
Forwarded from Бюро «Поле» (Michael Bode)
В начале августа мы провели воркшоп «ИИ для исследований» (есть запись) — и диву дались, сколько человек в итоге посетило встречу. Упёрлись в ограничение нашего тарифа Zoom, сделали выводы, перешли на самый-пресамый премиум, и теперь вал регистраций нам не страшен: места хватит для всех.
Как и обещали, продолжение грядёт. Предварительно наметили следующий воркшоп на 6 сентябоя, пятницу, 19:00 мск — через пару дней запостим подробности, включая программу, и дадим ссылку для регистрации. Мероприятие снова будет бесплатным для всех желающих.
Но вот что касается темы, запросов была тьма — и они разные. Ну очень. Посему предлагаем проголосовать.
Как и обещали, продолжение грядёт. Предварительно наметили следующий воркшоп на 6 сентябоя, пятницу, 19:00 мск — через пару дней запостим подробности, включая программу, и дадим ссылку для регистрации. Мероприятие снова будет бесплатным для всех желающих.
Но вот что касается темы, запросов была тьма — и они разные. Ну очень. Посему предлагаем проголосовать.
👍1
Forwarded from Gonzo
В рамках готовящегося выставочного проекта необходимо провести серию глубинных интервью с жителями одного из городов Ленинградской области. Общая продолжительность работы в поле — около недели (конец сентября / начало октября).
Материалы исследования станут частью передвижного выставочного проекта, посвященного теме наследия и памяти. Подробности и условия работы сможем обсудить по Зуму. С нетерпением ждем ваши резюме на почту hr@gonzo-design.ru с темой письма «Антрополог/ для исследования в ЛО».
Материалы исследования станут частью передвижного выставочного проекта, посвященного теме наследия и памяти. Подробности и условия работы сможем обсудить по Зуму. С нетерпением ждем ваши резюме на почту hr@gonzo-design.ru с темой письма «Антрополог/ для исследования в ЛО».
🔥2
Forwarded from ⅁ garage.digital
Многие дата-аналитики не задумываются о том, что их работа — политическое действие, которое меняет облик нашего мира. И это проблема, уверен американский политолог Бен Грин. Ведь сегодня и государственные институты, и частные бизнесы пытаются предсказать будущее, используя анализ данных. Чье-то завтра буквально зависит от того, как дата-инженер проаналзирует данные сегодня — и какие закономерности там найдет.
Сегодня мы рассказываем об академической статье Грина, в которой он осмысляет политику анализа данных и рассказывает о том, как сделать его более справедливым. Первая цель для его критики — майндсет в духе я просто решаю инженерные задачи. Многие дата-аналитики считают, что их роль — в улучшении работы существующих цифровых систем. А значит, с их точки зрения, они могут оставаться политически нейтральными.
Как утверждал политолог Гарольд Лассуэлл, политика — это про распределение ресурсов: что, кому, как и где достанется. А анализ данных как раз и определяет, кто и что получит: какие новости покажут в вашем фиде, кого из соискателей возьмут на работу или даже — надевать на задержанных наручники или нет. Поэтому анализировать данные — значит участвовать в политике по определению. И сохранить нейтральность не получится. Как отмечает Грин, оставаться нейтральным — значит, на самом деле, просто поддерживать статус-кво и существующее распределение власти.
Чтобы ответственно подойти к политике анализа данных, дата-инженеры должны внятно сформировать собственное видение общественного блага. Улучшить работу существующих систем — не значит автоматически принести пользу обществу: хотя бы потому, что понимание «пользы» у всех разное. Но если самим не ответить на вопрос о полезном и вредном, то на него ответят за вас.
Из вопроса о благе следуют более конкретные вопросы. Нужно ли вообще техническое решение для той или иной проблемы — или, например, необходимы изменения более высокого уровня? Может быть, нужно совершенствовать не технику, а институты, которые ее используют? Например, можно улучшить прогностические алгоритмы для тюрем. Но что, если стоит задуматься о необходимости тюрьмы в целом?
Вместо того, чтобы анализировать данные для людей, Грин предлагает делать это вместе с ними. То есть следовать принципу ничего о нас без нас. А вместо того, чтобы верить в объективность статистических методов, лучше придумать проект, включающий в себя разные перспективы. А еще можно направить холодный машинный взгляд не на отдельных людей, а на целые институты — например, проанализровать поведение полиции на предмет расовых предрассудков.
Сегодня мы рассказываем об академической статье Грина, в которой он осмысляет политику анализа данных и рассказывает о том, как сделать его более справедливым. Первая цель для его критики — майндсет в духе я просто решаю инженерные задачи. Многие дата-аналитики считают, что их роль — в улучшении работы существующих цифровых систем. А значит, с их точки зрения, они могут оставаться политически нейтральными.
Как утверждал политолог Гарольд Лассуэлл, политика — это про распределение ресурсов: что, кому, как и где достанется. А анализ данных как раз и определяет, кто и что получит: какие новости покажут в вашем фиде, кого из соискателей возьмут на работу или даже — надевать на задержанных наручники или нет. Поэтому анализировать данные — значит участвовать в политике по определению. И сохранить нейтральность не получится. Как отмечает Грин, оставаться нейтральным — значит, на самом деле, просто поддерживать статус-кво и существующее распределение власти.
Чтобы ответственно подойти к политике анализа данных, дата-инженеры должны внятно сформировать собственное видение общественного блага. Улучшить работу существующих систем — не значит автоматически принести пользу обществу: хотя бы потому, что понимание «пользы» у всех разное. Но если самим не ответить на вопрос о полезном и вредном, то на него ответят за вас.
Из вопроса о благе следуют более конкретные вопросы. Нужно ли вообще техническое решение для той или иной проблемы — или, например, необходимы изменения более высокого уровня? Может быть, нужно совершенствовать не технику, а институты, которые ее используют? Например, можно улучшить прогностические алгоритмы для тюрем. Но что, если стоит задуматься о необходимости тюрьмы в целом?
Вместо того, чтобы анализировать данные для людей, Грин предлагает делать это вместе с ними. То есть следовать принципу ничего о нас без нас. А вместо того, чтобы верить в объективность статистических методов, лучше придумать проект, включающий в себя разные перспективы. А еще можно направить холодный машинный взгляд не на отдельных людей, а на целые институты — например, проанализровать поведение полиции на предмет расовых предрассудков.
❤8
Forwarded from метонимический киоск
с коллегами делаем лабораторию о внимании.
интересуют нас, что естественно для художественного контекста, очень разные подходы, от когнитивных исследований и философии до литературоведения и теории искусства; нормативные и ненормативные аспекты, связанные с ними эмоциональные модальности и режимы желания, алгоритмические формы захвата интереса (от weird до кринжа), вопросы признания, навязчивого внимания и способов его избегания, зеттелькастен и "эпистемология поиска".
сначала мы хотели делать лабораторию исключительно внутренней, просто пригласить любимых и уважаемых нами теоретиков помочь нам углубить и расширить интерес. но все же решили приоткрыть встречи (будут лекции, семинары, ридинги) для других заинтересованных исследователей, которых хотели бы собрать через опен-колл.
среди приглашенных спикеров Оксана Зинченко, Катя Колпинец, Катя Крылова, Самсон Либерман, Максим Мирошниченко, Коля Нахшунов и Йоэль Регев.
заявки можно отправлять до 22 сентября включительно
буду безмерно благодарна, если отправите тем, кому это может быть интересно!
интересуют нас, что естественно для художественного контекста, очень разные подходы, от когнитивных исследований и философии до литературоведения и теории искусства; нормативные и ненормативные аспекты, связанные с ними эмоциональные модальности и режимы желания, алгоритмические формы захвата интереса (от weird до кринжа), вопросы признания, навязчивого внимания и способов его избегания, зеттелькастен и "эпистемология поиска".
сначала мы хотели делать лабораторию исключительно внутренней, просто пригласить любимых и уважаемых нами теоретиков помочь нам углубить и расширить интерес. но все же решили приоткрыть встречи (будут лекции, семинары, ридинги) для других заинтересованных исследователей, которых хотели бы собрать через опен-колл.
среди приглашенных спикеров Оксана Зинченко, Катя Колпинец, Катя Крылова, Самсон Либерман, Максим Мирошниченко, Коля Нахшунов и Йоэль Регев.
заявки можно отправлять до 22 сентября включительно
буду безмерно благодарна, если отправите тем, кому это может быть интересно!
❤4
Forwarded from ГРАФДИЗЩ® (Дина)
This media is not supported in your browser
VIEW IN TELEGRAM
[Playground]
Фановый инструмент для быстрой анимации и рандомизации.
Тут можно:
🌟 загружать любые картинки, чтобы с их помощью рисовать или/и анимировать их появление
🌟 рисовать анимированным текстом (только латиницей)
⭐ скачать все это как изображение или как гиф
Все размеры, цвета и скорости можно настраивать, чума!
by nekartinkina #ЩLAB
Фановый инструмент для быстрой анимации и рандомизации.
Тут можно:
Все размеры, цвета и скорости можно настраивать, чума!
by nekartinkina #ЩLAB
Please open Telegram to view this post
VIEW IN TELEGRAM
❤4
Forwarded from Выше квартилей
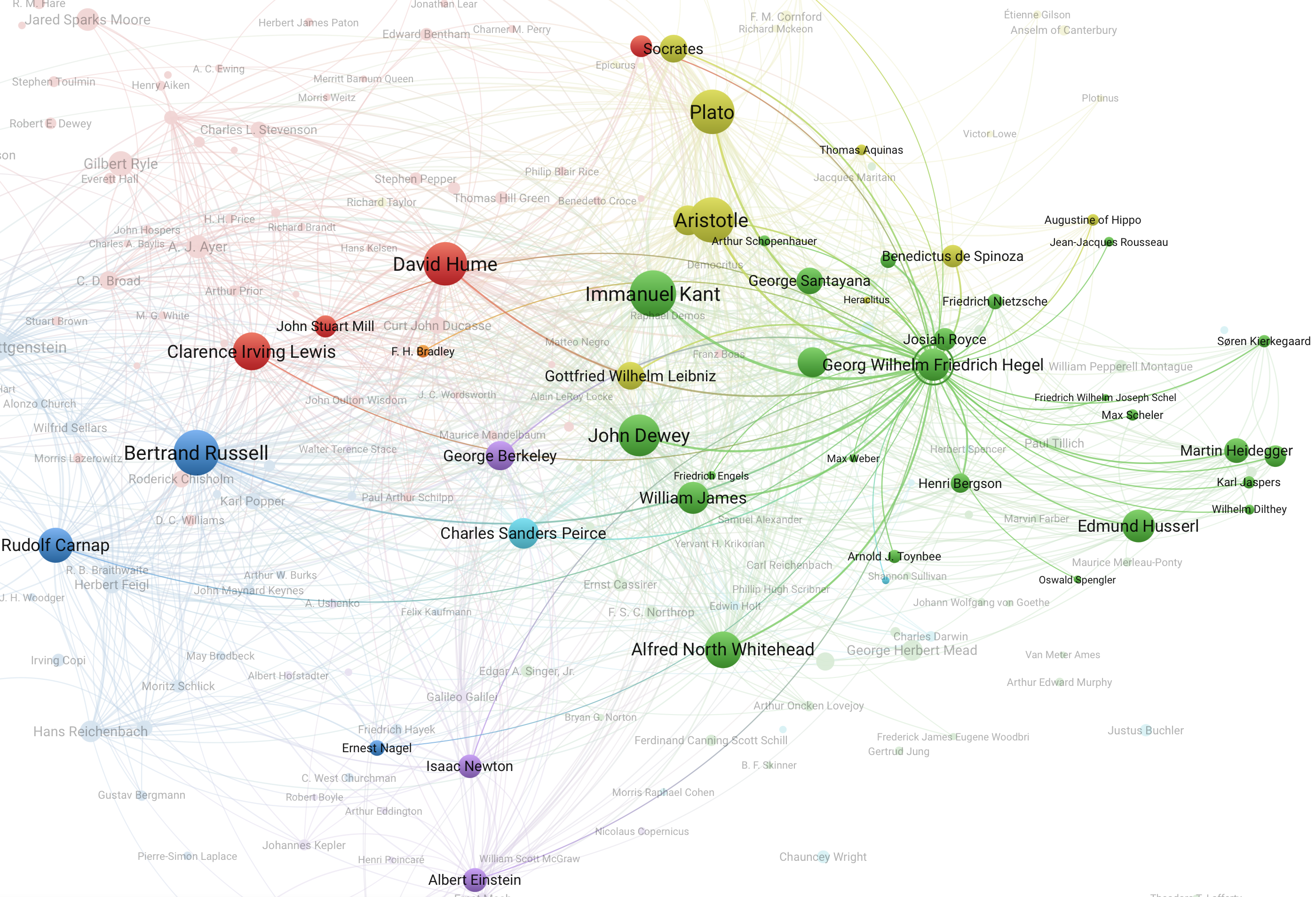
Библиометрия за пределами цитирования: индекс упоминаний
Современные практики цитирования появились относительно недавно, из-за чего научные базы данных сталкиваются с проблемой неполноты учтенных ссылок: например, WoS гарантирует достоверность ссылок лишь с 1980 года, а Scopus — с 1996. При этом ссылки на источники всегда были неотъемлемой частью науки.
В недавней статье ученые из Нидерландов описывают метод, предназначенный для решения данной проблемы — индексирование упоминаний, расширяющее понятие научной ссылки.
Предлагаемый метод состоит из двух основных этапов: текст-майнинг и соотнесение упоминаний с источниками. Авторы ограничили выборку периодом с 1890 по 1979 гг., использовав тексты англоязычной философии. Корпус включает 1 095 765 упоминаний, извлеченных из 22 977 статей в 12 журналах. Распознавание имеет естественные ограничения: например, омонимию фамилий (Рой Вуд Селларс и Уилфред Селларс) — в таком случае учитывается контекст и смежные упоминания. В итоге предложенный алгоритм позволил успешно распознать 93% упоминаний.
При помощи этого метода авторы проанализировали корпус публикаций по философии — дисциплине, где стандартизированные цитаты не использовались вплоть до 1970-х годов, что делает ее удобной областью для демонстрации возможностей нового инструмента.
В статье предлагается несколько кейсов использования индекса. Например, общее число упоминаний персон, сравнение канонов упоминаний в главных англоязычных университетах или изменение трендов упоминаний с течением времени.
В качестве примера одного из кейсов прикладываем к посту скриншот визуализации при помощи VOSviewer сети совместных упоминаний в американских журналах в период с 1950-1959 гг. Интерактивную версию можно посмотреть по ссылке.
Индекс упоминаний стал основой для сервиса EDHIPHY (enriched data for the history of philosophy), на котором размещена база данных упоминаний о философах в журнальных статьях. Авторы предлагают использовать сервис для проведения собственных исследований.
Анализ упоминаний дополняет традиционные методы анализа цитирований, поскольку он применим ко многим историческим периодам и научным областям, где ссылки не имеют форму цитаты. Авторы статьи полагают, что в перспективе анализ упоминаний может быть распространен на всю историю науки.
#обзор #базыданных #индексы #сети
Современные практики цитирования появились относительно недавно, из-за чего научные базы данных сталкиваются с проблемой неполноты учтенных ссылок: например, WoS гарантирует достоверность ссылок лишь с 1980 года, а Scopus — с 1996. При этом ссылки на источники всегда были неотъемлемой частью науки.
В недавней статье ученые из Нидерландов описывают метод, предназначенный для решения данной проблемы — индексирование упоминаний, расширяющее понятие научной ссылки.
Предлагаемый метод состоит из двух основных этапов: текст-майнинг и соотнесение упоминаний с источниками. Авторы ограничили выборку периодом с 1890 по 1979 гг., использовав тексты англоязычной философии. Корпус включает 1 095 765 упоминаний, извлеченных из 22 977 статей в 12 журналах. Распознавание имеет естественные ограничения: например, омонимию фамилий (Рой Вуд Селларс и Уилфред Селларс) — в таком случае учитывается контекст и смежные упоминания. В итоге предложенный алгоритм позволил успешно распознать 93% упоминаний.
При помощи этого метода авторы проанализировали корпус публикаций по философии — дисциплине, где стандартизированные цитаты не использовались вплоть до 1970-х годов, что делает ее удобной областью для демонстрации возможностей нового инструмента.
В статье предлагается несколько кейсов использования индекса. Например, общее число упоминаний персон, сравнение канонов упоминаний в главных англоязычных университетах или изменение трендов упоминаний с течением времени.
В качестве примера одного из кейсов прикладываем к посту скриншот визуализации при помощи VOSviewer сети совместных упоминаний в американских журналах в период с 1950-1959 гг. Интерактивную версию можно посмотреть по ссылке.
Индекс упоминаний стал основой для сервиса EDHIPHY (enriched data for the history of philosophy), на котором размещена база данных упоминаний о философах в журнальных статьях. Авторы предлагают использовать сервис для проведения собственных исследований.
Анализ упоминаний дополняет традиционные методы анализа цитирований, поскольку он применим ко многим историческим периодам и научным областям, где ссылки не имеют форму цитаты. Авторы статьи полагают, что в перспективе анализ упоминаний может быть распространен на всю историю науки.
#обзор #базыданных #индексы #сети
{kind=link}
🔥6❤1
Дата-анализ канонов в англоязычной академии https://pudding.cool/2023/01/lit-canon/
The Pudding
What literature do we study from the 1990s?
The turn-of-the-century literary canon, using data from college syllabi
❤4
Forwarded from RAntiquity (Olga Alieva)
Я тут завела плейлист с занятиями по R у магистров, пока там первые две записи, это четыре пары. Так что желающие могут идти вместе с нами: https://vk.com/video/playlist/91786643_1
Курс, с одной стороны, опирается на то, что я делала в прошлом году, но за лето я существенно переработала первые 16 уроков и сейчас работаю над тем, чтобы добавить к ним еще 16 новых; обновленный handbook по ссылке, но надо иметь в виду, что это пока work очень сильно in progress. https://locusclassicus.github.io/text_analysis_2024/
обновления по тегу #tar2024
Курс, с одной стороны, опирается на то, что я делала в прошлом году, но за лето я существенно переработала первые 16 уроков и сейчас работаю над тем, чтобы добавить к ним еще 16 новых; обновленный handbook по ссылке, но надо иметь в виду, что это пока work очень сильно in progress. https://locusclassicus.github.io/text_analysis_2024/
обновления по тегу #tar2024
locusclassicus.github.io
Компьютерный анализ текста
❤14
Forwarded from Alfa Digital
Декоративное + функциональное = Alfa Design Meetup #3 💥
20 сентября встречаемся офлайн в Санкт-Петербурге на третьем митапе для дизайнеров.
Обсудим редизайн сайта, жизнь с BDUI, подводные камни роли дизайн-менеджера и новые визуальные эстетики. А ещё оценим плакаты от дизайнеров Alfa Digital & Щёлочь Artmercial Games, найдём полезные знакомства и просто почиллим.
Зарегистрироваться на митап можно по ссылке❤️
#анонс
@alfadigital_jobs
20 сентября встречаемся офлайн в Санкт-Петербурге на третьем митапе для дизайнеров.
Обсудим редизайн сайта, жизнь с BDUI, подводные камни роли дизайн-менеджера и новые визуальные эстетики. А ещё оценим плакаты от дизайнеров Alfa Digital & Щёлочь Artmercial Games, найдём полезные знакомства и просто почиллим.
Зарегистрироваться на митап можно по ссылке
#анонс
@alfadigital_jobs
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
❤1
Forwarded from метонимический киоск
сегодня последний день опен-колла в лабораторию о внимании. кстати, помимо перечисленных лекторов, у нас также будут социолог медицины Ася Новкунская, философ Кети Чухров и технотеолог Михаил Куртов. результаты объявим 1 октября
❤3
Forwarded from НКРЯ Национальный корпус русского языка
Приглашаем на вебинар с техническим директором Национального корпуса русского языка!
Завтра, 24 сентября, в 17:00 по московскому времени, технический директор НКРЯ, специалист в области компьютерной лингвистики Дмитрий Морозов проведёт вебинар, посвященный машинному обучению в Национальном корпусе русского языка.
Участники вебинара узнают:
- что такое Национальный корпус русского языка и как начать им пользоваться
- как и для чего применяется машинное обучение в НКРЯ
- чем НКРЯ может быть полезен переводчикам
- как НКРЯ помогает изучать языки народов России
Вебинар организует «Лаборатория перевода» совместно с магистерской программой МИСИС «Цифровая лингвистика и локализация».
Ссылка для подключения к вебинару будет опубликована в телеграм-канале @tradulab в день события. Не пропустите!
Завтра, 24 сентября, в 17:00 по московскому времени, технический директор НКРЯ, специалист в области компьютерной лингвистики Дмитрий Морозов проведёт вебинар, посвященный машинному обучению в Национальном корпусе русского языка.
Участники вебинара узнают:
- что такое Национальный корпус русского языка и как начать им пользоваться
- как и для чего применяется машинное обучение в НКРЯ
- чем НКРЯ может быть полезен переводчикам
- как НКРЯ помогает изучать языки народов России
Вебинар организует «Лаборатория перевода» совместно с магистерской программой МИСИС «Цифровая лингвистика и локализация».
Ссылка для подключения к вебинару будет опубликована в телеграм-канале @tradulab в день события. Не пропустите!
Дорогие коллеги! В ИТМО сейчас проходит конкурс проектов по программе «Приоритет-2030». В конкурсе три направления:
Подробности конкурса можно найти в этом посте.
Команда DH-центра приглашает вас принять участие в брейншторме для разработки идей проектов по направлению «Искусственный интеллект в образовании».
Мы будем рады видеть и слушать всех, кто заинтересован в теме ИИ и готов внести свой вклад в придумывание и развитие проекта.
25 сентября, среда
13:00
DH-центр
Биржевая 16, ауд. 201
Как добраться
Если вы хотите присоеиниться, но у вас нет пропуска в ИТМО, напишите, пожалуйста, Лизе @quiconque_m
До встречи!
upd: Также будет возможность подключиться онлайн! Если вы захотите присоединиться в таком формате, — тоже напишите, пожалуйста, Лизе
Please open Telegram to view this post
VIEW IN TELEGRAM
❤4👍2
прекрасный текст про то, значит ли ИИ, что с нами больше нет интерфейсов и дизайнов: https://networkcultures.org/longform/2024/09/05/algorithms-vs-interactions-the-revenge-of-artificial-intelligence-over-design/#_ftn41
и второй, от прекрасной Амелии Ватенбергер: https://wattenberger.com/thoughts/boo-chatbots
(обратите внимание на вёрстку и её советы про CSS очень дельные, хотя и в соседнем тексте)
и второй, от прекрасной Амелии Ватенбергер: https://wattenberger.com/thoughts/boo-chatbots
(обратите внимание на вёрстку и её советы про CSS очень дельные, хотя и в соседнем тексте)
networkcultures.org
Algorithms vs Interactions: The Revenge of Artificial Intelligence over Design
I don't understand the power of artificial intelligence. Or rather, I wonder why AI overshadows the power of interfaces. We live in a world obsessed with data processing, the resulting “intelligence
Forwarded from Свободный университет
Стипендия для художников и других творческих профессий
По программе Weltoffenes Berlin можно получить финансовую поддержку до 2500€ в месяц. Подающийся должен иметь соответствующее профессиональное образование и работать в искусстве, СМИ или культуре на профессиональном уровне.
Длительность программы — до 12 месяцев, подать заявку нужно до 10 октября.
По программе Weltoffenes Berlin можно получить финансовую поддержку до 2500€ в месяц. Подающийся должен иметь соответствующее профессиональное образование и работать в искусстве, СМИ или культуре на профессиональном уровне.
Длительность программы — до 12 месяцев, подать заявку нужно до 10 октября.
www.berlin.de
Fellowship Program "Weltoffenes Berlin" - Berlin.de
❤3