать ее домой, их может ждать сюрприз, когда кукла оживет и покажет, что это их дочь. Это может быть очень неприятным и запутанным опытом для родителей, поскольку у них, вероятно, будет много вопросов о том, что случилось с их дочерью и как она стала куклой. Они также могут испытывать чувство вины или ответственности за то, что не смогли защитить свою дочь и не дать ей заблудиться в лесу. Возможно, превращение девочки в куклу и последующее возвращение в человеческую форму может иметь долгосрочные последствия для нее и ее семьи, и им может потребоваться помощь, чтобы справиться с тем, что произошло, и понять, что произошло.
👍2
Поздравляю со светлым праздником — Рождеством Христовым!
Хочу пожелать крепкого здоровья, семейного благополучия, мира и тепла.
Желаю, чтобы рядом всегда были верные друзья, родные были здоровы и счастливы.
Пусть в вашем доме царит гармония, уют и благополучие.
Пусть Всевышний оберегает от несчастья и дарует мир и покой.
Научитесь видеть красоту в мелочах — тогда жизнь заиграет новыми красками.
Пусть в жизни будут только светлые, радужные полосы.
Хочу пожелать крепкого здоровья, семейного благополучия, мира и тепла.
Желаю, чтобы рядом всегда были верные друзья, родные были здоровы и счастливы.
Пусть в вашем доме царит гармония, уют и благополучие.
Пусть Всевышний оберегает от несчастья и дарует мир и покой.
Научитесь видеть красоту в мелочах — тогда жизнь заиграет новыми красками.
Пусть в жизни будут только светлые, радужные полосы.
👍3👏2🎄1
‼️ Создана нейросеть на базе Stable Diffusion, которая генерирует музыку по текстовому описанию ‼️
👉🏼 Нейросеть Stable Diffusion известна многим. Она позволяет генерировать изображения по текстовому описанию. Но, как оказалось, с её помощью можно также создавать и музыку.
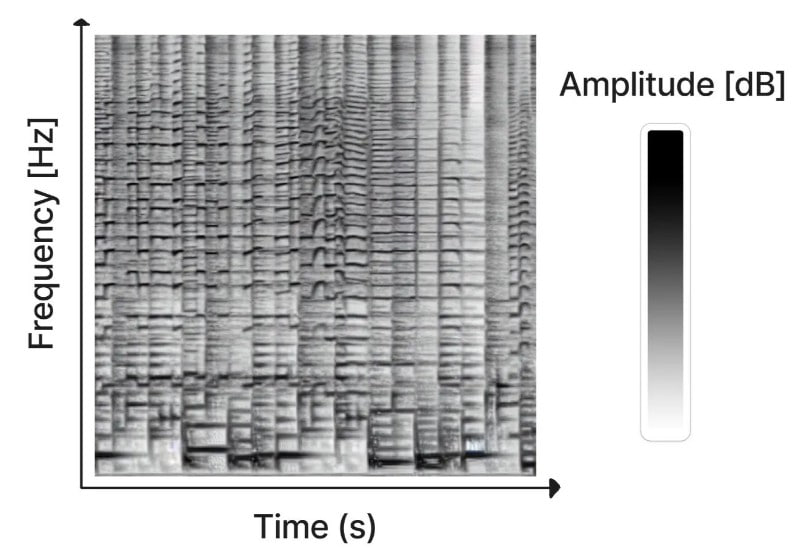
🔷 Суть в том, что система может создавать аудиоспектрограммы - визуальные изображения звуковых частот в треке. После этого нужно лишь «воспроизвести» полученный звук.
🔷 В спектрограмме (или сонограмме) на оси представлен порядок воспроизведения частот слева направо.
🔷 По оси Y размещаются данные о частотах звука, а цвет пикселей задаёт амплитуду звука в каждой момент времени.
🔷 Нейросеть обучили на сонограммах, которые описывают музыкальные жанры или звуки.
🔷 В результате получилась Riffusion - нейросеть, способная генерировать звук из изображения, которое создаётся по текстовому описанию. Для вывода именно аудиодорожки используется Torchaudio.
🔷 При этом разработчики смогли заставить нейросеть генерировать такие аудиоклипы, которые могли бы плавно «перетекать» друг в друга. То есть, темп музыки не меняется резко.
👉🏼 Нейросеть Stable Diffusion известна многим. Она позволяет генерировать изображения по текстовому описанию. Но, как оказалось, с её помощью можно также создавать и музыку.
🔷 Суть в том, что система может создавать аудиоспектрограммы - визуальные изображения звуковых частот в треке. После этого нужно лишь «воспроизвести» полученный звук.
🔷 В спектрограмме (или сонограмме) на оси представлен порядок воспроизведения частот слева направо.
🔷 По оси Y размещаются данные о частотах звука, а цвет пикселей задаёт амплитуду звука в каждой момент времени.
🔷 Нейросеть обучили на сонограммах, которые описывают музыкальные жанры или звуки.
🔷 В результате получилась Riffusion - нейросеть, способная генерировать звук из изображения, которое создаётся по текстовому описанию. Для вывода именно аудиодорожки используется Torchaudio.
🔷 При этом разработчики смогли заставить нейросеть генерировать такие аудиоклипы, которые могли бы плавно «перетекать» друг в друга. То есть, темп музыки не меняется резко.
{kind=link}
👍6
Как работает Stable Diffusion: объяснение в картинках
Генерация изображений при помощи ИИ — одна из самых новых возможностей искусственного интеллекта, поражающая людей (в том числе и меня).
Способность создания потрясающих изображений на основании текстовых описаний похожа на магию; компьютер стал ближе к тому, как творит искусство человек.
Выпуск Stable Diffusion стал важной вехой в этом развитии, поскольку высокопроизводительная модель оказалась доступной широкойпублике (производительная с точки зрения качества изображения, скорости и относительно низких требований к ресурсам и памяти).
Поэкспериментировав в генерацией изображений, вы можете задаться вопросом, как же она работает.
Перейдя по сыслке ниже вы можете полностью ознакомиться с pdf пособием написанным на основе статей, как функционирует Stable Diffusion объяснение в картинках.
Генерация изображений при помощи ИИ — одна из самых новых возможностей искусственного интеллекта, поражающая людей (в том числе и меня).
Способность создания потрясающих изображений на основании текстовых описаний похожа на магию; компьютер стал ближе к тому, как творит искусство человек.
Выпуск Stable Diffusion стал важной вехой в этом развитии, поскольку высокопроизводительная модель оказалась доступной широкойпублике (производительная с точки зрения качества изображения, скорости и относительно низких требований к ресурсам и памяти).
Поэкспериментировав в генерацией изображений, вы можете задаться вопросом, как же она работает.
Перейдя по сыслке ниже вы можете полностью ознакомиться с pdf пособием написанным на основе статей, как функционирует Stable Diffusion объяснение в картинках.
👍3
Прикольная серия картинок от нейросети на тему «Кот алкоголик — горе в семье».
👍4😁1
Алгоритм глубокого обучения может слышать алкоголь в голосе
Нейросети научились не только аватарки делать, но и уровень опьянения показывать.
Исследователи из университета La Trobe в Австралии разработали новую технологию искусственного интеллекта, которая позволяет мгновенно определить степень алкогольного опьянения по … голосу!
Алгоритм ADLAIA (Audio-based Deep Learning Algorithm to Identify Alcohol Inebriation) разработали и протестировали с использованием 12 360 записей голосов людей с разной степенью опьянения. А работает ADLAIA как обычное приложение на смартфоне.
Результаты поражают: алгоритм с 70% вероятностью определяет даже 0,5 промилле, что приравнивается к примерно 100 гр крепкого алкоголя.
Резюме: Новая технология искусственного интеллекта может мгновенно определять, превышает ли человек допустимую норму алкоголя, анализируя 12-секундный фрагмент его голоса.
Нейросети научились не только аватарки делать, но и уровень опьянения показывать.
Исследователи из университета La Trobe в Австралии разработали новую технологию искусственного интеллекта, которая позволяет мгновенно определить степень алкогольного опьянения по … голосу!
Алгоритм ADLAIA (Audio-based Deep Learning Algorithm to Identify Alcohol Inebriation) разработали и протестировали с использованием 12 360 записей голосов людей с разной степенью опьянения. А работает ADLAIA как обычное приложение на смартфоне.
Результаты поражают: алгоритм с 70% вероятностью определяет даже 0,5 промилле, что приравнивается к примерно 100 гр крепкого алкоголя.
Резюме: Новая технология искусственного интеллекта может мгновенно определять, превышает ли человек допустимую норму алкоголя, анализируя 12-секундный фрагмент его голоса.
👍3😱1
Нейросеть превратила песни «Короля и Шута» в фэнтези-вселенную.
👍7🔥4