This media is not supported in your browser
VIEW IN TELEGRAM
Сделали скилл для создания сред обучения с подкреплением
Теперь любой может создавать среды обучения с подкреплением :
ps. В создании RL-сред для обучения есть гораздо больше аспектов. Один из ключевых это данные, которые этот скилл напрямую не решает. Однако скилл помогает реализовывать инструменты, награды и другие компоненты RL-среды, упрощая переход от идеи к реализации и позволяя быстрее собирать решения на разных фреймворках.
Это всё ещё очень ранняя версия работы и, скорее всего, сильно изменится.
Открыт для вклада в проект и предложений по улучшению.😀
👉 @DataSciencegx
Теперь любой может создавать среды обучения с подкреплением :
$ npx skills add adithya-s-k/RL_Envs_101- Можно создавать среды в нескольких фреймворках, таких как OpenEnv, OpenReward, Verifiers, NemoGym и другие
- в репозитории есть живые рабочие примеры сред, на которые может ссылаться ваш кодинг агент
- скилл изначально рассчитан на то, чтобы определить, какой тип модели вы обучаете, и уже с учётом этого создавать среду
ps. В создании RL-сред для обучения есть гораздо больше аспектов. Один из ключевых это данные, которые этот скилл напрямую не решает. Однако скилл помогает реализовывать инструменты, награды и другие компоненты RL-среды, упрощая переход от идеи к реализации и позволяя быстрее собирать решения на разных фреймворках.
Это всё ещё очень ранняя версия работы и, скорее всего, сильно изменится.
Открыт для вклада в проект и предложений по улучшению.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤1
This media is not supported in your browser
VIEW IN TELEGRAM
Дообучение Google Gemma 4 полностью бесплатно
Нужен только браузер и доступ к более чем 500 моделям на выбор.
Процесс простой:
1. Открыть блокнот Unsloth в Colab
2. Выбрать модель и датасет
3. Запустить обучение
Готово😂
👉 @DataSciencegx
Нужен только браузер и доступ к более чем 500 моделям на выбор.
Процесс простой:
1. Открыть блокнот Unsloth в Colab
2. Выбрать модель и датасет
3. Запустить обучение
Готово
Please open Telegram to view this post
VIEW IN TELEGRAM
❤6🔥5
Мой пайплайн генерации датасета для fine-tuning:
Проще говоря, я использую Codex как мозг, а Deepseek как «мускулы», чтобы вручную (handcraft) собирать каждую строку датасета.
Такое «ручное создание» даёт высокое качество. Синтетическая генерация датасета (через Python-скрипты и перефразирование) несложная, но обычно приводит к низкому качеству данных.
Низкое качество данных = низкое качество модели
Но в этом пайплайне Codex проектирует полный workflow для Deepseek. То есть Deepseek не «думает» сам, а просто выполняет каждый batch по спецификации Codex.
После генерации каждый batch проходит через жёсткие quality gates, которые также построены Codex, чтобы отфильтровать слабые строки и оставить только качественные данные.
Самое интересное: с каждым batch Codex улучшает и спецификацию генерации для Deepseek, и quality gates. Этот цикл делает пайплайн быстрее, дешевле и постоянно повышает качество данных.
DeepSeek v4 Pro сейчас очень дешёвый. Я сгенерировал датасет на 100M+ параметров за $80 и потратил около 95% недельной подписки Codex 20x Pro.
Этот пайплайн становится полностью автономным после того, как я утверждаю workflow Codex.
Просто вставь это изображение в Codex и попроси построить pipeline генерации датасета под твой кейс (объясни подробно: какую модель ты будешь дообучать? есть ли у тебя raw dataset или нет и т.д.). Дальше Codex всё сделает сам.
Напиши, какой у тебя опыт.
👉 @DataSciencegx
Codex 5.5 — как оркестратор
DeepSeek v4 Pro — как генератор
Проще говоря, я использую Codex как мозг, а Deepseek как «мускулы», чтобы вручную (handcraft) собирать каждую строку датасета.
Такое «ручное создание» даёт высокое качество. Синтетическая генерация датасета (через Python-скрипты и перефразирование) несложная, но обычно приводит к низкому качеству данных.
Низкое качество данных = низкое качество модели
Но в этом пайплайне Codex проектирует полный workflow для Deepseek. То есть Deepseek не «думает» сам, а просто выполняет каждый batch по спецификации Codex.
После генерации каждый batch проходит через жёсткие quality gates, которые также построены Codex, чтобы отфильтровать слабые строки и оставить только качественные данные.
Самое интересное: с каждым batch Codex улучшает и спецификацию генерации для Deepseek, и quality gates. Этот цикл делает пайплайн быстрее, дешевле и постоянно повышает качество данных.
DeepSeek v4 Pro сейчас очень дешёвый. Я сгенерировал датасет на 100M+ параметров за $80 и потратил около 95% недельной подписки Codex 20x Pro.
Этот пайплайн становится полностью автономным после того, как я утверждаю workflow Codex.
Просто вставь это изображение в Codex и попроси построить pipeline генерации датасета под твой кейс (объясни подробно: какую модель ты будешь дообучать? есть ли у тебя raw dataset или нет и т.д.). Дальше Codex всё сделает сам.
Напиши, какой у тебя опыт.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3👀2
This media is not supported in your browser
VIEW IN TELEGRAM
Kрутейший интерактивный учебник по теории вероятностей и статистике
Внутри наглядные визуализации, интерактивчики и минимум сухой теории. Можно покрутить распределения, посэмплить выборки, поиграться с доверительными интервалами и наглядно увидеть, как это всё работает
Забираем тут, советую открывать с десктопа
👉 @DataSciencegx
Внутри наглядные визуализации, интерактивчики и минимум сухой теории. Можно покрутить распределения, посэмплить выборки, поиграться с доверительными интервалами и наглядно увидеть, как это всё работает
Забираем тут, советую открывать с десктопа
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥5
Бесплатный плейлист из 23 практических туториалов по проектам на Python и Pandas, включая анализ e-commerce, датасеты по фильмам, медицинские данные и создание веб-приложений на Streamlit.
Идеально для формирования сильного портфолио по анализу данных на реальных кейсах.
Плейлист на YouTube
👉 @DataSciencegx
Идеально для формирования сильного портфолио по анализу данных на реальных кейсах.
Плейлист на YouTube
Please open Telegram to view this post
VIEW IN TELEGRAM
👍4👎3🔥2
Поздравляем, вы на 1 шаг ближе к работе мечты 🥳
Осталось только прочитать этот пост, подписаться на канал и откликнуться на вакансию 😉
Avito Career* — место, где Авито делится актуальными вакансиями и стажировками для Data Science специалистов.
Подписывайтесь, чтобы найти ту самую работу ✨
*карьера
Осталось только прочитать этот пост, подписаться на канал и откликнуться на вакансию 😉
Avito Career* — место, где Авито делится актуальными вакансиями и стажировками для Data Science специалистов.
Подписывайтесь, чтобы найти ту самую работу ✨
*карьера
❤1
Производительная ветка llama.cpp с интеграцией нескольких оптимизаций для ускорения инференса и увеличения эффективного контекстного окна: https://github.com/Anbeeld/beellama.cpp
BeeLlama.cpp объединяет основную ветку llama.cpp с технологиями TurboQuant (TCQ) и DFlash speculative decoding, а также KV-cache компрессию. В результате добавляются дополнительные оптимизации для работы с LLM-инференсом:
-speculative decoding с адаптивной глубиной
- сжатие KV-cache (TurboQuant / TCQ)
- серверные механизмы адаптивного контроля “draft” генерации
- защита inference loop (защита от зацикливания вычислений)
Заявленные эффекты:
до ~3× ускорение инференса
до ~7.5× увеличение эффективной длины контекста при том же объёме VRAM
Проект по сути представляет собой performance-oriented форк llama.cpp, ориентированный на оптимизацию вывода LLM-моделей и более эффективное использование памяти и вычислительных ресурсов.
👉 @DataSciencegx
BeeLlama.cpp объединяет основную ветку llama.cpp с технологиями TurboQuant (TCQ) и DFlash speculative decoding, а также KV-cache компрессию. В результате добавляются дополнительные оптимизации для работы с LLM-инференсом:
-speculative decoding с адаптивной глубиной
- сжатие KV-cache (TurboQuant / TCQ)
- серверные механизмы адаптивного контроля “draft” генерации
- защита inference loop (защита от зацикливания вычислений)
Заявленные эффекты:
до ~3× ускорение инференса
до ~7.5× увеличение эффективной длины контекста при том же объёме VRAM
Проект по сути представляет собой performance-oriented форк llama.cpp, ориентированный на оптимизацию вывода LLM-моделей и более эффективное использование памяти и вычислительных ресурсов.
Please open Telegram to view this post
VIEW IN TELEGRAM
GitHub
GitHub - Anbeeld/beellama.cpp: DFlash & TurboQuant in llama.cpp with up to 3x faster generation and 7.5x more KV cache in same…
DFlash & TurboQuant in llama.cpp with up to 3x faster generation and 7.5x more KV cache in same VRAM - Anbeeld/beellama.cpp
Проекты на PyTorch
Плейлист, который помогает изучать PyTorch через работу над продвинутыми проектами.
👉 @DataSciencegx
Плейлист, который помогает изучать PyTorch через работу над продвинутыми проектами.
Please open Telegram to view this post
VIEW IN TELEGRAM
Находка: репозиторий, где куча туториалов по созданию AI-агентов, готовых к продакшену и с реальными кейсами использования
Весь код в открытом доступе и есть объяснение, как их развернуть. GitHub: agents-towards-production😇
👉 @DataSciencegx
Весь код в открытом доступе и есть объяснение, как их развернуть. GitHub: agents-towards-production
Please open Telegram to view this post
VIEW IN TELEGRAM
❤5
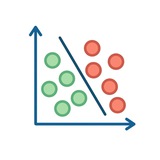
Почему это называют «трюком» (kernel trick)
Во многих алгоритмах машинного обучения используются ядра: метод опорных векторов, ядро главных компонент и другие. Их задача — вычислять скалярное произведение в некотором преобразованном пространстве признаков, обычно высокой размерности, без явного перехода в это пространство.
Идея такая: вместо того чтобы явно строить отображение φ(x) в новое пространство и затем считать ⟨φ(X), φ(Y)⟩, используется функция ядра k(X, Y), которая сразу возвращает результат этого скалярного произведения.
Пример с полиномиальным ядром:
k(X, Y) = (1 + XᵀY)²
Пусть:
X = (x1, x2)
Y = (y1, y2)
Если раскрыть выражение, оно превращается в скалярное произведение двух векторов в пространстве большей размерности (в данном случае — 6 измерений). При этом сами координаты в этом пространстве не вычисляются явно.
Отсюда смысл «трюка»: вычисление результата в высокоразмерном пространстве происходит без явного построения самих векторов в этом пространстве.
Гауссово ядро (RBF) усиливает этот эффект: оно соответствует работе в бесконечномерном пространстве признаков, при этом вычисления остаются конечными и компактными за счёт формы функции ядра.
Математика за RBF-ядром → https://www.dailydoseofds.com/p/the-mathematics-behind-rbf-kernel/
👉 @DataSciencegx
Во многих алгоритмах машинного обучения используются ядра: метод опорных векторов, ядро главных компонент и другие. Их задача — вычислять скалярное произведение в некотором преобразованном пространстве признаков, обычно высокой размерности, без явного перехода в это пространство.
Идея такая: вместо того чтобы явно строить отображение φ(x) в новое пространство и затем считать ⟨φ(X), φ(Y)⟩, используется функция ядра k(X, Y), которая сразу возвращает результат этого скалярного произведения.
Пример с полиномиальным ядром:
k(X, Y) = (1 + XᵀY)²
Пусть:
X = (x1, x2)
Y = (y1, y2)
Если раскрыть выражение, оно превращается в скалярное произведение двух векторов в пространстве большей размерности (в данном случае — 6 измерений). При этом сами координаты в этом пространстве не вычисляются явно.
Отсюда смысл «трюка»: вычисление результата в высокоразмерном пространстве происходит без явного построения самих векторов в этом пространстве.
Гауссово ядро (RBF) усиливает этот эффект: оно соответствует работе в бесконечномерном пространстве признаков, при этом вычисления остаются конечными и компактными за счёт формы функции ядра.
Математика за RBF-ядром → https://www.dailydoseofds.com/p/the-mathematics-behind-rbf-kernel/
Please open Telegram to view this post
VIEW IN TELEGRAM
❤4👍2
Визуальный разбор недавних изменений в архитектурах LLM — от Gemma 4 до DeepSeek V4.
Основной фокус — оптимизации для длинного контекста: шаринг KV-кэша, эмбеддинги на уровне слоёв, layer-wise attention budgets, сжатое внимание и mHC.
Ссылка: статья
👉 @DataSciencegx
Основной фокус — оптимизации для длинного контекста: шаринг KV-кэша, эмбеддинги на уровне слоёв, layer-wise attention budgets, сжатое внимание и mHC.
Ссылка: статья
Please open Telegram to view this post
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
Преврати любую авторегрессионную языковую модель в диффузионную языковую модель.
dLLM — это Python-библиотека, которая объединяет обучение и оценку диффузионных языковых моделей.
Её также можно использовать, чтобы превратить ЛЮБУЮ авторегрессионную языковую модель в диффузионную языковую модель с минимальными вычислительными затратами.
100% открытый исходный код.
👉 @DataSciencegx
dLLM — это Python-библиотека, которая объединяет обучение и оценку диффузионных языковых моделей.
Её также можно использовать, чтобы превратить ЛЮБУЮ авторегрессионную языковую модель в диффузионную языковую модель с минимальными вычислительными затратами.
100% открытый исходный код.
Please open Telegram to view this post
VIEW IN TELEGRAM