
New tutorial!🚀
Learn how to build an Image Hashing Search Engine that scales to 1,000,000s of images using #OpenCV, #Python, and VP-Trees.
Full tutorial w/ code here: http://pyimg.co/myj11 👍 #ComputerVision #MachineLearning #ArtificialIntelligence #DataScience #AI #BigData
Learn how to build an Image Hashing Search Engine that scales to 1,000,000s of images using #OpenCV, #Python, and VP-Trees.
Full tutorial w/ code here: http://pyimg.co/myj11 👍 #ComputerVision #MachineLearning #ArtificialIntelligence #DataScience #AI #BigData
PyImageSearch
Building an Image Hashing Search Engine with VP-Trees and OpenCV - PyImageSearch
In this tutorial, you will learn how to build a scalable image hashing search engine using OpenCV, Python, and VP-Trees.
Awesome Graph Classification
A collection of important graph embedding, classification and representation learning papers with implementations.
GitHub, by Benedek Rozemberczki: https://lnkd.in/eErZBnh
#graph2vec #deepgraphkernels #graphattentionmodel
#graphattentionnetworks
A collection of important graph embedding, classification and representation learning papers with implementations.
GitHub, by Benedek Rozemberczki: https://lnkd.in/eErZBnh
#graph2vec #deepgraphkernels #graphattentionmodel
#graphattentionnetworks
GitHub
benedekrozemberczki/awesome-graph-classification
A collection of important graph embedding, classification and representation learning papers with implementations. - benedekrozemberczki/awesome-graph-classification
"Mathematics For Machine Learning"
A book that is intended to help people understand the #mathematics behind the #MachineLearning techniques.
Its aim is to make people understand what goes under the hood in common ML algorithms.
The best part is that the team is also working on Jupyter notebook tutorials
Download the PDF of the book: https://lnkd.in/e-gXPRf
100% OFF in Home Delivery Asia 2019>>> https://lnkd.in/f_TxgKN
For Data Science Implementations:
Know Data Science https://lnkd.in/fMHtxYP
Understand How to answer Why https://lnkd.in/f396Dqg
Machine Learning Terminology https://lnkd.in/fCihY9W
Understand Machine Learning Implementation https://lnkd.in/f5aUbBM
Machine Learning on Retail https://lnkd.in/fihPTJf
and Marketing https://lnkd.in/fBncKiy
A book that is intended to help people understand the #mathematics behind the #MachineLearning techniques.
Its aim is to make people understand what goes under the hood in common ML algorithms.
The best part is that the team is also working on Jupyter notebook tutorials
Download the PDF of the book: https://lnkd.in/e-gXPRf
100% OFF in Home Delivery Asia 2019>>> https://lnkd.in/f_TxgKN
For Data Science Implementations:
Know Data Science https://lnkd.in/fMHtxYP
Understand How to answer Why https://lnkd.in/f396Dqg
Machine Learning Terminology https://lnkd.in/fCihY9W
Understand Machine Learning Implementation https://lnkd.in/f5aUbBM
Machine Learning on Retail https://lnkd.in/fihPTJf
and Marketing https://lnkd.in/fBncKiy
Detecting new knowledge in unstructured text using ML. More evidence that when you put large amounts of papers and reports together and apply OpenSource machine learning to the text - the whole can be greater than the sum of its parts. This paper focuses on Thermoelectric materials.
Vice News Article
https://lnkd.in/gkXnEXt
Nature Paper (Tshitoyan et al 2019)
https://www.nature.com/articles/s41586-019-1335-8
Vice News Article
https://lnkd.in/gkXnEXt
Nature Paper (Tshitoyan et al 2019)
https://www.nature.com/articles/s41586-019-1335-8
lnkd.in
LinkedIn
This link will take you to a page that’s not on LinkedIn
Podcast:
Ali Ghodsi On Building A $2.7B Business And Being Considered One Of The True Founders Of Artificial Intelligence
https://alejandrocremades.com/ali-ghodsi/
Ali Ghodsi On Building A $2.7B Business And Being Considered One Of The True Founders Of Artificial Intelligence
https://alejandrocremades.com/ali-ghodsi/
Alejandro Cremades
Ali Ghodsi On Building A $28 Billion Business And Being Considered One Of The True Founders Of Artificial Intelligence - Alejandro…
Ali Ghodsi is the cofounder and CEO of Databricks which unifies analytics across data and the business. The company has raised $500M at a $2.75B valuation
The 5 graph algorithms that you should know
Rahul Agarwal describes some of the most important graph algorithms you should know and how to implement them using Python.
Rahul Agarwal describes some of the most important graph algorithms you should know and how to implement them using Python.
A simple neural network with Python and Keras
https://www.pyimagesearch.com/2016/09/26/a-simple-neural-network-with-python-and-keras
https://www.pyimagesearch.com/2016/09/26/a-simple-neural-network-with-python-and-keras
PyImageSearch
A simple neural network with Python and Keras - PyImageSearch
Learn how to create a simple neural network using the Keras neural network and deep learning library along with the Python programming language.
Detecting and treating outliers is a necessity in any dataset as it inevitably introduces the deviation in the model estimations. It can make the difference between winning and loosing a data science competition.
https://lnkd.in/fMV6GaY
This article deals with the detection of the outliers in Time Series data using different ideas, every idea improving upon the previous one and finally treating the outliers in the best way possible.
Hint of ideas covered.....
Idea #1 — Winsorization
Idea #2 Standard deviation etc.
https://lnkd.in/fMV6GaY
This article deals with the detection of the outliers in Time Series data using different ideas, every idea improving upon the previous one and finally treating the outliers in the best way possible.
Hint of ideas covered.....
Idea #1 — Winsorization
Idea #2 Standard deviation etc.
Medium
Forecasting: how to detect outliers?
(the article below is an extract from the book Data Science for Supply Chain Forecast, available here)
An article covering the case study over "Customer Transaction Prediction using LightGBM".
https://medium.com/analytics-vidhya/https-medium-com-kushagrarajtiwari-customer-transaction-prediction-3191c6c634dc
It comprehensively covers:
1. General Business Significance of this problem
2. Exploratory Data Analysis
3. Feature Engineering
4. Why use LightGBM for this problem
A good read if you want to explore problems in bank/financial domain.
https://medium.com/analytics-vidhya/https-medium-com-kushagrarajtiwari-customer-transaction-prediction-3191c6c634dc
It comprehensively covers:
1. General Business Significance of this problem
2. Exploratory Data Analysis
3. Feature Engineering
4. Why use LightGBM for this problem
A good read if you want to explore problems in bank/financial domain.
Medium
Customer Transaction Prediction using LightGBM
Exploratory Data Analysis and modelling with imbalanced data.
Automating the end-to-end lifecycle of Machine Learning applications
#CD4ML #software_engineering #ML
Discoverable and Accessible Data
Reproducible Model Training
Model Serving (Embedded model, Model as service)
Testing and Quality in Machine Learning
Experiments Tracking
Model Deployment (Multiple models, Shadow models)
Model Monitoring and Observability
https://martinfowler.com/articles/cd4ml.html
#CD4ML #software_engineering #ML
Discoverable and Accessible Data
Reproducible Model Training
Model Serving (Embedded model, Model as service)
Testing and Quality in Machine Learning
Experiments Tracking
Model Deployment (Multiple models, Shadow models)
Model Monitoring and Observability
https://martinfowler.com/articles/cd4ml.html
martinfowler.com
Continuous Delivery for Machine Learning
How to apply Continuous Delivery to build Machine Learning applications
Microsoft open-sourced scripts and notebooks to pre-train and finetune BERT natural language model with domain-specific texts
Github: https://github.com/microsoft/AzureML-BERT
Earlier: https://t.me/opendatascience/837
#Bert #Microsoft #NLP #dl
Github: https://github.com/microsoft/AzureML-BERT
Earlier: https://t.me/opendatascience/837
#Bert #Microsoft #NLP #dl
GitHub
GitHub - microsoft/AzureML-BERT: End-to-End recipes for pre-training and fine-tuning BERT using Azure Machine Learning Service
End-to-End recipes for pre-training and fine-tuning BERT using Azure Machine Learning Service - microsoft/AzureML-BERT
Great collection of practical rules for routine DS engineering / research job.
Machine Learning in a company is 10% Data Science & 90% other challenges, this pdf provides a great deal of principals and solutions to deal with them.
We can only recommend saving this post to your Saved Messages by forwarding it to yourself.
Link: http://martin.zinkevich.org/rules_of_ml/rules_of_ml.pdf
#cheatsheet #advice #practical #common #shouldbesaved
Machine Learning in a company is 10% Data Science & 90% other challenges, this pdf provides a great deal of principals and solutions to deal with them.
We can only recommend saving this post to your Saved Messages by forwarding it to yourself.
Link: http://martin.zinkevich.org/rules_of_ml/rules_of_ml.pdf
#cheatsheet #advice #practical #common #shouldbesaved
CS238: Decision Making under Uncertainty (AA 228)
Textbook: Decision Making Under Uncertainty: Theory and Application by Mykel J. Kochenderfer et al. (MIT Lincoln Laboratory Series)
See course materials
http://web.stanford.edu/class/aa228/
Textbook: Decision Making Under Uncertainty: Theory and Application by Mykel J. Kochenderfer et al. (MIT Lincoln Laboratory Series)
See course materials
http://web.stanford.edu/class/aa228/
web.stanford.edu
AA228/CS238 | Decision Making under Uncertainty
Description This course introduces decision making under uncertainty from a computational perspective and provides an overview of the necessary tools for building autonomous and decision-support systems. Following an introduction to probabilistic models and…
Estimating the success of re-identifications in incomplete datasets using generative models
99.98% of Americans would be correctly re-identified in any dataset using 15 demographic attributes, suggesting that even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR.
This is a big concern about privacy and a problem for Data Engineering, especially for those working with anonymized personal information. Paper provides a way to re-identify person from anonymized dataset, this can be useful for people who work for government or security companies
https://www.reddit.com/r/science/comments/chko43/9998_of_americans_would_be_correctly_reidentified/
#privacy #gdpr #federatedlearning #ml
99.98% of Americans would be correctly re-identified in any dataset using 15 demographic attributes, suggesting that even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR.
This is a big concern about privacy and a problem for Data Engineering, especially for those working with anonymized personal information. Paper provides a way to re-identify person from anonymized dataset, this can be useful for people who work for government or security companies
https://www.reddit.com/r/science/comments/chko43/9998_of_americans_would_be_correctly_reidentified/
#privacy #gdpr #federatedlearning #ml
Reddit
From the science community on Reddit: 99.98% of Americans would be correctly re-identified in any dataset using 15 demographic…
Posted by FvDijk - 348 votes and 29 comments
Great article on text preprocessing, covering cleaning, #tokenization, #lemmatization and other aspects
Link: https://medium.com/@datamonsters/text-preprocessing-in-python-steps-tools-and-examples-bf025f872908
#NLP #NLU #datacleaning
Link: https://medium.com/@datamonsters/text-preprocessing-in-python-steps-tools-and-examples-bf025f872908
#NLP #NLU #datacleaning
Medium
Text Preprocessing in Python: Steps, Tools, and Examples
by Olga Davydova, Data Monsters
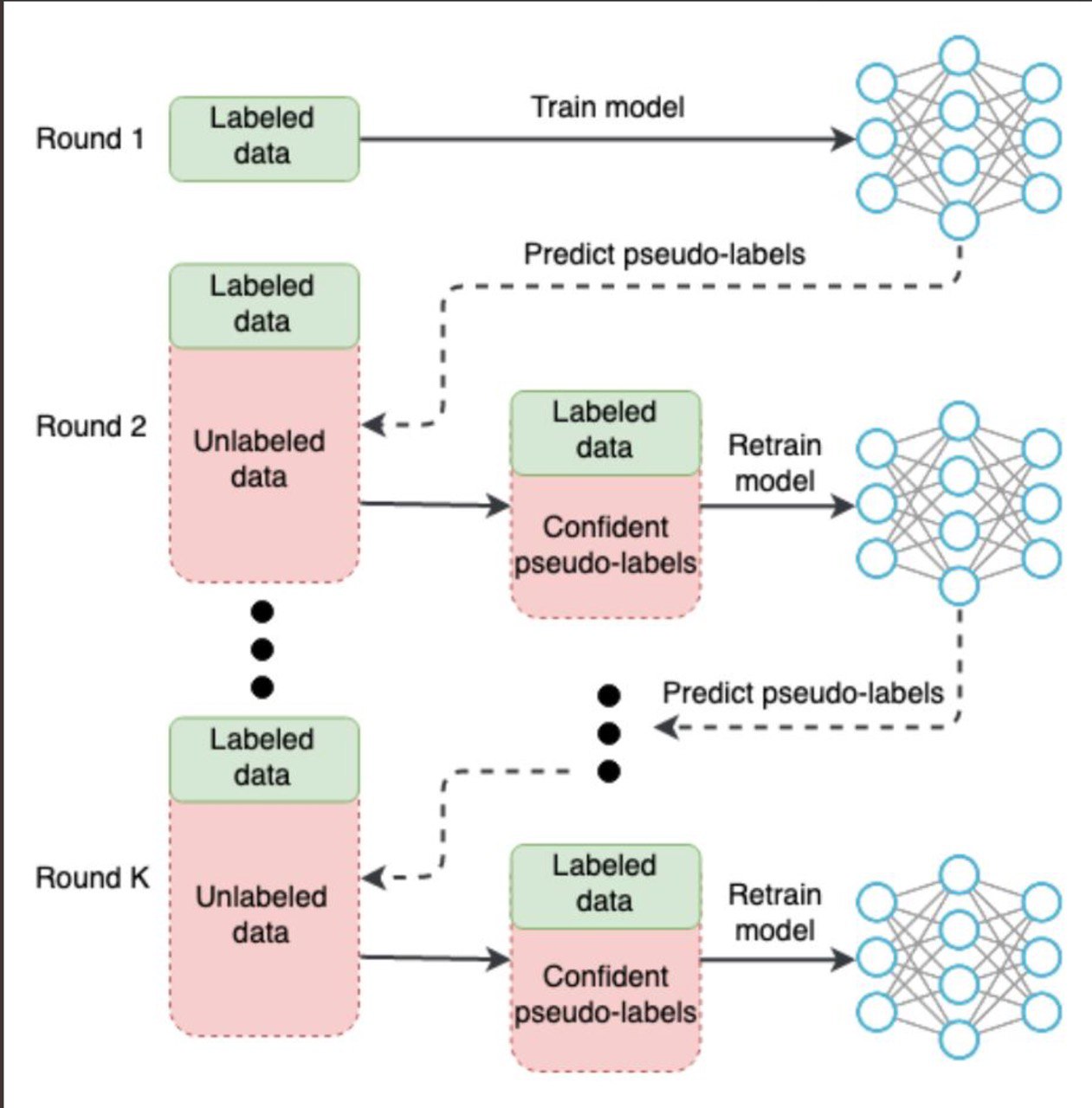
New paper on training with pseudo-labels for semantic segmentation
Semi-Supervised Segmentation of Salt Bodies in Seismic Images:
SOTA (1st place) at TGS Salt Identification Challenge.
Github: https://github.com/ybabakhin/kaggle_salt_bes_phalanx
ArXiV: https://arxiv.org/abs/1904.04445
#GCPR2019 #Segmentation #CV
Semi-Supervised Segmentation of Salt Bodies in Seismic Images:
SOTA (1st place) at TGS Salt Identification Challenge.
Github: https://github.com/ybabakhin/kaggle_salt_bes_phalanx
ArXiV: https://arxiv.org/abs/1904.04445
#GCPR2019 #Segmentation #CV
{kind=link}
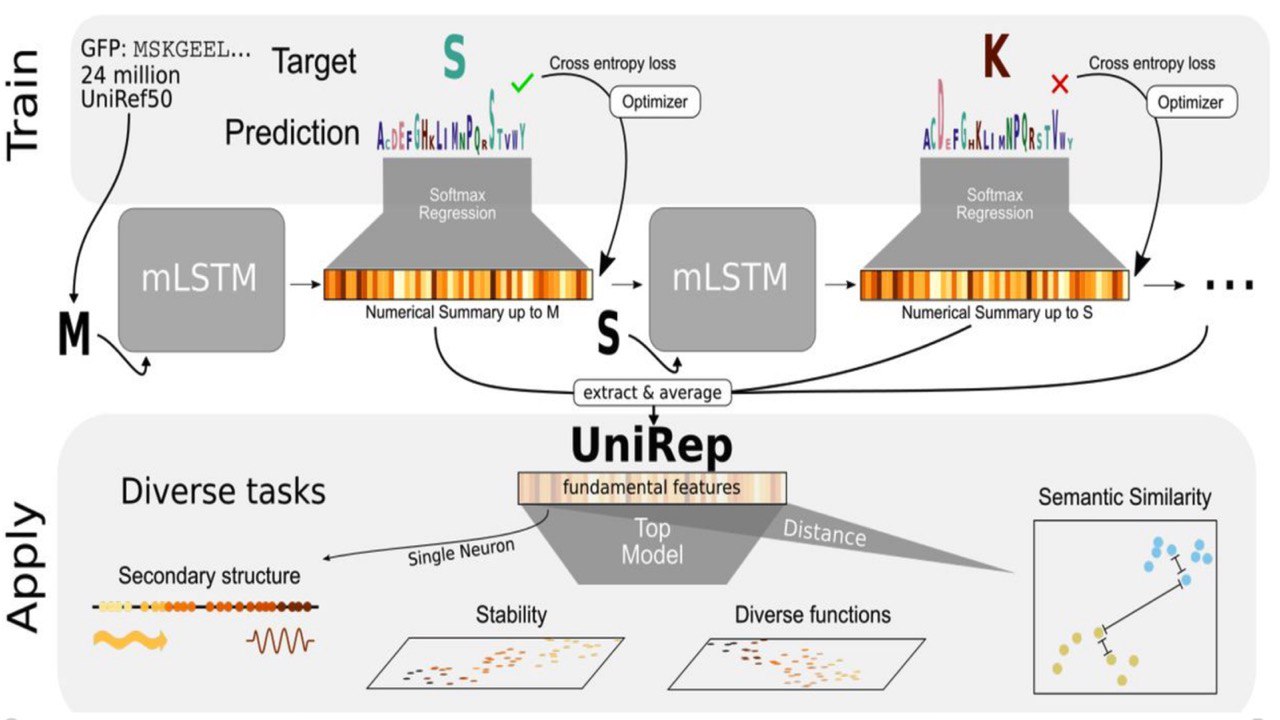
Unified rational protein engineering with sequence-only deep representation learning
UniRep predicts amino-acid sequences that form stable bonds. In industry, that’s vital for determining the production yields, reaction rates, and shelf life of protein-based products.
Link: https://www.biorxiv.org/content/10.1101/589333v1.full
#biolearning #rnn #Harvard #sequence #protein
UniRep predicts amino-acid sequences that form stable bonds. In industry, that’s vital for determining the production yields, reaction rates, and shelf life of protein-based products.
Link: https://www.biorxiv.org/content/10.1101/589333v1.full
#biolearning #rnn #Harvard #sequence #protein
{kind=link}
Exploring Weight Agnostic Neural Networks
Exploration of agents that can already perform well in their environment without the need to learn weight parameters.
Link: https://ai.googleblog.com
Code: https://github.com/google/brain-tokyo-workshop/tree/master/WANNRelease
Exploration of agents that can already perform well in their environment without the need to learn weight parameters.
Link: https://ai.googleblog.com
Code: https://github.com/google/brain-tokyo-workshop/tree/master/WANNRelease