
PlenOctrees For Real-time Rendering of Neural Radiance Fields
And yet another speed-up of NERF. Exactly the same idea as in FastNeRF and NEX (predict spherical harmonics coefficients k) - incredible! It's the first time I see so many concurrent papers sharig the same idea. But this one has code at least, which makes it the best!
📝 Paper arxiv.org/abs/2103.14024
🌐Project page alexyu.net/plenoctrees/
🛠Code github.com/sxyu/volrend
@Machine_learn
And yet another speed-up of NERF. Exactly the same idea as in FastNeRF and NEX (predict spherical harmonics coefficients k) - incredible! It's the first time I see so many concurrent papers sharig the same idea. But this one has code at least, which makes it the best!
📝 Paper arxiv.org/abs/2103.14024
🌐Project page alexyu.net/plenoctrees/
🛠Code github.com/sxyu/volrend
@Machine_learn
EfficientNetV2: Smaller Models and Faster Training
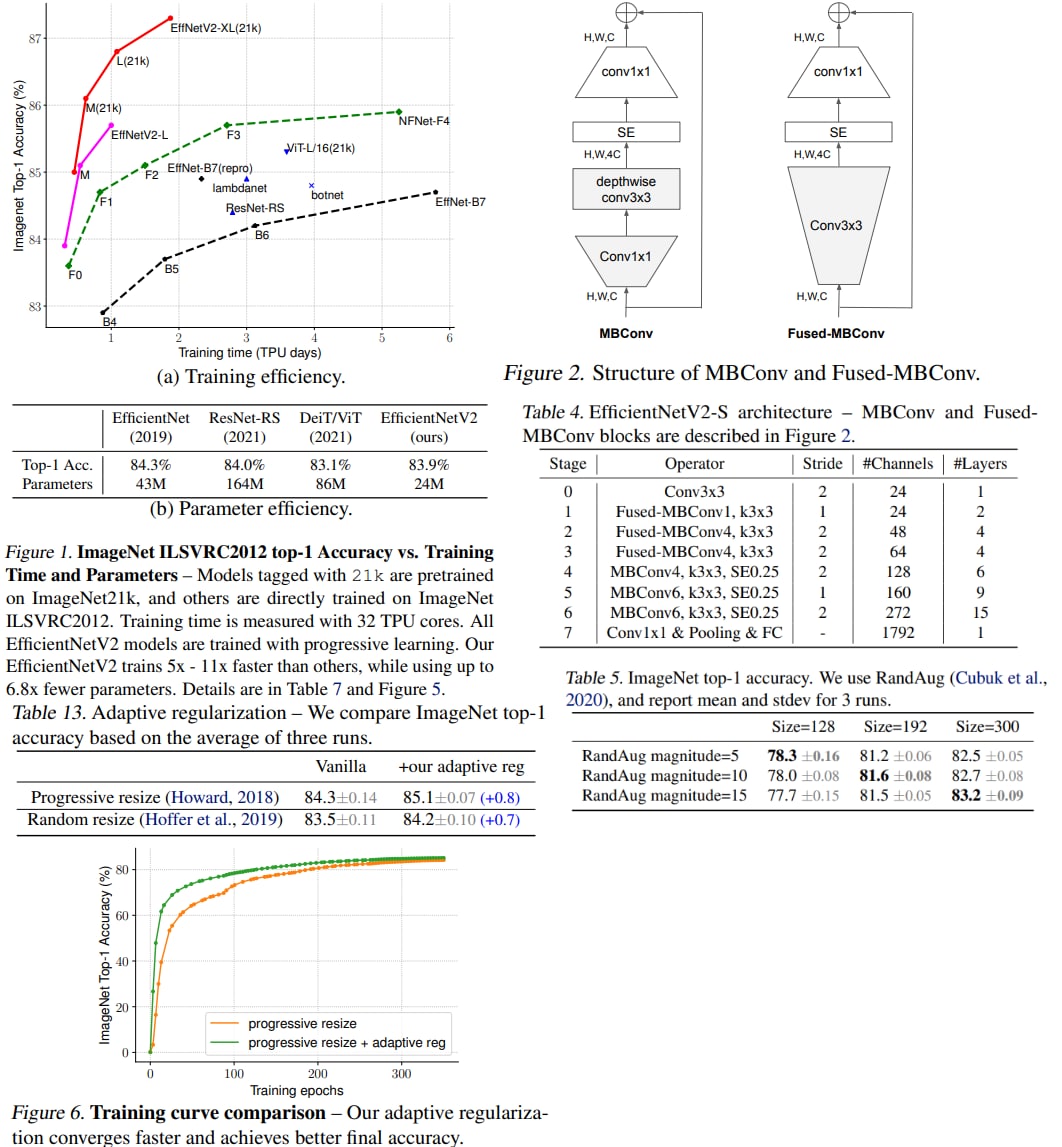
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
@Machine_learn
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
@Machine_learn
{kind=link}
500 + 𝗔𝗿𝘁𝗶𝗳𝗶𝗰𝗶𝗮𝗹 𝗜𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 𝗣𝗿𝗼𝗷𝗲𝗰𝘁 𝗟𝗶𝘀𝘁 𝘄𝗶𝘁𝗵 𝗰𝗼𝗱𝗲
500 AI Machine learning Deep learning Computer vision NLP Projects with code
This list is continuously updated. - You can take pull request and contribute.
https://github.com/ashishpatel26/500-AI-Machine-learning-Deep-learning-Computer-vision-NLP-Projects-with-code
@Machine_learn
500 AI Machine learning Deep learning Computer vision NLP Projects with code
This list is continuously updated. - You can take pull request and contribute.
https://github.com/ashishpatel26/500-AI-Machine-learning-Deep-learning-Computer-vision-NLP-Projects-with-code
@Machine_learn
GitHub
GitHub - ashishpatel26/500-AI-Machine-learning-Deep-learning-Computer-vision-NLP-Projects-with-code: 500 AI Machine learning Deep…
500 AI Machine learning Deep learning Computer vision NLP Projects with code - ashishpatel26/500-AI-Machine-learning-Deep-learning-Computer-vision-NLP-Projects-with-code
Complete Python Bootcamp 2021.pdf
1.6 MB
Complete Python Bootcamp 2021.pdf
@Machine_learn
@Machine_learn
Fashion Meets Computer Vision A Survey.pdf
3.9 MB
Fashion Meets Computer Vision: A Survey @Machine_learn
🧠 Lite-HRNet: A Lightweight High-Resolution Network
Github: https://github.com/HRNet/Lite-HRNet
Paper: https://arxiv.org/abs/2104.06403
@Machine_learn
Github: https://github.com/HRNet/Lite-HRNet
Paper: https://arxiv.org/abs/2104.06403
@Machine_learn
GitHub
GitHub - HRNet/Lite-HRNet: This is an official pytorch implementation of Lite-HRNet: A Lightweight High-Resolution Network.
This is an official pytorch implementation of Lite-HRNet: A Lightweight High-Resolution Network. - GitHub - HRNet/Lite-HRNet: This is an official pytorch implementation of Lite-HRNet: A Lightweigh...
Simple multi-dataset detection
Github: https://github.com/xingyizhou/UniDet
Paper: https://arxiv.org/abs/2102.13086v1
@Machine_learn
Github: https://github.com/xingyizhou/UniDet
Paper: https://arxiv.org/abs/2102.13086v1
@Machine_learn
Monster Mash: A Sketch-Based Tool for Casual 3D Modeling and Animation
http://ai.googleblog.com/2021/04/monster-mash-sketch-based-tool-for.html
@Machine_learn
http://ai.googleblog.com/2021/04/monster-mash-sketch-based-tool-for.html
@Machine_learn
research.google
Monster Mash: A Sketch-Based Tool for Casual 3D Modeling and Animation
Posted by Cassidy Curtis, Visual Designer and David Salesin, Principal Scientist, Google Research 3D computer animation is a time-consuming and hig...
Flexible, Scalable, Differentiable Simulation of Recommender Systems with RecSim NG
http://ai.googleblog.com/2021/04/flexible-scalable-differentiable.html
@Machine_learn
http://ai.googleblog.com/2021/04/flexible-scalable-differentiable.html
@Machine_learn
research.google
Flexible, Scalable, Differentiable Simulation of Recommender Systems with RecSim
Posted by Martin Mladenov, Research Scientist and Chih-wei Hsu, Software Engineer, Google Research Recommender systems are the primary interface co...
document.pdf
670.5 KB
How Machine Learning is Changing e-Government @Machine_learn
tf.keras.Model
https://www.tensorflow.org/api_docs/python/tf/keras/Model
Code: https://github.com/tensorflow/tensorflow/blob/v2.4.1/tensorflow/python/keras/engine/training.py#L138-L2675
@Machine_learn
https://www.tensorflow.org/api_docs/python/tf/keras/Model
Code: https://github.com/tensorflow/tensorflow/blob/v2.4.1/tensorflow/python/keras/engine/training.py#L138-L2675
@Machine_learn
TensorFlow
tf.keras.Model | TensorFlow v2.16.1
A model grouping layers into an object with training/inference features.
با عرض سلام ما پكيج ٣٦ پروژه عملي با يادگيري عميق همراه با داكيومنت فارسي را براي دوستاني كه مي خواهند در اين حوزه به صورت عملي كار كنند تهيه كرديم سرفصل هاي اين پكيج به ترتيب زير مي باشند:
1-Deep Learning Basic
-01_Introduction
--01_How_TensorFlow_Works
--02_Creating_and_Using_Tensors
--03_Implementing_Activation_Functions
-02_TensorFlow_Way
--01_Operations_as_a_Computational_Graph
--02_Implementing_Loss_Functions
--03_Implementing_Back_Propagation
--04_Working_with_Batch_and_Stochastic_Training
--05_Evaluating_Models
-03_Linear_Regression
--linear regression
--Logistic Regression
-04_Neural_Networks
--01_Introduction
--02_Single_Hidden_Layer_Network
--03_Using_Multiple_Layers
-05_Convolutional_Neural_Networks
--Convolution Neural Networks
--Convolutional Neural Networks Tensorflow
--TFRecord For Deep learning Models
-06_Recurrent_Neural_Networks
--Recurrent Neural Networks (RNN)
2-Classification apparel
-Classification apparel double capsule
-Classification apparel double cnn
3-ALZHEIMERS USING CNN(ResNet)
4-Fake News (Covid-19 dataset)
-Multi-channel
-3DCNN model
-Base line+ Char CNN
-Fake News Covid CapsuleNet
5-3DCNN Fake News
6-recommender systems
-GRU+LSTM MovieLens
7-Multi-Domain Sentiment Analysis
-Dranziera CapsuleNet
-Dranziera CNN Multi-channel
-Dranziera LSTM
8-Persian Multi-Domain SA
-Bi-GRU Capsule Net
-Multi-CNN
9-Recommendation system
-Factorization Recommender, Ranking Factorization Recommender, Item Similarity Recommender (turicreate)
-SVD, SVD++, NMF, Slope One, k-NN, Centered k-NN, k-NN Baseline, Co-Clustering(surprise)
10-NihX-Ray
-optimized CNN on FullDataset Nih-Xray
-MobileNet
-Transfer learning
-Capsule Network on FullDataset Nih-Xray
هزينه اين پكيج ٥٠٠هزار مي باشد و صرفا هزينه تهيه ديتاست هاست.
جهت خريد مي توانيد با ايدي بنده در ارتباط باشيد
@Raminmousa
1-Deep Learning Basic
-01_Introduction
--01_How_TensorFlow_Works
--02_Creating_and_Using_Tensors
--03_Implementing_Activation_Functions
-02_TensorFlow_Way
--01_Operations_as_a_Computational_Graph
--02_Implementing_Loss_Functions
--03_Implementing_Back_Propagation
--04_Working_with_Batch_and_Stochastic_Training
--05_Evaluating_Models
-03_Linear_Regression
--linear regression
--Logistic Regression
-04_Neural_Networks
--01_Introduction
--02_Single_Hidden_Layer_Network
--03_Using_Multiple_Layers
-05_Convolutional_Neural_Networks
--Convolution Neural Networks
--Convolutional Neural Networks Tensorflow
--TFRecord For Deep learning Models
-06_Recurrent_Neural_Networks
--Recurrent Neural Networks (RNN)
2-Classification apparel
-Classification apparel double capsule
-Classification apparel double cnn
3-ALZHEIMERS USING CNN(ResNet)
4-Fake News (Covid-19 dataset)
-Multi-channel
-3DCNN model
-Base line+ Char CNN
-Fake News Covid CapsuleNet
5-3DCNN Fake News
6-recommender systems
-GRU+LSTM MovieLens
7-Multi-Domain Sentiment Analysis
-Dranziera CapsuleNet
-Dranziera CNN Multi-channel
-Dranziera LSTM
8-Persian Multi-Domain SA
-Bi-GRU Capsule Net
-Multi-CNN
9-Recommendation system
-Factorization Recommender, Ranking Factorization Recommender, Item Similarity Recommender (turicreate)
-SVD, SVD++, NMF, Slope One, k-NN, Centered k-NN, k-NN Baseline, Co-Clustering(surprise)
10-NihX-Ray
-optimized CNN on FullDataset Nih-Xray
-MobileNet
-Transfer learning
-Capsule Network on FullDataset Nih-Xray
هزينه اين پكيج ٥٠٠هزار مي باشد و صرفا هزينه تهيه ديتاست هاست.
جهت خريد مي توانيد با ايدي بنده در ارتباط باشيد
@Raminmousa
Machine learning books and papers pinned «با عرض سلام ما پكيج ٣٦ پروژه عملي با يادگيري عميق همراه با داكيومنت فارسي را براي دوستاني كه مي خواهند در اين حوزه به صورت عملي كار كنند تهيه كرديم سرفصل هاي اين پكيج به ترتيب زير مي باشند: 1-Deep Learning Basic -01_Introduction --01_How_TensorFlow_Works…»
A Survey of Data Augmentation Approaches for NLP
Data Augmentation has becoming more and more popular and important task in NLP. On the contrary to Computer Vision where all methods now are well-known and already pre-implemented in libraries, in NLP the situation is not so consistent.
So, there has been published a nice paper that accumulated all known due today techniques, models and applications of data augmentation in texts:
https://arxiv.org/abs/2105.03075
In the appendix you can find the list of open-source that may be useful for your task.
@Machine_learn
Data Augmentation has becoming more and more popular and important task in NLP. On the contrary to Computer Vision where all methods now are well-known and already pre-implemented in libraries, in NLP the situation is not so consistent.
So, there has been published a nice paper that accumulated all known due today techniques, models and applications of data augmentation in texts:
https://arxiv.org/abs/2105.03075
In the appendix you can find the list of open-source that may be useful for your task.
@Machine_learn