
@Machine_learn
A new open benchmark for speech recognition with limited or no supervision
https://ai.facebook.com/blog/a-new-open-benchmark-for-speech-recognition-with-limited-or-no-supervision/
Code and dataset: https://ai.facebook.com/tools/libri-light
Full paper: https://arxiv.org/abs/1912.07875
A new open benchmark for speech recognition with limited or no supervision
https://ai.facebook.com/blog/a-new-open-benchmark-for-speech-recognition-with-limited-or-no-supervision/
Code and dataset: https://ai.facebook.com/tools/libri-light
Full paper: https://arxiv.org/abs/1912.07875
Meta
A new open benchmark for speech recognition with limited or no supervision
Facebook AI has released Libri-light, the largest open source dataset for speech recognition to date. This new benchmark helps researchers pretrain acoustic models to understand speech, with few to no labeled examples.
Forwarded from Machine learning books and papers (Ramin Mousa)
discriminative :
1:#Regression
2:#Logistic regression
3:#decision tree(Hunt)
4:#neural network(traditional network, deep network)
5:#Support Vector Machine(SVM)
Generative:
1:#Hidden Markov model
2:#Naive bayes
3:#K-nearest neighbor(KNN)
4:#Generative adversarial networks(GANs)
Deep learning:
1:CNN
R_CNN
Fast-RCNN
Mask-RCNN
2:RNN
3:LSTM
4:CapsuleNet
5:Siamese:
siamese cnn
siamese lstm
siamese bi-lstm
siamese CapsuleNet
6:time series data
SVR
DT(cart)
Random Forest linear
Bagging
Boosting
جهت درخواست و راهنمایی در رابطه با پیاده سازی مقالات و پایان نامه ها در رابطه با مباحث deep learning و machine learning با ایدی زیر در ارتباط باشید
@Raminmousa
1:#Regression
2:#Logistic regression
3:#decision tree(Hunt)
4:#neural network(traditional network, deep network)
5:#Support Vector Machine(SVM)
Generative:
1:#Hidden Markov model
2:#Naive bayes
3:#K-nearest neighbor(KNN)
4:#Generative adversarial networks(GANs)
Deep learning:
1:CNN
R_CNN
Fast-RCNN
Mask-RCNN
2:RNN
3:LSTM
4:CapsuleNet
5:Siamese:
siamese cnn
siamese lstm
siamese bi-lstm
siamese CapsuleNet
6:time series data
SVR
DT(cart)
Random Forest linear
Bagging
Boosting
جهت درخواست و راهنمایی در رابطه با پیاده سازی مقالات و پایان نامه ها در رابطه با مباحث deep learning و machine learning با ایدی زیر در ارتباط باشید
@Raminmousa
Forwarded from Ramin Mousa
81d1db19834f123fcfc79ad32097aeafe17f.pdf
1.4 MB
# Histogram-based Outlier Score (HBOS): A fastUnsupervised Anomaly Detection Algorithm #Paper #HBOS #Anomaly_Detection @Machine_learn
Learning Singing From Speech
Article: https://arxiv.org/abs/1912.10128
Example: https://tencent-ailab.github.io/learning_singing_from_speech/
Article: https://arxiv.org/abs/1912.10128
Example: https://tencent-ailab.github.io/learning_singing_from_speech/
arXiv.org
Learning Singing From Speech
We propose an algorithm that is capable of synthesizing high quality target speaker's singing voice given only their normal speech samples. The proposed algorithm first integrate speech and...
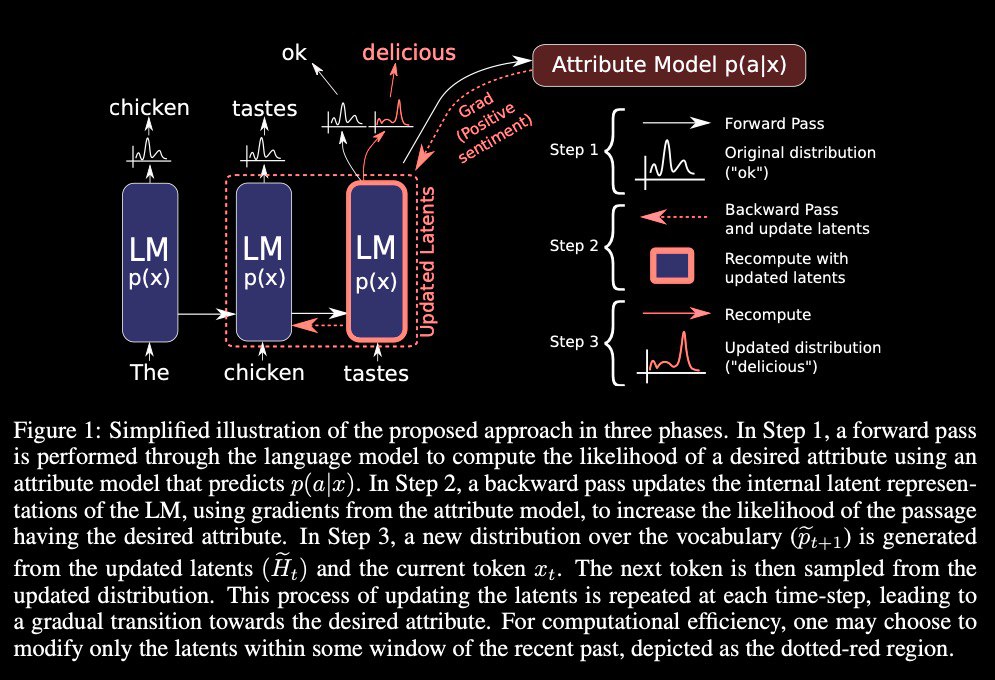
Uber AI Plug and Play Language Model (PPLM)
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
@Machine_learn
#nlp #lm #languagemodeling #uber #pplm
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
@Machine_learn
#nlp #lm #languagemodeling #uber #pplm
{kind=link}
Forwarded from بینام
Practical Computer Vision Applications Using Deep Learning with CNNs — Ahmed Fawzy Gad (en) 2018
@Machine_learn
@Machine_learn
Forwarded from بینام
Practical Computer Vision Applications (en).pdf
9.6 MB
Forwarded from Computer Science and Programming
YOLACT (You Only Look At CoefficienTs) - Real-time Instance Segmentation
Results are impressive, above 30 FPS on COCO test-dev
Results are impressive, above 30 FPS on COCO test-dev
AI & Art
@Machine_learn
some artist use the large collections of #data & #ML #algorithms to create mesmerizing & dynamic #installations
watch the video —> https://youtu.be/I-EIVlHvHRM
@Machine_learn
some artist use the large collections of #data & #ML #algorithms to create mesmerizing & dynamic #installations
watch the video —> https://youtu.be/I-EIVlHvHRM
YouTube
How This Guy Uses A.I. to Create Art | Obsessed | WIRED
Artist Refik Anadol doesn't work with paintbrushes or clay. Instead, he uses large collections of data and machine learning algorithms to create mesmerizing and dynamic installations.
Machine Hallucination at Artechouse NYC: https://www.artechouse.com/nyc…
Machine Hallucination at Artechouse NYC: https://www.artechouse.com/nyc…
Forwarded from بینام
Machine Learning and Security (en).pdf
6.4 MB
Forwarded from بینام
[Jojo_John_Moolayil]_Learn_Keras_for_Deep_Neural_N.pdf
2.7 MB
Learn Keras for Deep Neural Networks: A Fast-Track Approach to Modern Deep Learning with Python
@Machine_learn
@Machine_learn
@Machine_learn
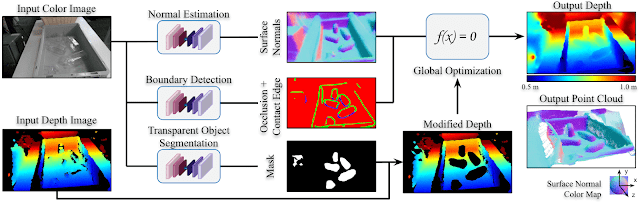
Learning to See Transparent Objects
ClearGrasp uses 3 neural networks: a network to estimate surface normals, one for occlusion boundaries (depth discontinuities), and one that masks transparent objects
Google research: https://ai.googleblog.com/2020/02/learning-to-see-transparent-objects.html
Code: https://github.com/Shreeyak/cleargrasp
Dataset: https://sites.google.com/view/transparent-objects
3D Shape Estimation of Transparent Objects for Manipulation: https://sites.google.com/view/cleargrasp
Learning to See Transparent Objects
ClearGrasp uses 3 neural networks: a network to estimate surface normals, one for occlusion boundaries (depth discontinuities), and one that masks transparent objects
Google research: https://ai.googleblog.com/2020/02/learning-to-see-transparent-objects.html
Code: https://github.com/Shreeyak/cleargrasp
Dataset: https://sites.google.com/view/transparent-objects
3D Shape Estimation of Transparent Objects for Manipulation: https://sites.google.com/view/cleargrasp
{kind=link}
Machine learning books and papers pinned «https://t.me/Machine_learn»
GANILLA: Generative Adversarial Networks for Image to Illustration Translation.
Github: https://github.com/giddyyupp/ganilla
Dataset: https://github.com/giddyyupp/ganilla/blob/master/docs/datasets.md
Paper: https://arxiv.org/abs/2002.05638v1
Github: https://github.com/giddyyupp/ganilla
Dataset: https://github.com/giddyyupp/ganilla/blob/master/docs/datasets.md
Paper: https://arxiv.org/abs/2002.05638v1
{kind=link}
Deep learning of dynamical attractors from time series measurements
Embed complex time series using autoencoders and a loss function based on penalizing false-nearest-neighbors.
Code: https://github.com/williamgilpin/fnn
Paper: https://arxiv.org/abs/2002.05909
Embed complex time series using autoencoders and a loss function based on penalizing false-nearest-neighbors.
Code: https://github.com/williamgilpin/fnn
Paper: https://arxiv.org/abs/2002.05909
GitHub
GitHub - williamgilpin/fnn: Embed strange attractors using a regularizer for autoencoders
Embed strange attractors using a regularizer for autoencoders - williamgilpin/fnn
Forwarded from بینام
Deep Reinforcement Learning with Guar Perf.pdf
11.2 MB